Обычное видеонаблюдение фиксирует картинку, но бизнесу нужны не архивы, а ответы на вопросы «Кто вошел?», «Когда началась смена?», «Сколько раз за день приезжал транспорт?».
Чтобы дать такие ответы, мы начали делать свою систему видеоаналитики и сразу встали перед выбором: писать всё с нуля или использовать готовые open source инструменты. В итоге за основу взяли открытые библиотеки компьютерного зрения и ML, а поверх добавили свое — пайплайн обработки, личный кабинет, API и интеграции.
Почему мы сделали ставку на open source
В компьютерном зрении почти все базовые задачи уже закрыты open source: детекция объектов, обработка изображений, запуск моделей. Эти инструменты проверены сообществом и позволяют сосредоточиться на реальных сценариях.
Что мы используем:
- YOLO (Ultralytics) — поиск объектов в кадре и потоке; у нас на ней построены модули для людей, авто, лиц, оружия.
- OpenCV — пред‑ и постобработка изображений: декодирование, фильтрация, выделение контуров.
- PyTorch — обучение и запуск моделей, дообучение на наших датасетах.
- NumPy — быстрые операции с массивами данных, используется на всех этапах пайплайна.
Благодаря этому мы экономим месяцы работы и фокусируемся на задачах бизнеса.
Плюсы:
- Прототип модуля собирается за дни.
- Модели можно дообучать под российские номера или конкретные объекты.
- Не нужно платить за лицензии — ресурсы можно направить на доработку сервисов.
Архитектура
Система построена модульно. Каждый сервис работает в отдельном Docker-контейнере, общение идет через API и очереди RabbitMQ. Такой подход позволяет сглаживать пики нагрузки, гарантировать доставку событий и масштабировать отдельные компоненты.
Компоненты:
- Frontend — веб-интерфейс (Vue Vben Admin). Здесь подключаются камеры, настраиваются зоны и модули, отображаются события.
- Backend — хранилище и API. Управляет моделью данных: «кропы» (вырезанные кадры объектов) и «события» (время, камера, результат распознавания). Эти сущности связывают всю аналитику.
- Detection — сервис поиска объектов. Берет видеопоток по RTSP, вырезает объекты и отправляет их кропы в backend.
- Recognize — специализированное распознавание: номера (NomeroffNet, CRAFT, ResNet18), лица (MTCNN, DeepFace, FaceReg).
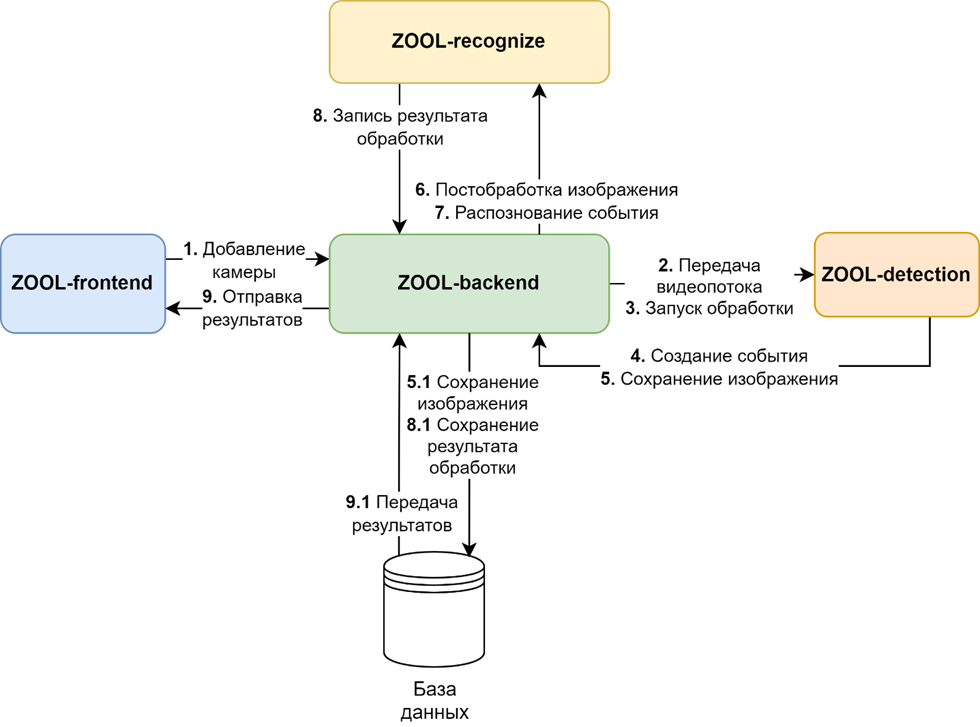
Как работает пайплайн:
- Камера отдает поток H.264 по RTSP.
- Detection находит объекты и формирует кропы.
- Backend сохраняет их и ставит задачу на распознавание.
- Recognize возвращает результат.
- Пользователь видит событие в интерфейсе или получает уведомление.
Зачем нужна модульность
- Можно быстро подключить новый сценарий (например, контроль СИЗ), дообучив модель.
- Detection и Recognize масштабируются параллельно — под разные камеры и задачи.
- Разделение ответственности: интерфейс, хранилище и модули развиваются независимо.
Производительность
На одном сервере (Threadripper PRO + 2× RTX 4090) система держит около 30 RTSP-потоков. Средняя задержка от появления объекта в кадре до события в интерфейсе — меньше секунды. Это ключевой показатель, ради которого мы оптимизировали пайплайн.
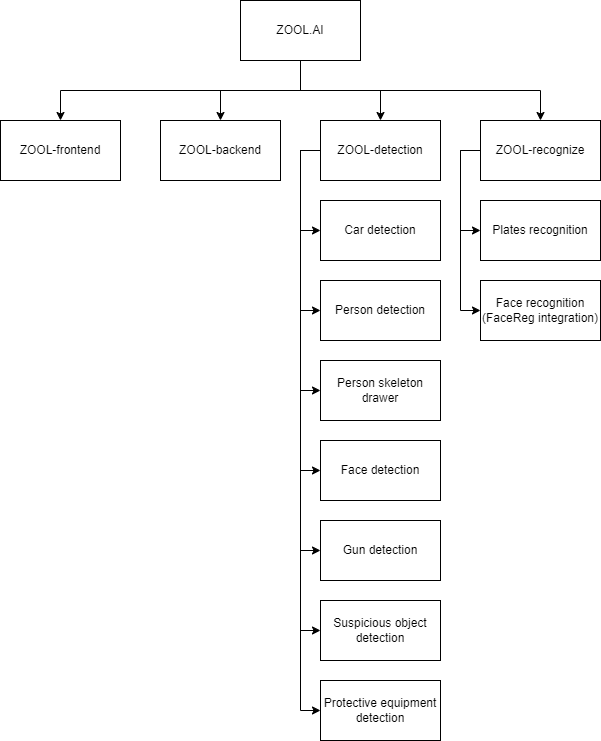
Модель данных
Ядро системы — это события (Event) и кропы (EventPhoto). Каждое событие связано с камерой (Camera), функцией (CameraFunction) и временем. Кроп хранит изображение и результат обработки.
Отдельно ведутся пользователи (User), сотрудники (Employee), регионы (Region), а также настройки функций камеры и пакеты подписок. Такая модель позволяет хранить как «сырые» данные (кропы), так и бизнес-контекст (какой сотрудник, на какой территории, какое событие).
Модули и кейсы применения
Мы строили систему по принципу конструктора: модули можно подключать под разные задачи, они работают на общей архитектуре и обмениваются данными через единый пайплайн.
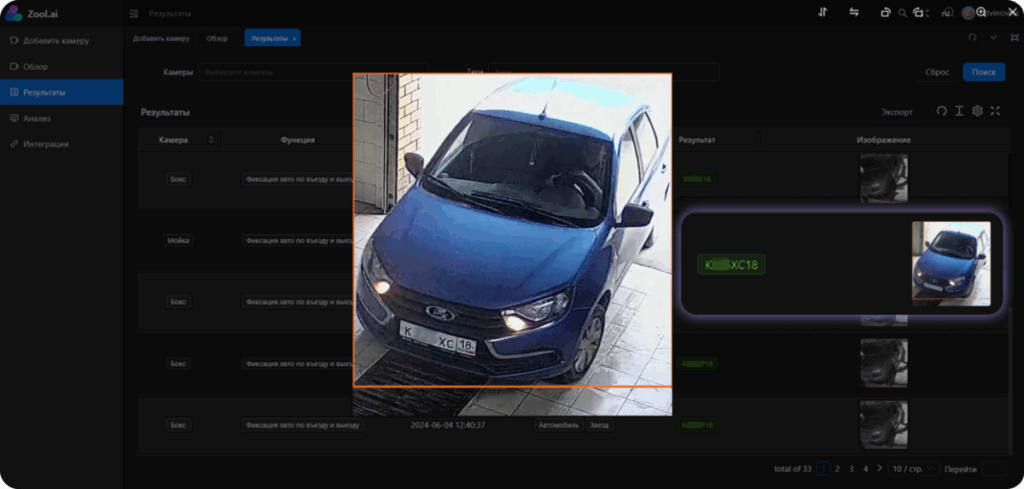
Автомобили. Система отмечает въезды и выезды: сохраняет время, фото и номер машины. Это дает статистику по парковкам и контроль транспорта на промплощадках.
Люди и рабочее время. Камера фиксирует вход/выход или считает, сколько сотрудник провел в зоне — например, у станка. Так можно сверять табель с фактическим временем и понимать загрузку персонала.
Средства защиты. Отдельный модуль проверяет, есть ли каска или жилет. Нарушение фиксируется как событие. Для стройки или производства это способ держать под контролем технику безопасности.
Лица. Обнаружение и идентификация через FaceReg позволяют интегрировать систему со СКУД и автоматизировать доступ. Есть и специализированные сценарии: поиск оружия, обнаружение оставленных предметов.
Все модули построены на YOLO, OpenCV и PyTorch, а точность достигается за счет дообучения на собственных датасетах: более 200 тысяч изображений автомобилей и номеров, отдельные наборы для касок и оружия.
Кейсы применения:
- Завод: контроль транспорта на въезде и проверка касок.
- Офис: вход сотрудников и интеграция со СКУД.
- Склад: учет рабочего времени и СИЗ.
- Парковка: автоматический учет заездов по номерам.
Так система закрывает задачи не только безопасности, но и операционной аналитики.
Нишевые сценарии
Для некоторых отраслей мы используем классические методы CV. Например, метод Харалика помогает находить дефекты на металлических поверхностях. Такой подход применяли в кейсе с контролем изделий из титана. По ссылке можно посмотреть видеоролик, как это выглядит.
Инфраструктура и требования
Для стабильной работы используются:
- Камеры: IP + RTSP (H.264, ≤1 Мбит/с).
- Сервер: многопоточный CPU (Threadripper PRO), ≥128 ГБ RAM, 2× GPU уровня RTX 4090, быстрый SSD.
Мы тестировали и более легкие конфигурации: сервер с одной GPU держит не больше 8–10 потоков.
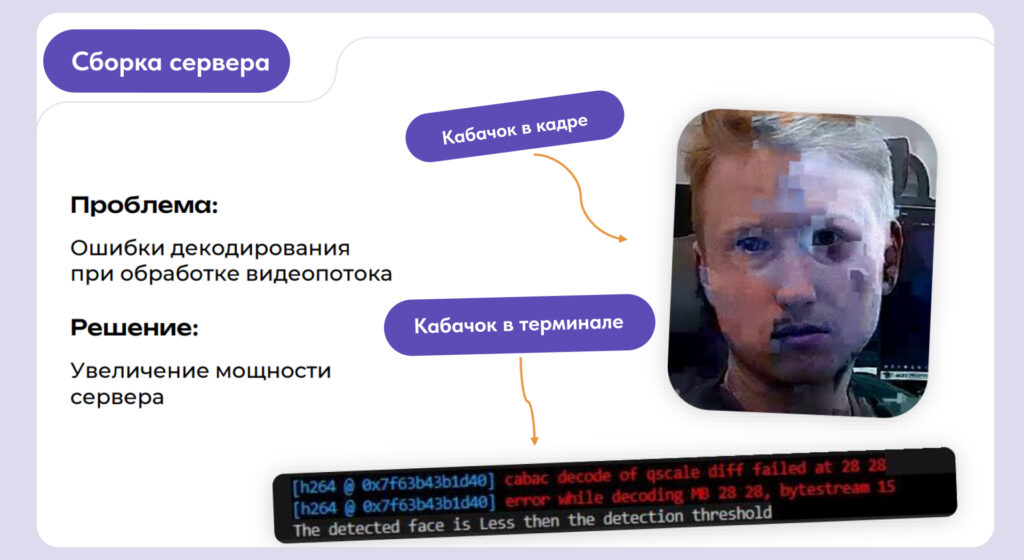
«Ошибка Кабачок»
При первых тестах на слабом сервере мы столкнулись с артефактами и потерей кадров из-за проблем с декодированием видеопотока. Внутри команды эту багу мы в шутку назвали «ошибка Кабачок». Опыт показал: без мощного CPU и двух GPU система нестабильна, поэтому для продакшена мы сразу выбрали Threadripper и RTX 4090.
Минимальная настройка
В config.ini настраиваются:
confidence_ratio— баланс между пропусками и ложными срабатываниями;
class_list— список объектов для поиска (авто, человек, каска);
BoundingBox— расширение рамки, чтобы не обрезать номер.
Интеграции:
- Telegram — уведомления о событиях.
- FaceReg — идентификация лиц.
- Swagger — автодокументация API.
Выводы и уроки
Опыт с zool.ai показал, что ставка на open source оправдана, но не решает всё автоматически.
Где помогло:
- Быстро собрали прототипы на YOLO, OpenCV и PyTorch.
- Сократили расходы на лицензии.
- Получили гибкость — можно дообучать модели под конкретные задачи.
Где пришлось дорабатывать:
- Обучение на собственных датасетах (например, российские номера машин).
- Оптимизация под высокую нагрузку и десятки потоков.
- Настройка пайплайна и параметров, чтобы снизить ложные срабатывания.
Почему гибридный подход лучше. Открытые библиотеки закрывают базовые задачи, а свои сервисы дают управляемость и удобство для бизнеса. Такой баланс позволяет развивать продукт, не завязываясь на одном вендоре и сохраняя контроль над качеством.
Что дальше. Мы планируем расширять модули (например, анализ поведения людей), добавлять новые интеграции и повышать производительность системы при росте числа камер. Кстати, делимся новыми модулями и разработкой продукта в телеграм-канале «AI из Гаража».