В отличие от классической разработки, где unit-тесты и CI/CD давно стали нормой, в Data Engineering тестирование данных всё еще часто ограничивается подходом «проверим на проде». При этом варианты поломок в данных могут быть разные, например:
- меняется схема источника;
- появляются неожиданные null;
- нарушается инвариант агрегации;
- поток сообщений получает несовместимый формат.
Современная data-архитектура выглядит примерно следующим образом:

Проблема в том, что между этими слоями почти нет формальных контрактов. В результате возможны такие ситуации:
- поломка пайплайнов из-за изменения данных на источнике;
- нарушение бизнес‑инвариантов;
- слишком позднее обнаружение ошибок.
Data Contracts: фундамент инженерии данных
Data Contract — это формализованная договоренность между источником и потребителем данных. В качестве источника или потребителя может выступать сервис, команда, приложение, система или ML-модель. То есть в любом месте, где есть обмен данными, может быть применен Data Contract. Простыми словами, это «технический SLA», который описывает, какие данные, в каком формате, с какой гарантией качества и структурой передаются от источника до получателя. Это соглашение о поведении данных во времени, описанное формальным способом, понятным всем участникам процесса обмена данными, по сути, это API для данных.
В современной архитектуре Data Contract содержит следующие основные компоненты:
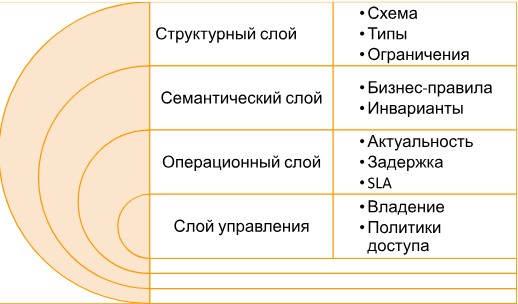
- Структура и схемы (Schema) — какие поля, их типы (string, int, timestamp), обязательность.
- Семантика (Meaning) — что означает каждое поле (например, user_status = ‘active’).
- Качество данных (Data Quality) — требования к свежести, полноте, уникальности (например, user_id не может быть null).
- Надежность данных или SLA (Service Level Agreement) — максимальная задержка доставки, допустимый процент потерянных записей.
- Контроль изменений или версионирование (Versioning) — правила обратной совместимости, сроки поддержки старых версий.
- Владение и ответственность (Ownership) — кто отвечает за источник данных, за исправление ошибок, за коммуникацию.
- Формат и транспорт (Format and services) — как и какими инструментами передаются данные.
- Политика доступа и безопасность (Policy and security) — кто может читать и писать данные, есть ли шифрование, применяется ли маскирование.
В зрелых системах контракт состоит из нескольких слоев:
Когда мы говорим о Data Contract, вопрос формального описания самого контракта становится как нельзя актуальным. И тут невозможно обойти стороной Open Data Contract Standard (ODCS).
Open Data Contract Standard (ODCS) в инженерии данных
Open Data Contract Standard — это открытый машиночитаемый стандарт для описания контрактов данных, оформленных как YAML-документ. Стандарт описывает структуру данных, гарантии качества, SLA, доступ и инфраструктуру публикации данных.
Изначально концепция выросла из шаблона Data Contract, применяемого в PayPal, а сегодня развивается как открытая инициатива сообщества Bitol. Контракт представляет собой описание всей экосистемы обработки данных, включающее такие сферы, как метаданные, схемы данных, правила качества данных, SLA, инфраструктура размещения и связи сервисов, роли и доступы.
Контракт в стандарте ODCS представляет собой YAML-документ, состоящий из нескольких логических разделов. Каждый из них описывает разные аспекты системы обработки и хранения данных: от базовой информации о датасете до правил качества и инфраструктуры хранения. Использование YAML дает возможность перейти к концепции Data Contracts as Code, что позволяет применять к контрактам данных те же самые практики, что и к коду: CI/CD, автоматическую валидацию, версионирование.
Раздел Fundamentals содержит базовую информацию о контракте. Здесь указываются уникальный идентификатор контракта, название датасета или системы, версия контракта, домен или бизнес-область, владелец данных, текущий статус (draft, development, production). Фактически этот раздел выполняет роль паспорта контракта — он помогает понять, что это за набор данных, кто за него отвечает и на какой стадии жизненного цикла он находится. Данный раздел может быть легко связан с архитектурой C4, что позволяет выполнить интеграцию корпоративной архитектуры с физическим уровнем системы.
Раздел Schema описывает структуру данных, которые публикуются по контракту. В нём задаются список полей, типы данных, обязательность полей, ограничения (например, уникальность). По сути, это формальное описание интерфейса данных — аналог структуры API, только для датасетов или потоков событий. Контракт может описывать разные типы схем: табличные структуры, JSON-документы, avro-схемы. Этот раздел используется системами обработки данных для валидации их структуры.
Раздел Data Quality описывает требования к качеству данных и содержит такие проверки, как минимальное или ожидаемое количество строк, допустимый процент пропущенных значений, уникальность ключей, допустимые диапазоны значений, свежесть данных. Эти правила позволяют автоматически проверять, соответствует ли фактический датасет заявленным ожиданиям. На практике такие правила могут быть выполнены инструментами Data Quality, джобами Spark, валидаторами на языке SQL.
Раздел SLA описывает гарантии, которые предоставляет владелец данных. Обычно это частота обновления данных, максимальная задержка доставки, доступность датасета: например, обновление каждые 5 минут, задержка не более 10 минут или доступность 99,9%. Такие параметры особенно важны для команд, которые строят свои системы на основе этих данных.
Раздел Servers описывает, где именно публикуются данные. Контракт может ссылаться на разные типы источников: топики Kafka, таблицы в Lakehouse, базы данных, API-эндпоинты. Таким образом контракт связывает логическое описание данных со своей физической инфраструктурой.
Раздел Roles определяет роли пользователей и команды, которые взаимодействуют с данными. Здесь могут быть описаны владелец данных, команда поддержки, потребители данных, администраторы. Этот раздел позволяет встроить контракт в процессы управления жизненным циклом (Data Governance), управления доступом.
Кроме стандартных полей, контракт может содержать произвольные дополнительные свойства. Они используются для интеграции с конкретными платформами, например системами Data Catalog, инструментами Data Quality, внутренними платформами DataOps. Это позволяет адаптировать стандарт ODCS под особенности конкретной инфраструктуры.
Пример ODCS Data Contract:
```yaml
apiVersion: v3.0.0
kind: DataContract
id: orders_v1
name: Orders dataset
version: 1.0.0
domain: ecommerce
status: production
owner:
name: Data Platform Team
email: data-platform@company.com
schema:
type: table
fields:
- name: order_id
type: string
required: true
unique: true
- name: customer_id
type: string
- name: order_timestamp
type: timestamp
dataQuality:
- type: freshness
threshold: 1h
- type: rowCount
min: 1000
sla:
availability: 99.9%
updateFrequency: 5m
servers:
- type: kafka
topic: orders_events
- type: lakehouse
table: sales.orders
```
Наиболее известный инструмент — консольная утилита datacontract-cli. Предоставляет возможность валидации контрактов, генерации документации и схем (SQL, Avro), проверки наборов данных, интеграции с CI/CD.
Можно рассмотреть применение ODCS в современных архитектурах обработки и хранения данных, например, в таком варианте:
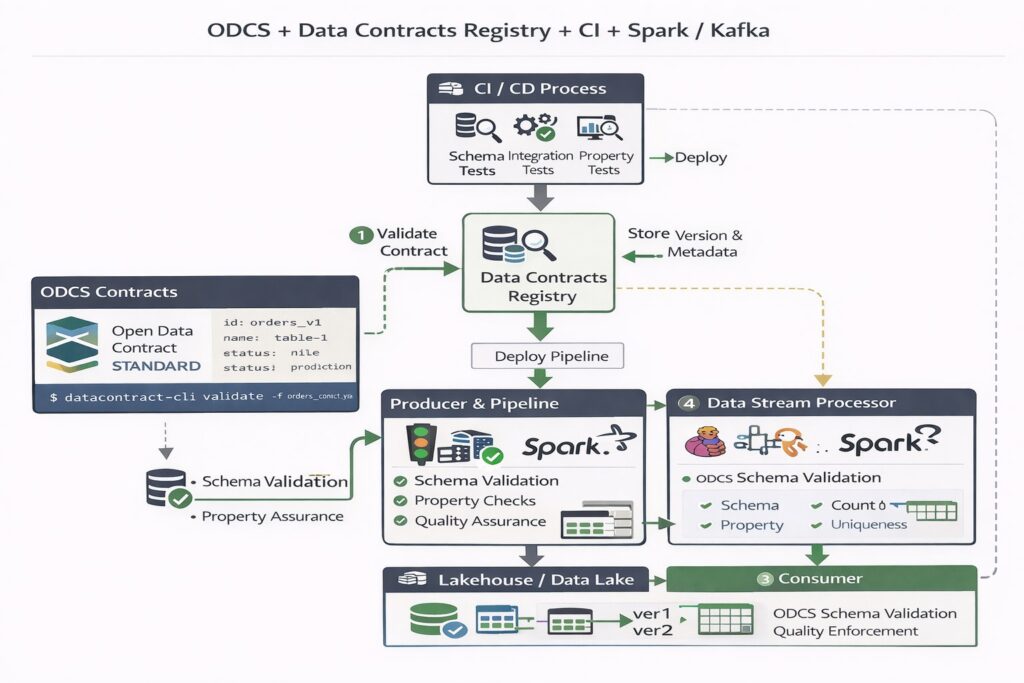
Например, в Spark контракт можно использовать на нескольких уровнях:
Проверка схемы:
```python
contract_schema = load_odcs_schema("orders_contract.yaml")
spark_df = spark.read.parquet("orders")
validate_schema(spark_df, contract_schema)
```
Проверку качества данных можно выполнить по показателям: row count, null ratio, uniqueness.
Архитектурный паттерн может иметь следующее представление:

В случае интеграции с Kafka контракт используется как формальный API события. Producer перед публикацией события выполняет проверку схемы, обязательности полей. Consumer валидирует входящие события против контракта. Реализуется защита от изменения данных на входе и контроль эволюции схем.
Во Flink контракты полезны для проверки на этапе извлечения данных, для контроля за схемами данных на этапах трансформации, для мониторинга качества данных, например, по такому паттерну:

В Lakehouse контракты применяются для управления схемой таблиц, контроля изменений и описания продукта, например, по такому принципу:

При этом контракт может описывать таблицу, SLA на обновление или построение отчетности, допустимые значения, правила качества.
ODCS может быть легко интегрирован с инструментами Data Quality, фактически контракт становится единой декларацией правил качества.
Кроме того, стандарт хорошо вписывается в пайплайны DataOps. Типовой рабочий процесс можно представить так:

Преимущества стандарта:
- формат, удобный для компьютера (Machine-readable Governance), — контракты можно автоматически проверять;
- контракт как код (Data Contracts as Code) — контракты версионируются в Git, для них можно создать редактор;
- унификация экосистемы работы с данными — один формат для потоковой и батчевой обработки, для Lakehouse, баз данных и API;
- совместимость с Data Mesh — ODCS хорошо подходит для разделения ответственности за данные (Data Product Ownership).
Несмотря на преимущества, стандарт еще развивается: он не имеет универсального инструмента для хранения самих данных и реализации для валидации данных на языках, популярных в Big Data, не предоставляет контракт по API и не обеспечивает контроль за эволюцией контракта, требует самостоятельной интеграции с инструментами обработки данных и контроля качества данных.
ODCS — это фактически «OpenAPI для данных». Он превращает датасет или поток событий в формальный API с гарантией схемы, качества и SLA. Но на сегодняшний день отсутствие нативной интеграции с Kafka, Spark, Flink и другими популярными сервисами мира Big Data — это блокирующий фактор для его применения в экосистемах, так как требуется ресурсоемкая разработка на каждом этапе, где есть необходимость взаимодействия со стандартом.
Поговорим о текущих реализациях систем, призванных исполнить роль контрактов данных. И для начала рассмотрим, как обстоят дела в системах потоковой обработки и батчевых инструментах для организации Lakehouse.
Схемы данных в Kafka и контроль за структурой данных в Lakehouse
В архитектурах потоковой обработки данных на базе брокера Kafka контракт может быть зафиксирован в виде схемы Avro/Protobuf. Доступ к нему осуществляется через специальный компонент — Schema Registry. Консьюмер уверен, что данные, полученные из топика, были сериализованы поставщиком данных по схеме, которую предоставил Schema Registry. Данные могут быть корректно десериализованы по указанной схеме. Кроме того, он уверен, что, если схема изменится, она будет следовать правилам эволюции схем. Замечу, что описание схемы не является Data Contract в полном смысле, а лишь охватывает часть его. В общем виде применение схем данных можно отразить следующим образом:
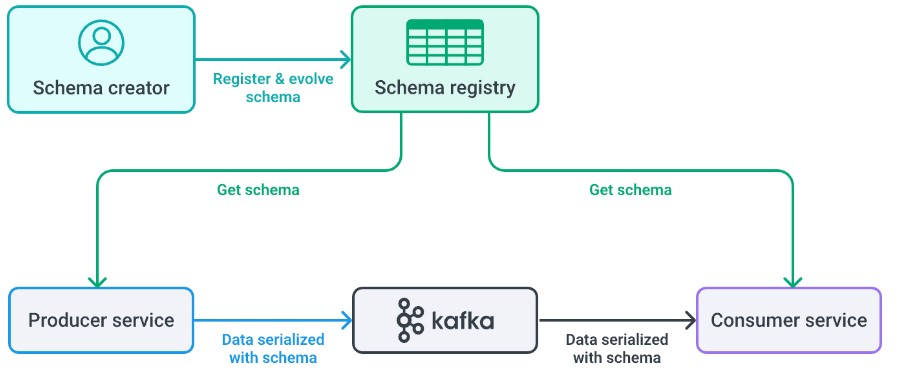
Системы не являются статичными — данные могут быть изменены в любой момент. Именно поэтому важно не только хранить схему, но и управлять ее эволюцией. Обычно выделяют следующие виды совместимости схем данных:
- Backward compatible — новые поля добавляются, старые не ломаются.
- Forward compatible — потребители игнорируют неизвестные поля.
- Full compatible — строгий контроль обеих сторон.
Это особенно критично для таких отраслей, как финтех, ретейл, телеком, например, при обработке банковских потоков транзакций, телеком-событий, ретейл-заказов.
Рассмотрим open source решения для хранения схем данных и управления ими.
Confluent Schema Registry — централизованное хранилище схем для сообщений Kafka. Поддерживает Avro, Protobuf, JSON Schema. Из коробки реализовано версионирование схем, проверка backward/forward/full compatibility, есть REST API для интеграции в CI/CD. Применяется в архитектурах потоковой обработки данных, в системах событийной обработки, в микросервисных экосистемах. Это фактически стандарт де-факто для «контрактов» в kafka-мире.
Apicurio Registry — альтернатива Confluent Schema Registry, совместимая по API. Реализована поддержка Avro, Protobuf, JSON Schema, есть поддержка артефактов API и REST-интерфейс. Преимущество по сравнению с предыдущим хранилищем — возможность хранить схемы данных вне Kafka, например в базе данных или локальном файловом хранилище. Кроме того, из коробки есть веб-интерфейс. Если у вас не применяется Kafka, но вы решили применять схемы данных — это ваш выбор.
Redpanda Schema Registry — встроенный реестр схем, который поставляется как часть платформы Redpanda, полностью совместимый по API с Confluent Schema Registry. Реализована поддержка Avro, Protobuf, JSON Schema. В отличие от отдельных решений, Schema Registry — встроенный компонент самого Redpanda, что исключает необходимость развертывания и обслуживания внешнего сервиса. Преимущества по сравнению с альтернативами — отсутствие внешних зависимостей (например, Zookeeper), единая точка управления в составе кластера Redpanda, а также высокая производительность благодаря нативному коду на C++. Из коробки доступен веб-интерфейс через Redpanda Console. Если у вас уже используется Redpanda или вы рассматриваете переход с Kafka на более современную платформу с меньшими операционными затратами — это ваш выбор. Ключевое отличие от Apicurio в том, что Redpanda не хранит схемы вне кластера — они хранятся внутри самого Redpanda (встроенного хранилища), что упрощает архитектуру, но не позволяет использовать внешние БД или файловые системы как бэкенд. Это компромисс между простотой эксплуатации и гибкостью хранения.
В архитектуре Lakehouse контракты данных играют роль механизма согласования между слоями хранения (Data Lake) и обработки (warehouse/compute). В отличие от классических DWH, где схема данных жестко фиксирована, Lakehouse предполагает более гибкую работу с данными — и именно поэтому контракты становятся критически важными.
В архитектурах, основанных на обработках батчей или наборов датасетов, ключевую роль играют современные табличные форматы, такие как Apache Iceberg, Delta Lake, Apache Hudi. Они фактически становятся технической основой реализации контрактов данных на уровне их хранения. Эти форматы добавляют в Data Lake свойства, которые раньше были характерны только для хранилищ:
- Эволюция схемы (Schema Evolution) позволяет изменять структуру таблиц без разрушения существующих пайплайнов. Можно выполнять добавление новых колонок, изменение типов, переименование полей. С точки зрения Data Contract это означает, что контракт можно расширять без изменений, нарушающих работу существующих потребителей данных (Breaking Changes), изменения становятся управляемыми и предсказуемыми.
- Версионирование данных (Versioning) позволяет фиксировать каждое изменение таблицы как новой версии (snapshot). Это дает возможность отката изменений, воспроизводимость аналитики, аудит изменений. В контексте контрактов можно привязать потребителя к конкретной версии, безопасно тестировать новые варианты схемы.
- ACID-операции гарантируют поддержку атомарности, согласованности, изолированности и долговечности. Не может быть «частично записанных» данных — реализуется корректная работа параллельных процессов, обеспечивается консистентность чтения. Для Data Contract это означает гарантированное соблюдение целостности данных и отсутствие скрытых нарушений контракта из-за записи различными участниками процесса.
Благодаря этим возможностям Lakehouse позволяет реализовать контракт на уровне не только документации, но и самой системы хранения:
- схема становится частью контракта и контролируется платформой;
- изменения проходят через механизм версионирования;
- потребители защищены от неожиданных изменений;
- можно внедрять автоматические проверки совместимости.
Иначе говоря, табличные форматы превращают Data Contract из «договоренности» в конкретную техническую реализацию.
Как я говорил ранее, в мире потоковой обработки (например, с Apache Kafka) роль контракта часто централизована через Schema Registry. В Lakehouse всё устроено более «распределенно»: контракт размазан между форматом таблиц, каталогом (catalog), слоем управления данных и инструментами качества. Но при этом есть вполне конкретный стек open source решений.
Для уровня хранения контракт описан таблицей, физически реализуется в решениях Apache Iceberg, Delta Lake, Apache Hudi. Как контракт они дают контроль эволюции схем, версионирование структуры, обновление схемы при записи, историчность изменений.
Если в потоковой обработке есть Schema Registry, то в Lakehouse его роль играют каталоги. «Реестр контрактов» может быть реализован с помощью Project Nessie, Apache Hive Metastore.
Project Nessie — активно развивающийся проект, он является наиболее близким аналогом Schema Registry в мире Lakehouse. Обеспечивает версионирование (branches, commits), поддерживает изоляцию изменений (dev-/prod-ветки), позволяет провести откат и выполняет контроль эволюции схем и управление ей. Здесь контракт становится версионируемым, готовым к интеграции как код. Сервер Nessie хранит метаданные о версиях и ссылках на физические данные, находящиеся в хранилище объектов. Клиенты взаимодействуют через REST API или SDK (например, для Java или Python), что позволяет интегрировать систему с существующими ETL-процессами.
Но контракт — это не только схема, но и семантика + доступ + происхождение данных (lineage). Мы можем опираться на такие решения, как OpenMetadata, DataHub, Apache Atlas. Они позволят добавить к контракту семантику или описание полей, определить владельца, понять, откуда пришли данные, определить политики доступа. Это делает Data Contract понятным людям, а не только системам.
OpenMetadata позволяет хранить схемы таблиц (при этом есть версионирование) и обладает широкими возможностями по интеграции с другими инструментами. Кроме того, контракт трактуется как часть модели управления данными предприятия, учитывающей схему, владельца системы, наличие SLA и политики. Подходит для Data Mesh и DataOps-подхода.
DataHub — это не только хранение схем/контрактов, но и платформа управления метаданными. Реализованы версионирование схем, хранение истории изменений, управление совместимостью, доступны интеграции с Spark, Kafka, BI. Если контракт рассматривается как часть общей модели управления данными предприятия, то этот сервис может быть вам полезен при построении Lakehouse.
Apache Atlas — это платформа управления метаданными и Data Governance из экосистемы Hadoop. Она ориентирована на централизованное хранение метаданных и управление ими, включая схемы, таблицы, пайплайны и бизнес-термины. Реализованы функции lineage, классификация данных (в том числе чувствительных), политики доступа и интеграции с инструментами обработки данных (Hive, Spark, Kafka). Поддержка версионирования и отслеживания изменений позволяет использовать Atlas как основу для контроля эволюции данных. Если контракт рассматривается как часть корпоративного подхода к управлению данными, включая безопасность и соответствие требованиям, этот сервис может быть полезен в вашей инфраструктуре.
Контракт без проверок — это просто текст. Рассмотрим, кто может выполнить валидацию, проверить, соблюдается ли контракт участниками процесса. Тут нам могут помочь такие решения, как Great Expectations, Soda Core, Deequ. Их роль — проверка схемы и значений, контроль SLA (freshness, completeness) в процессе выполнения, в runtime.
Great Expectations — это фреймворк для тестирования и валидации данных, в котором проверки описываются в виде декларативных «ожиданий» (expectations). Позволяет контролировать соответствие данных контракту: проверка схемы, диапазонов значений, уникальности и полноты. Поддерживает документирование качества данных и интеграцию с пайплайнами (Spark, SQL, Airflow). Хорошо подходит как инструмент runtime-проверки Data Contract.
Soda Core — это легковесный инструмент для мониторинга и тестирования качества данных с использованием SQL-ориентированных правил (SodaCL). Позволяет быстро описывать проверки на уровне таблиц и колонок, отслеживать аномалии и контролировать SLA по данным. Часто используется для встроенного контроля качества в ELT-/ETL-процессах и как часть CI/CD для данных.
Deequ — это библиотека для проверки качества данных на базе Apache Spark, разработанная Amazon. Предоставляет программный API (Scala/Python) для описания правил валидации, профилирования данных и автоматического выявления аномалий. Подходит для крупных обработок датасетов и сценариев, где контроль качества должен быть встроен непосредственно в вычислительные пайплайны.
Контракт должен соблюдаться не только при хранении, но и в вычислениях. Для уровня вычислений можно применять известные решения: Apache Spark, Trino, Apache Flink. В код процессов обработки можно сразу заложить проверку схем при чтении/записи, выполнить интеграцию с Iceberg/Hudi/Delta и тесты качества данных. Здесь контракт становится частью пайплайна.
Таким образом, Lakehouse Data Contract — это не сервис, а композиция табличных форматов, каталогов, управления данными и качеством, слоя вычислений и обработки.
Property-Based Testing для трансформаций
При разработке unit-test обычно ограничиваются набором примеров, которые покрывают область применения функции или метода. Почему фиксированных тестов недостаточно при работе с данными?
Классический тест:
```python
assert transform({"price": 100, "tax": 20}) == 120
```
Он проверяет конкретный кейс. Но что, если:
- tax отрицательный?
- price = None?
- значения экстремальные?
В Data Engineering пространство входных данных огромно и нестатично. Я уже говорил ранее, что системы эволюционируют и, соответственно, меняются данные, поступающие от них. Именно здесь появляется Property-Based Testing (PBT).
Что же такое property-based-тестирование? Давайте разбираться.
Вместо проверки конкретных значений мы проверяем свойства (invariants), например что сумма после агрегации не меняется, количество уникальных ключей сохраняется, даты не уходят в будущее, валютные курсы > 0 и так далее.
Тест автоматически генерирует множество случайных входных данных.
В Python это удобно делать через Hypothesis.
Например, выполним проверку инварианта агрегации. Свойство: сумма по ключам до и после группировки должна совпадать.
```python
from hypothesis import given
import hypothesis.strategies as st
@given(st.lists(st.integers(min_value=0, max_value=100)))
def test_sum_invariant(values):
original_sum = sum(values)
aggregated_sum = sum(values) # имитация трансформации
assert original_sum == aggregated_sum
```
В Spark-среде property-подход реализуется через декларативные проверки, например, с использованием Deequ. Тут надо сразу отметить, что Deequ — это не генератор тестовых данных (как Hypothesis), а движок декларативных проверок свойств (constraints) над большими датафреймами.
Именно поэтому PBT в Spark + Deequ выглядит примерно следующим образом: сначала формулируется описание инвариантов (properties), далее генерируется или подается набор входных данных и проверяется, что свойства всегда выполняются.
Рассмотрим PBT для агрегации в Spark + Deequ на практическом примере.
Допустим, у нас есть следующий пайплайн:
1. Загружается таблица транзакций:
```
user_id | amount | currency
```
2. Выполняется агрегация:
```
group by user_id -> sum(amount)
```
Описываем инварианты (properties):
- Общая сумма
amountдо и после агрегации должна совпадать. - Количество уникальных
user_idпосле агрегации равно количеству уникальныхuser_idдо. - Все агрегированные суммы ≥ 0.
- Не должно появляться
null.
Это и есть свойства, которые мы будем тестировать во время проверки.
Реализация на Spark + Deequ (Scala) выглядит следующим образом:
```scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import com.amazon.deequ.checks._
import com.amazon.deequ.VerificationSuite
import com.amazon.deequ.VerificationResult
val spark = SparkSession.builder()
.appName("PBT-Deequ-Example")
.master("local[*]")
.getOrCreate()
import spark.implicits._
```
Вместо одного фиксированного набора генерируем разные данные:
```scala
val data = Seq(
(1, 100.0, "RUB"),
(1, 50.0, "RUB"),
(2, 200.0, "RUB"),
(3, 0.0, "RUB")
).toDF("user_id", "amount", "currency")
```
В продвинутом варианте можно генерировать данные случайно или через фреймворк и передавать в Spark.
Допустим, у нас будет следующая трансформация:
```scala
val aggregated = data
.groupBy("user_id")
.agg(sum("amount").alias("total_amount"))
```
Проверка инвариантов через Deequ.
Property 1: суммы до и после совпадают. Пример кода:
```scala
val originalSum = data.agg(sum("amount")).first().getDouble(0)
val aggregatedSum = aggregated.agg(sum("total_amount")).first().getDouble(0)
assert(originalSum == aggregatedSum)
```
Это property-test на логичное поведение пайплайна.
Property 2–4: декларативные проверки через Deequ могут быть реализованы, например, вот так:
```scala
val check = Check(CheckLevel.Error, "Aggregation invariants")
.isComplete("user_id") // нет null
.isComplete("total_amount") // нет null
.isNonNegative("total_amount") // >= 0
.hasSize(_ > 0) // датафрейм не пуст
```
Запуск проверки:
```scala
val result = VerificationSuite()
.onData(aggregated)
.addCheck(check)
.run()
assert(result.status == com.amazon.deequ.VerificationResult.Status.Success)
```
Где же здесь property-based-подход? Он заключается в том, что проверяются свойства, а не конкретные значения:
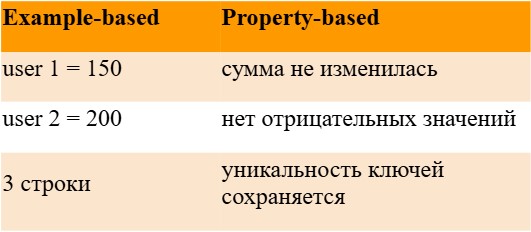
Добавим генерацию данных для проверки трансформаций и сделаем эти проверки в цикле:
```scala
for (i <- 1 to 100) {
val randomData = generateRandomDataset(spark)
val transformed = transform(randomData)
verifyInvariants(randomData, transformed)
}
```
Где verifyInvariants содержит:
- проверку суммы,
- уникальности,
- декларативные Deequ constraints.
Это уже полноценный property-based стресс-тест пайплайна.
Рассмотрим пример бизнес-инварианта. Допустим, что после дедупликации по transaction_id количество строк не превышает исходного количества и сумма не увеличивается:
```scala
Check(CheckLevel.Error, "Dedup invariant")
.hasSize(_ <= originalCount)
.isNonNegative("amount")
```
Возможности Deequ позволяют перейти к аппроксимациям метрик:
```scala
.hasApproxQuantile("amount", 0.5, _ > 0)
```
Это уже property уровня распределения данных, а не просто проверки типа.
PBT будет полезен при тестировании дедупликации, оконных функций, сложных join, расчетов метрик, при CDC-процессах. PBT позволяет выявить edge-cases до продакшена.
Data Quality как непрерывный процесс
В пайплайнах контракт — это входной контроль, тесты до внедрения пайплайна — это защита логики. Но данные могут портиться уже в проде. И здесь подключается data-quality-мониторинг.
Обычно выделяют следующие ключевые измерения качества данных:
- Completeness — заполненность полей.
- Uniqueness — отсутствие дубликатов.
- Consistency — соблюдение бизнес-правил.
- Freshness — своевременность загрузки.
- Validity — соответствие допустимым диапазонам.
Можно применять ранее упомянутые инструменты, такие как Great Expectations, OpenMetadata, DataHub. Многие компании интегрируют встроенные DQ-механизмы в ETL, добавляют слой правил поверх Spark, реализуют собственные фреймворки контроля схем.
При импортозамещении популярна стратегия, когда применяется open source вместе с собственной обвязкой контроля данных, внедрение Schema Registry в корпоративный контур, интеграция DQ в CI/CD.
Интеграция контрактов в CI/CD и DataOps
Можно выделить разные подходы к организации интеграции контрактов. Рассмотрим подход, основанный на контракте, включающий следующие элементы:
- Описывается контракт.
- Проверяется совместимость.
- Только после этого формируется источник данных, пайплайны обработки, слои хранения.
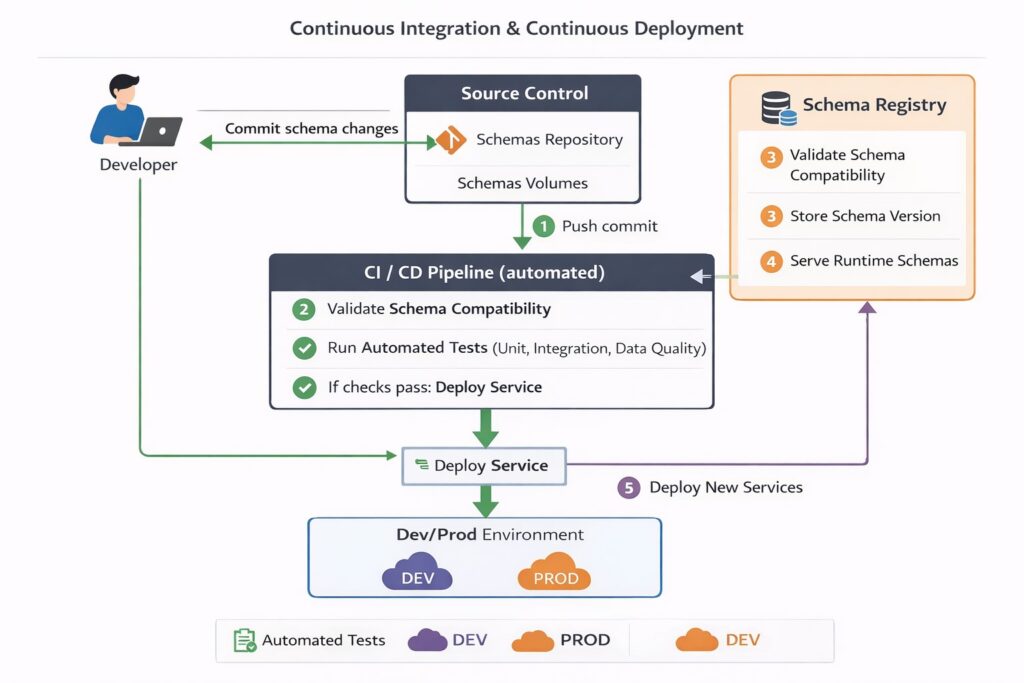
Контракт хранится в Git. Проверка совместимости — в CI. Нарушение — блокирует merge. После проверки контракт помещается в Registry либо к нему обеспечивается доступ через другие способы.
Следующий подход — Test-Driven Data Pipelines, в котором можно выделить минимальный набор тестов: unit-тесты трансформаций, property-based-тесты, проверку схем, интеграционные тесты с тестовым датасетом, DQ-проверки на уровне стейджинговых данных.
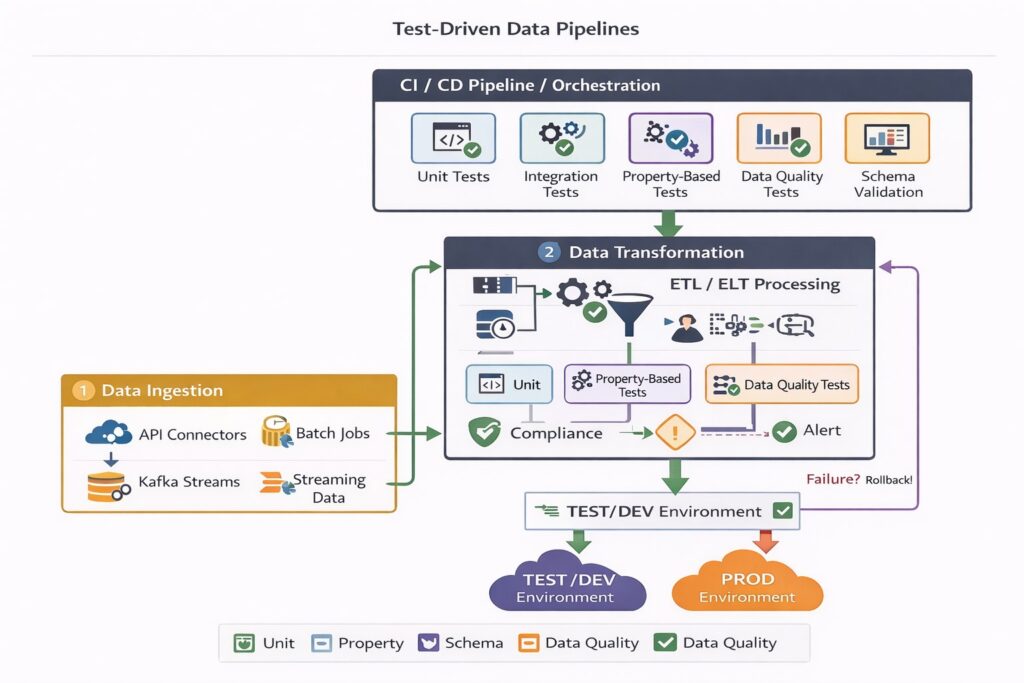
Кроме того, легко реализуемый подход — защита от порчи данных, при котором основными элементами являются:
- canary-загрузка — постепенное и безопасное внедрение изменений в пайплайн обработки данных;
- автоматический откат при нарушении SLA;
- оповещение при превышениях метрик качества;
- версионирование таблиц (lakehouse-подход).
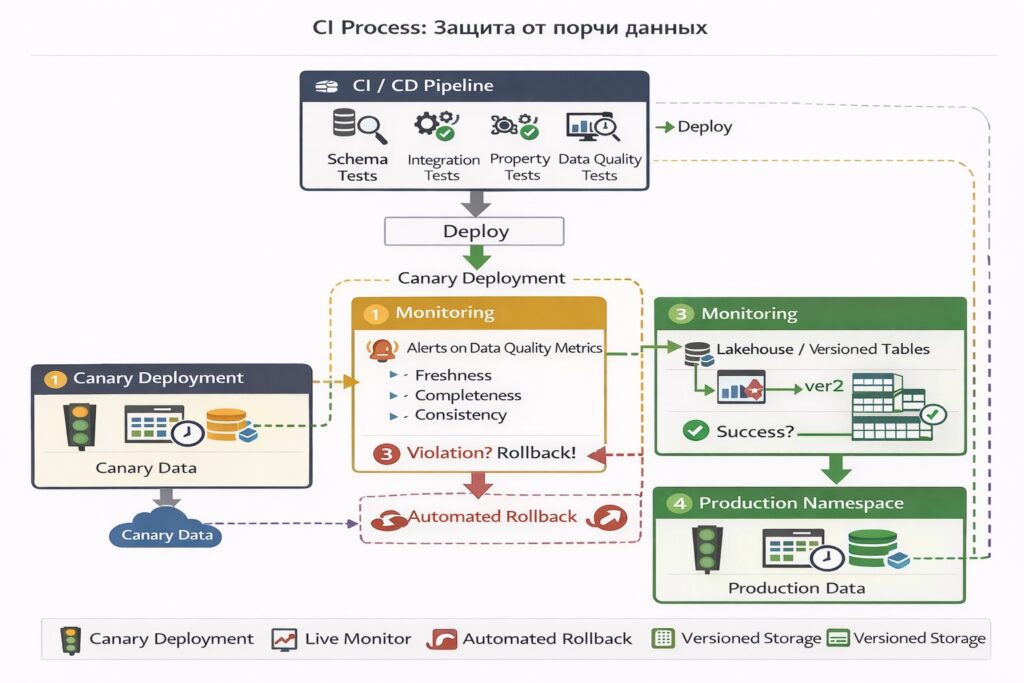
Мы рассмотрели общее описание контрактов данных, прошлись по технологиям в потоковой и пакетной обработке, увидели, как обеспечивать контракты в Lakehouse, говорили о тестах и подходах CI/CD.
Заключение
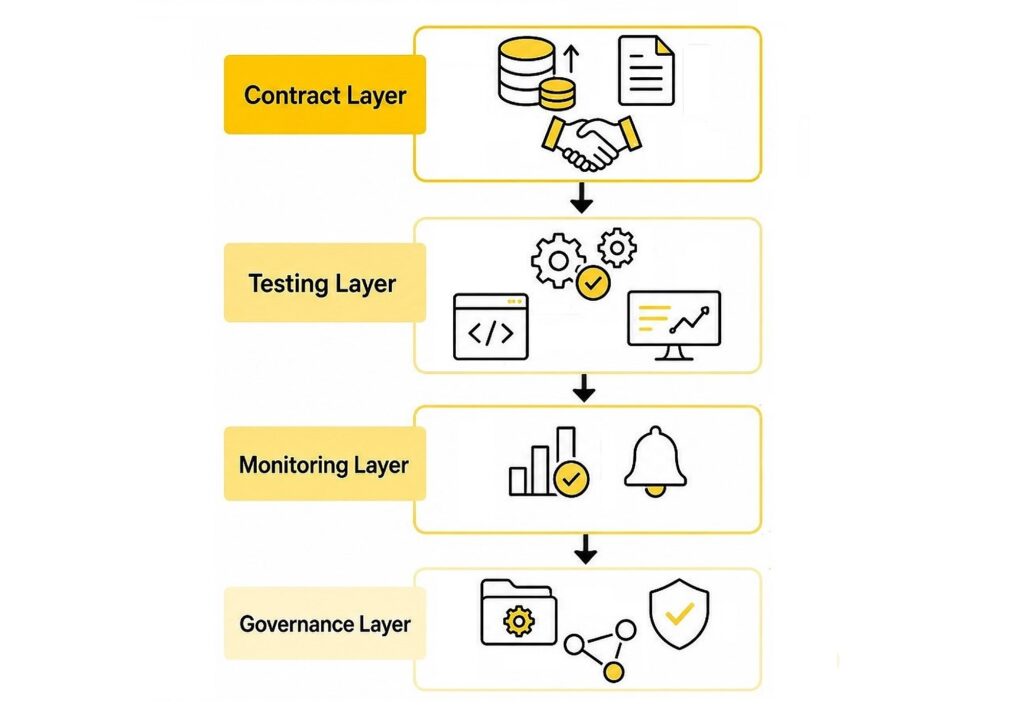
Современный стек обработки данных должен включать:
- Контрактный слой — схемы, системы хранения и контроля эволюцией (registry), версионирование.
- Тестовый слой — классические unit-тесты, PBT, валидации схем.
- Слой мониторинга — DQ-метрики, системы оповещений и алерты, дашборды.
- Слой управления данными — каталог, эволюция данных, SLA.
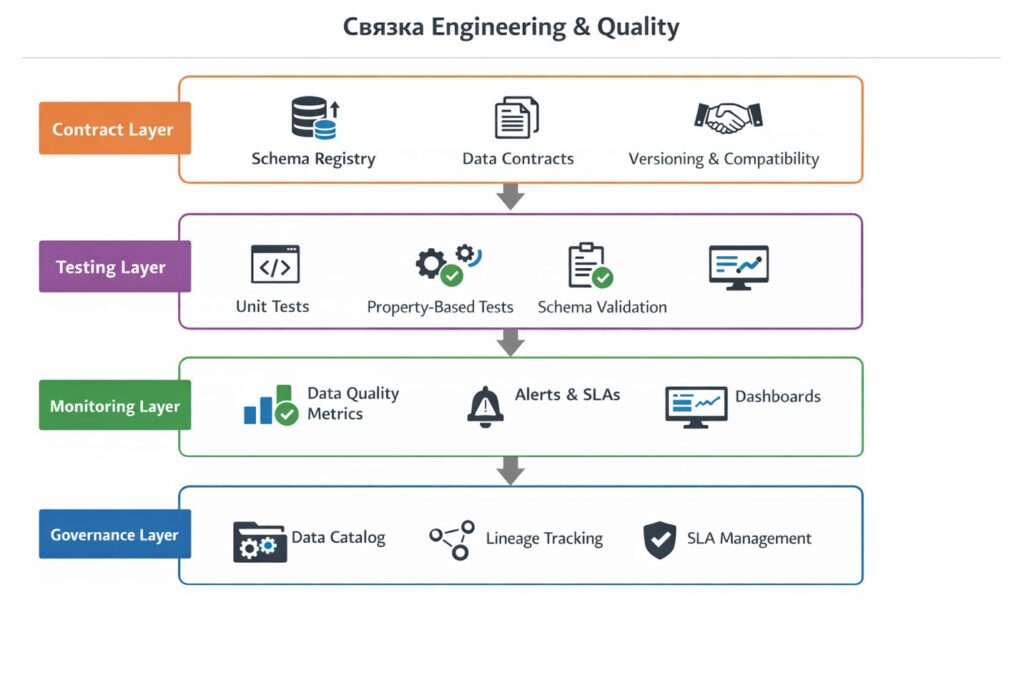
Это и есть зрелая модель DataOps. Конечно, при реализации требуется в первую очередь оценивать необходимость и ресурсоемкость внедрения каждого из этапов.
Тестирование и описание данных, внедрение метаданных над данными — это не дополнительная активность, а необходимый уровень зрелости современной платформы обработки данных, важная часть Data Engineering. Каждый компонент позволяет закрыть большой список возможных рисков:
- Data Contracts → защищают интерфейс данных;
- property-based-тесты → защищают логику трансформаций;
- data-quality-мониторинг → защищает продакшен.
В российских реалиях, где активно развивается импортозамещение и растет потребность в on-premise-инфраструктурах для задач Big Data, именно системный подход к качеству данных становится конкурентным преимуществом.
Данные должны быть не просто доступными — они должны быть предсказуемыми, проверяемыми и управляемыми. И это уже зона ответственности архитекторов и инженеров данных.