Задача
Принимаем данные по платежам. Нужно найти дубли среди миллиона записей в PostgreSQL. Запись — 10 полей: номер, дата, сумма, контрагент, назначение, БИК, счет, ИНН, КПП, валюта.
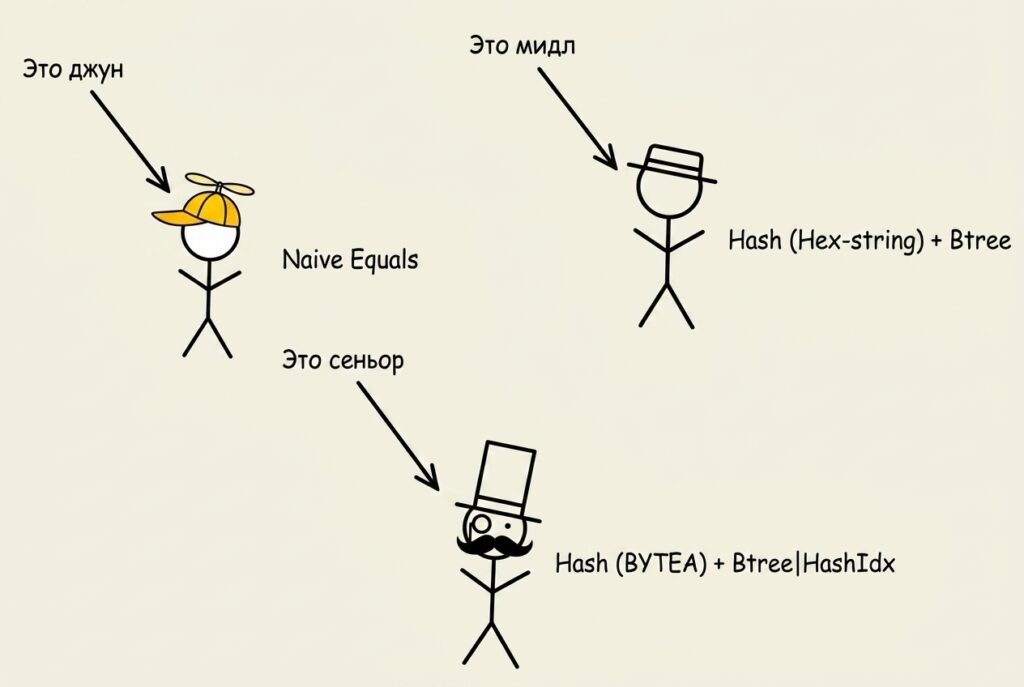
Джун: «Сравню все поля»
Идея
Для каждого входящего платежа проверить, есть ли в таблице строка с такими же значениями всех полей.
SELECT * FROM payments
WHERE number = 'PAY-0000001'
AND date = '2024-01-15'
AND amount = 15420.50
AND counterparty = 'ООО Ромашка'
AND purpose = 'Оплата по договору №123'
AND bank_bic = '044525225'
AND account = '40702810100000000001'
AND inn = '7707083893'
AND kpp = '773601001'
AND currency = 'RUB';
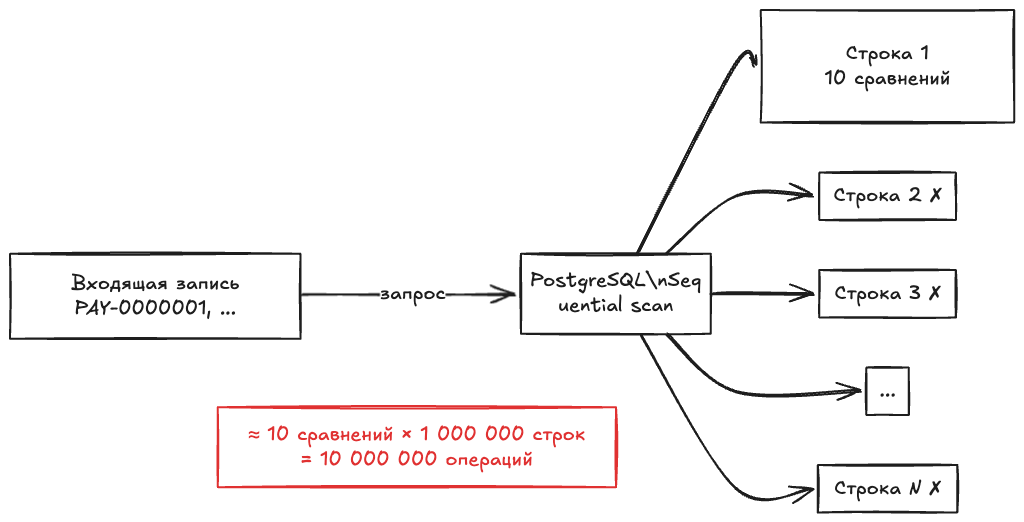
На маленьких таблицах — нормально: PostgreSQL делает sequential scan, проверяет каждую строку. На ста записях — мгновенно, никаких проблем.
Когда это сломается?
Если нет индекса, то каждая проверка — full scan по всей таблице. На каждой строке — сравнение N полей. Для 1М записей по десяти полям: каждый входящий запрос сканирует миллион строк, на каждой сравнивая десять значений. Строковые сравнения — посимвольные, и чем длиннее строки, тем дороже.
Если есть индекс — уже лучше, но теперь растут его размер и цена вставки в БД.
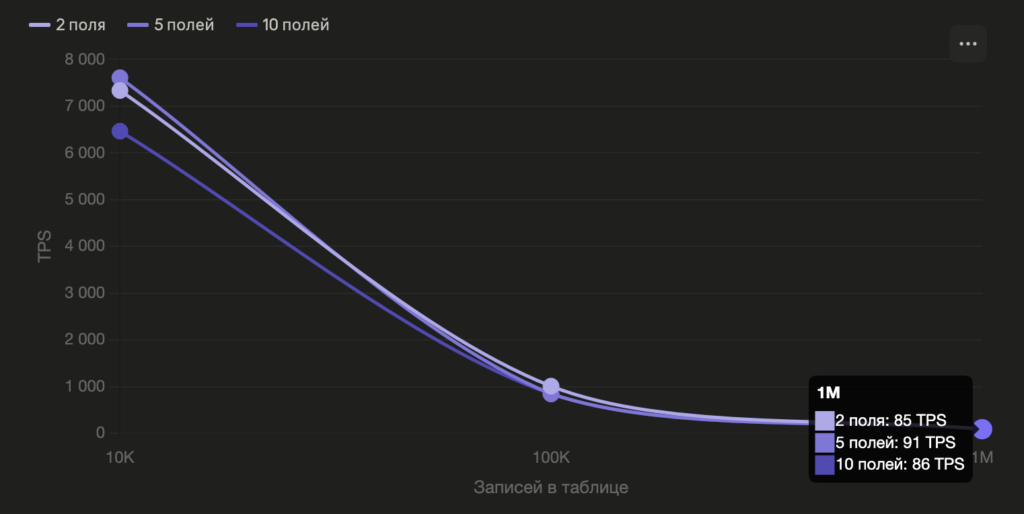
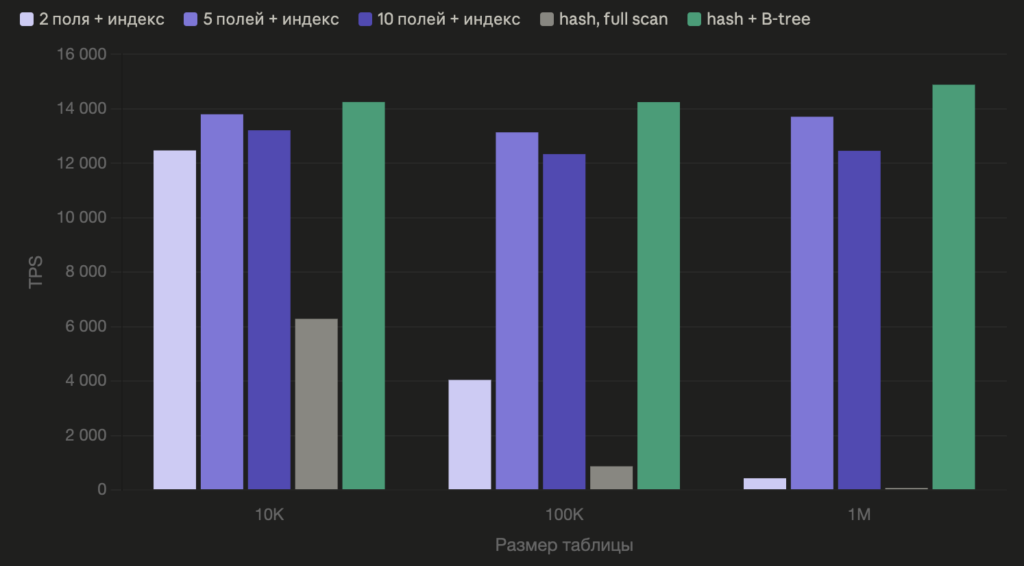
Вот как деградирует производительность в зависимости от количества полей (Transactions Per Second):
Мидл: «Добавлю хеш»
Итак, мы поняли, что сравнивать десять полей по каждой строке дорого. Как сделать дешевле? Схлопнуть все десять полей в одно значение.
Идея
При вставке записи вычислить SHA-256 по всем полям, сохранить в отдельную колонку. При проверке — считать хеш входящей записи и искать по одному полю вместо десяти.
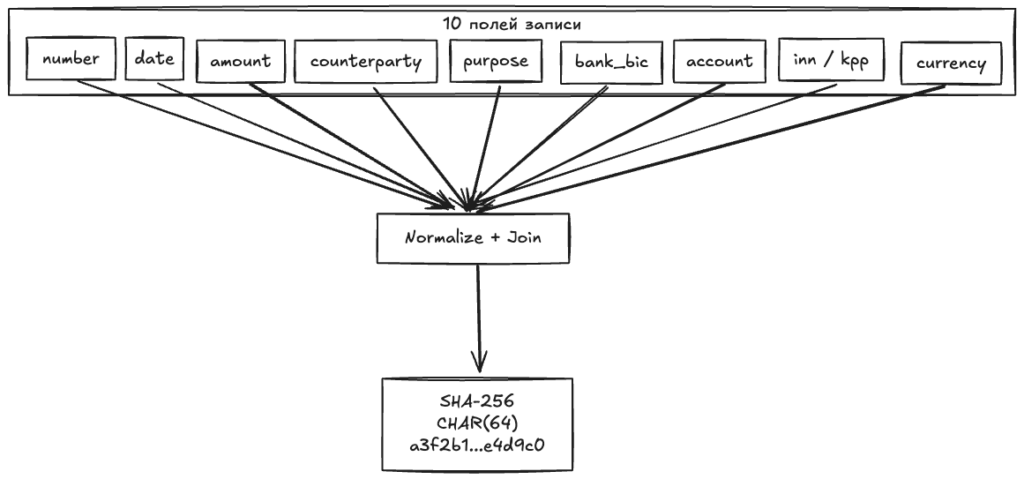
Нормализация
Прежде чем считать хеш, все поля нужно привести к единому формату. Одна и та же запись даст разные хеши:
- Из-за пробелов: «ООО Ромашка » vs «ООО Ромашка».
- Регистра: PAY-0000001 vs pay-0000001.
- Формата дат: Excel может отдать дату как OLE Automation Date (число), C# — как 2024-01-15, БД — как 15.01.2024.
- Суммы: 100 vs 100.00 vs 100,00.
- Отсутствия разделителя: без разделителя 100 + 500 и 1005 + 00 дадут одинаковую строку, хотя данные разные.
Пример нормализации и хеширования:
static string NormalizeAndHash(PaymentOrder order)
{
var raw = string.Join("|",
order.Number.Trim().ToUpperInvariant(),
order.Date.ToString("yyyy-MM-dd"),
order.Amount.ToString("0.00", CultureInfo.InvariantCulture),
order.Counterparty.Trim().ToUpperInvariant(),
order.Purpose.Trim().ToUpperInvariant(),
order.BankBic.Trim(),
order.Account.Trim(),
order.Inn.Trim(),
order.Kpp.Trim(),
order.Currency.Trim().ToUpperInvariant());
return Convert.ToHexString(SHA256.HashData(Encoding.UTF8.GetBytes(raw)));
}
Реализация
ALTER TABLE payments ADD COLUMN dedup_hash CHAR(64) NOT NULL;
CREATE INDEX ix_payments_hash ON payments (dedup_hash);
SELECT * FROM payments WHERE dedup_hash = 'A3F2B1...';
Даже без индекса уже лучше: full scan по-прежнему, но сравниваем один CHAR(64) вместо десяти разнородных полей. С индексом B-tree убирает full scan полностью. Поиск за O(log N) — 3–4 чтения страниц вместо миллиона строк. Строковый хеш с индексом дает стабильные 14к TPS на любом количестве записей.
Задача выполнена, можно закрыть тикет и пойти пить кофе.
Сеньор: тонкости и нюансы
Размер хеша
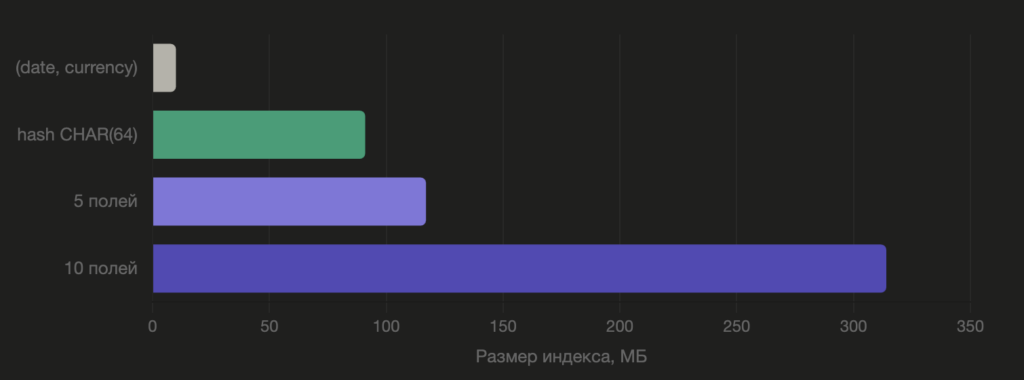
Индекс в формате CHAR занимает в два раза больше места, чем нужно.
SHA-256 — это 32 байта. ToHexString превращает их в 64 символа: каждый байт записывается двумя hex-символами. Данных столько же, но представление вдвое длиннее: мы храним 64-байтные строки вместо 32-байтных ключей.
Как это влияет на индекс?
Страница индекса в PostgreSQL — 8 КБ. Чем крупнее ключи, тем меньше их влезает на одну страницу:
- CHAR(64): ~100 ключей на страницу.
- BYTEA(32): ~170 ключей на страницу.
Больше ключей на страницу → меньше страниц в индексе → меньше IO → больше индекса помещается в кеш.
На миллионе записей разница в размере индекса — примерно 80 МБ vs 45 МБ, то есть почти в два раза меньше.
Реализация
Меняем тип колонки и убираем конвертацию в hex:
-- было
dedup_hash CHAR(64) NOT NULL
-- стало
dedup_hash BYTEA NOT NULL
// было: байты -> hex-строка
var hash = Convert.ToHexString(SHA256.HashData(bytes));
// стало: байты -> в БД как BYTEA напрямую
var hash = SHA256.HashData(bytes);
Текстовые строки в PostgreSQL сравниваются через strcoll() с учетом collation (локали). Для hex-строк это бессмысленная работа — никакая локаль тут не нужна.
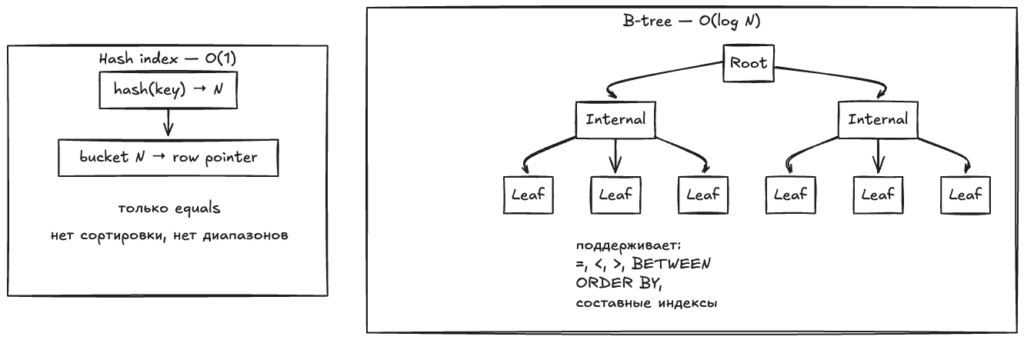
Hash-индекс вместо B-tree
Для оптимизации работы индекса можно использовать hash-индекс вместо стандартного B-tree:
CREATE INDEX ix_payments_hash ON payments USING hash (dedup_hash);
Hash-индекс не поддерживает range-запросы и сортировку, но для equality-поиска по хешу они и не нужны.
При таком подходе размер индекса падает до 32 МБ, а TPS слегка увеличивается — до 14 800 транзакций в секунду.
Детали бенчмарка
Окружение. PostgreSQL 16 в Docker, tmpfs вместо диска, shared_buffers = 128 МБ — осознанно маленький, чтобы разница в размере индексов проявлялась через cache misses.
Данные. Таблица платежей: number, date, amount, counterparty, purpose, bank_bic, account, inn, kpp, currency + колонка dedup_hash CHAR(64). Три копии: 10К, 100К и 1М записей. Данные в меньших таблицах — подмножество большей. Генерация через generate_series с фиксированным setseed(0,42) для воспроизводимости.
CREATE TABLE payments (
id BIGSERIAL PRIMARY KEY,
number VARCHAR(20) NOT NULL,
date DATE NOT NULL,
amount NUMERIC(15,2) NOT NULL,
counterparty VARCHAR(200) NOT NULL,
purpose VARCHAR(500) NOT NULL,
bank_bic VARCHAR(9) NOT NULL,
account VARCHAR(20) NOT NULL,
inn VARCHAR(12) NOT NULL,
kpp VARCHAR(9) NOT NULL,
currency VARCHAR(3) NOT NULL,
dedup_hash CHAR(64) NOT NULL
);
Нагрузка. pgbench, 10 соединений, 4 потока, 60 секунд на замер. Перед каждым замером — прогрев 15 секунд (чтобы shared_buffers наполнился) и сброс статистики через pg_stat_reset().
Итог
На миллионах записей и тысячах RPS каждый лишний байт в индексе и каждое сравнение имеют цену. Проектируйте системы с учетом нефункциональных требований.
Кроме того, подписывайтесь на мой телеграм-канал Flexible Coding, где я рассказываю о своем опыте в программировании.