Первоначальная архитектура
Команда разработки состояла в разные периоды из 3–5 человек, проект писали несколько лет, в течение которых менялись взгляды на архитектуру и концепцию в целом. Отдельные части переписывали, менялась команда. В итоге к началу пандемии код проекта был достаточно рыхлый и не всегда выверенный в плане оптимальности. Когда нагрузка выросла, в коде были классы, методы и даже бандлы, назначение которых команда не вполне понимала.
Cайт был написан на PHP-фреймворке Symfony 3, без четкого разделения на фронт и бэк. Веб-интерфейсы рендерили с помощью шаблонизатора Twig, для интерактива использовали преимущественно JQuery. В качестве СУБД была PostgreSQL 9.6, а часть данных по инициативе разработчиков кешировалась в NoSQL СУБД Redis. На сайте был API для загрузки и многоэтапной обработки нового контента, для этого была выстроена система очередей на двух брокерах RabbitMQ.
Проект располагался на 16 физических серверах, фронтенды и бэкенды — по 24 ядра и 128 ОЗУ каждый, ноды СУБД имели 56 ядер и 512 ГБ ОЗУ. В каждом сервере было по четыре 10-гигабитных сетевых интерфейса, которые давали агрегированный канал шириной 40 Гбит. На нодах стояли жесткие диски по 2 ТБ с установленной ОС, а на бэкенд-нодах дополнительно располагался код PHP/Symfony. Разделяемые ресурсы, такие как изображения, видео и загружаемые файлы, которые требовались на всех нодах, хранились в СХД и монтировались к каждой ноде в виде сетевых шар NFS.
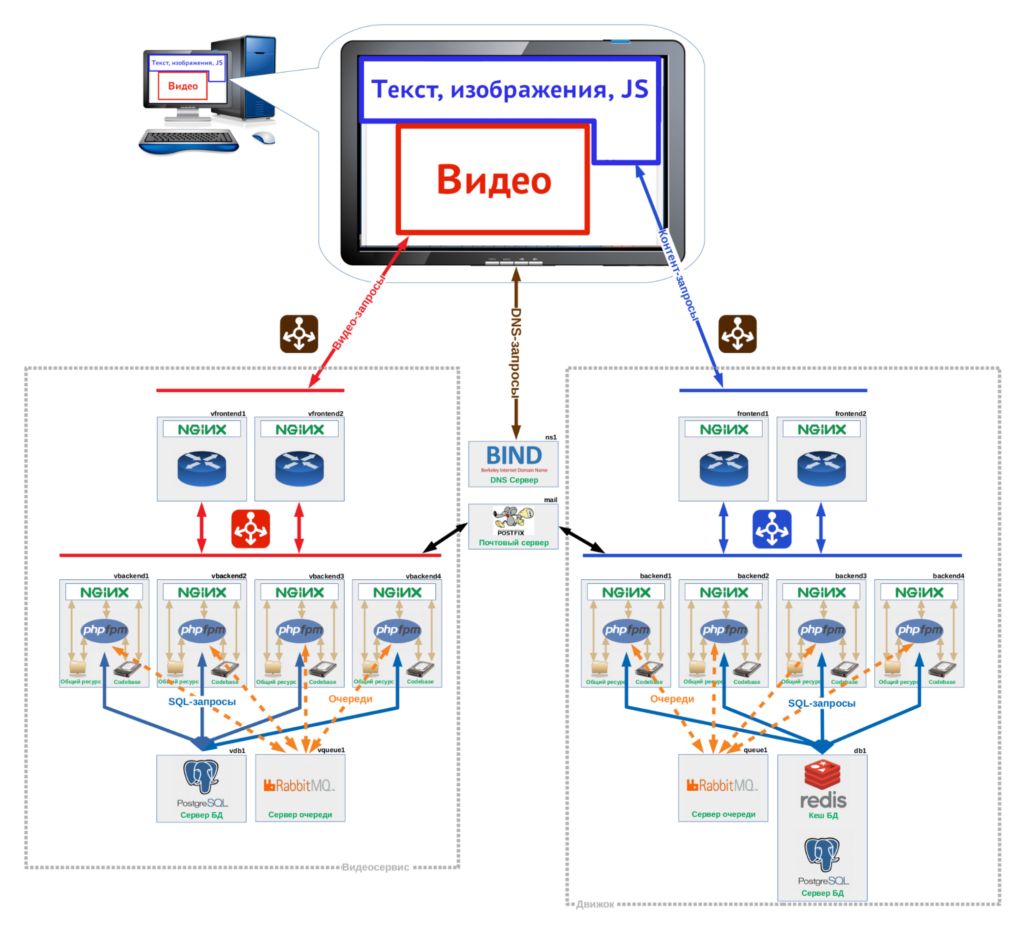
В первоначальной архитектуре уже были заложены некоторые идеи для работы в условиях высоких нагрузок.
Например, проект был разделен на два сегмента по типу обработки контента и состоял из «видеосервиса» и «движка».
Видеосервис находился на отдельном поддомене video. Все видеоматериалы загружались в видеосервис, обрабатывались отдельно и встраивались в контент через <iframe>. Каждый видеоролик разделялся на тысячи чанков различного качества для разных каналов связи. JS-видеоплеер определял скорость соединения по скорости загрузки первого чанка и выбирал видео соответствующего качества для показа.
Движок был классической системой управления HTML-контентом: авторизация, избранное, история действий, каталог.
На входе стояли Nginx-балансировщики (фронтенды) по два на каждый сегмент, входящие запросы между балансировщиками распределялись DNS-сервером по методу Round Robin. Между бэкендами запросы распределялись по алгоритму Least Connections, когда очередной запрос передается бэкенду с наименьшим количеством соединений:
upstream backend {
least_conn;
server 192.168.1.100:80 weight=10 max_fails=10 fail_timeout=2s;
...
server 192.168.1.104:80 weight=10 max_fails=10 fail_timeout=2s;
}
Для длительных ресурсоемких операций, таких как загрузка, распаковка, обработка нового контента, подготовка видеороликов и нарезка чанков для видеосервиса, использовались очереди RabbitMQ и дополнительное ПО операционной системы: ffmpeg, zip, wkhtmltopdf.
К серверной был подведен 20-гигабитный интернет-канал с возможностью расширения до 40 Гбит. Мы, как выражаются сетевики, «сидели на девятке» (ММТС-9).
Рост нагрузки
С переводом всех на удаленку в апреле 2020 года нагрузка на портал резко возросла. Большую роль при обнаружении проблем и поиске решений сыграли различные средства мониторинга и визуализации операций: Zabbix, Symfony Profiler, Cockpit, DBeaver, Nginx Amplify.
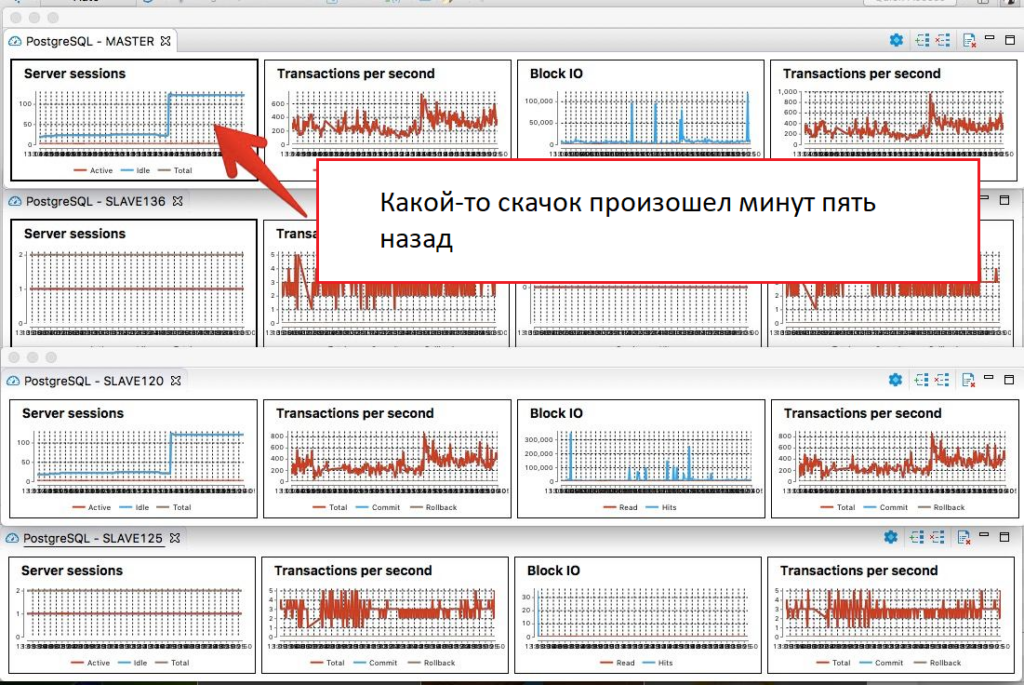
В отдельные моменты Zabbix и другие средства мониторинга показывали суммарную нагрузку до 15 000 запросов в секунду. Во многом это было следствием рекламных кампаний, проводимых коллегами. Каждая рекламная кампания приносила очередной всплеск. Мы быстро выяснили, что сайт не справляется с такими нагрузками: на экране пользователи наблюдают ошибку 502 Bad Gateway либо сайт вообще не отвечает, как при DDoS-атаке. Нужно было срочно что-то предпринимать.
Ниже привожу показания метрик за тот период: общее количество запросов и посещаемость в неделю.
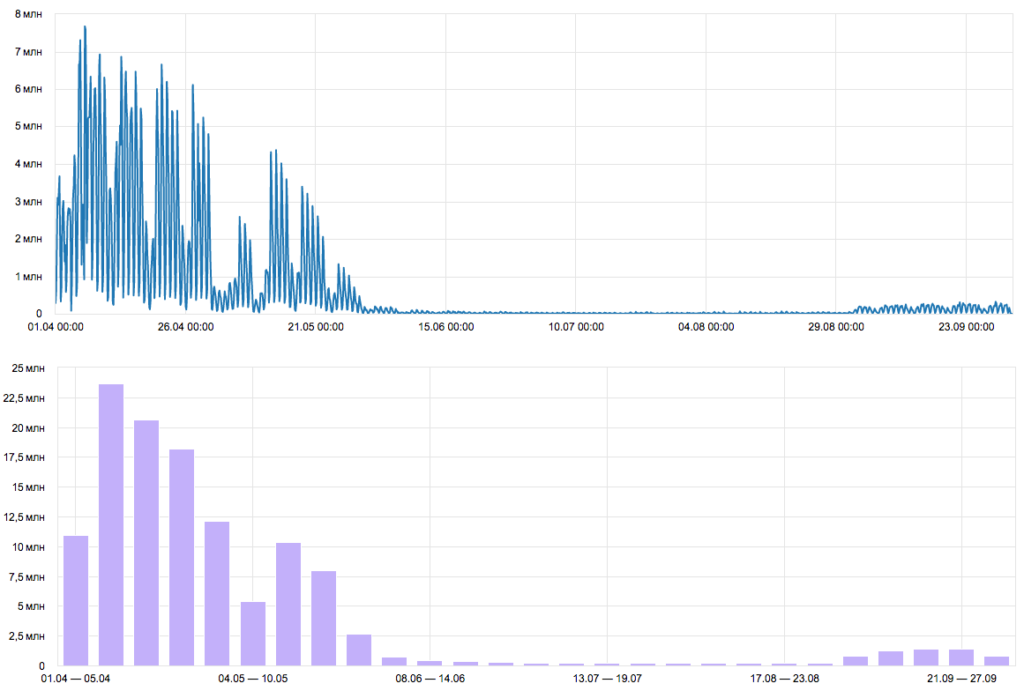
По системам мониторинга было видно, что проблема не где-то в одном месте, перегружено всё: и фронты, и бэкенды, и СУБД. Требовалось комплексное решение, поэтому оптимизацией занимались параллельно в нескольких направлениях при непрерывном взаимодействии всех коллег. Опишу по порядку, что было сделано.
Балансировка нагрузки
Узким местом на фронтах-балансировщиках, как показали графики, оказались логи Nginx. Чтобы оптимизировать дисковые операции, мы включили буферизацию логов Nginx (параметры buffer и flush в настройках access_log блока HTTP файла nginx.conf). Nginx в нашей конфигурации сбрасывал логи запросов на локальный диск через определенные промежутки времени, и на графиках эти моменты были резкими всплесками. Получался гребенчатый график, и иногда очередной такой всплеск «уходил в полку», то есть балансировщик зависал.
Чтобы устранить проблему, в качестве экстренной меры мы перенесли логи на виртуальные RAM-диски, которые сделали средствами ОС.
mount -t tmpfs -o size=25G tmpfs /mnt/ramdisk
Размер вычислили опытным путем. На первом этапе это помогло, а в дальнейшем мы перенастроили логирование и отключили буферизацию логов.
Redis и кеширование
Следующей задачей было снизить нагрузку на бэкенды. Решили это кешированием всего, что возможно закешировать. В первоначальной архитектуре в Redis главным образом хранились сессионные ключи, также некоторые разработчики хранили там часть симфонического кеша. Это никак не регламентировалось, отдельные разработчики делали это по собственной инициативе.
Поскольку самая большая нагрузка приходилась на главную страницу, кеширование начали с нее, чтобы эта страница на 100% отдавалась из кеша Redis. После этого она начала открываться мгновенно. Далее мы пересмотрели весь код наиболее часто используемых функций, скорректировали его на предмет кеширования и хранения кеша в Redis. Это тоже дало свои результаты, скорость выросла, а нагрузка на бэкенды упала.
В дальнейшем скорость еще удалось повысить, когда для Redis выделили отдельный сервер и создали Redis-кластер из 10 нод, в котором каждая нода не имеет всех данных, но знает, какая нода их имеет.
/server/redis/redis-cli --cluster create
192.168.1.70:7000
192.168.1.70:7001
192.168.1.70:7002
192.168.1.70:7003
192.168.1.70:7004
192.168.1.70:7005
192.168.1.70:7006
192.168.1.70:7007
192.168.1.70:7008
192.168.1.70:7009
--cluster-replicas 1
--cluster-yes
Использовали в данном случае также возможность Symfony напрямую работать с Redis-кластерами.
Но как бы ни радовало увеличение скорости с появлением Redis-кластера и перенесением в него симфонического кеша, эта реализация все равно давала потери. Сравнительные тесты показывали, что связь с кластером, который находится где-то в сети, пусть даже и в той же серверной, работает все равно медленнее, чем получать данные напрямую из локальной памяти ОЗУ.
Кроме того, через несколько дней пришли коллеги-сетевики и показали графики, где было видно, что сеть перегружена запросами к Redis-кластеру. Тогда было решено разделить весь кеш на два уровня:
- первый, куда бы входили данные, актуальные только для каждого отдельно взятого бэкенда;
- второй, который был нужен всем и куда выделялись пользовательские сессии и другие данные, возникшие после авторизации пользователей.
Кеш второго уровня, так как его использовали все бэкенды, поместили в сетевой Redis-кластер. А на каждом бэкенде подняли отдельный локальный инстанс Redis для быстрого кеша первого уровня. Эта мера позволила снизить нагрузку сети до приемлемого уровня и повысить скорость работы.
СУБД
Единственная нода, выделенная для СУБД-движка, хотя и была мощной (56 ядер и 512 ГБ ОЗУ), также не справлялась с количеством запросов. Мы разделили оптимизацию БД на две части: работа с кодом и организация СУБД-кластера.
Работа с кодом. Средствами Postgres и главным образом встроенным профайлером Symfony выявили избыточные и неоправданно сложные запросы к БД, скорректировали код.
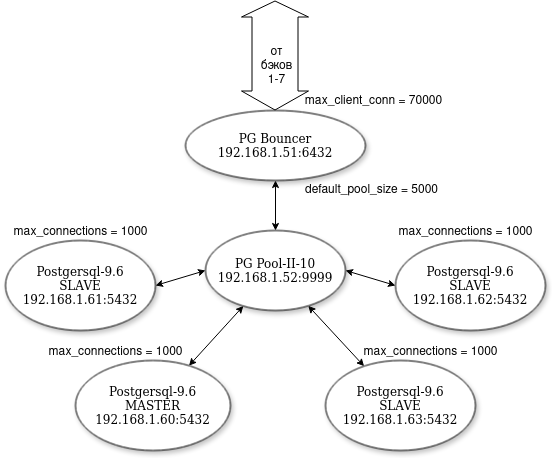
СУБД-кластер. Выяснилось, что БД также подвисает от лавинообразного роста числа соединений. Чтобы управлять пулом соединений, на входе поставили PgBouncer в режиме пула сеансов (pool_mode = session).
PgBouncer — это приложение из экосистемы PostgreSQL, которое управляет пулом соединений с базой данных, причем для клиента это происходит прозрачно, как будто соединение происходит с самим PostgreSQL-сервером. PgBouncer принимает подключения, передает их СУБД-серверу или ставит в очередь, когда все соединения в пуле (default_pool_size) заняты. При освобождении соединений из пула очередь обрабатывается.
Также к СУБД добавили четыре сервера и создали СУБД-кластер из пяти нод. Запросы по нодам распределялись с помощью PGPool — еще одного полезного приложения для PostgreSQL. PgPool был настроен на балансировку нагрузки, причем так, чтобы запросы на запись (INSERT, UPDATE, DELETE) направлялись только на master-ноду.
# Enabling load balancing for read queries
load_balance_mode = on
# Enabling master-slave mode with streaming replication
master_slave_mode = on
master_slave_sub_mode = 'stream'
Были также ограничены входящие запросы на самих PostgreSQL-нодах (max_connections).
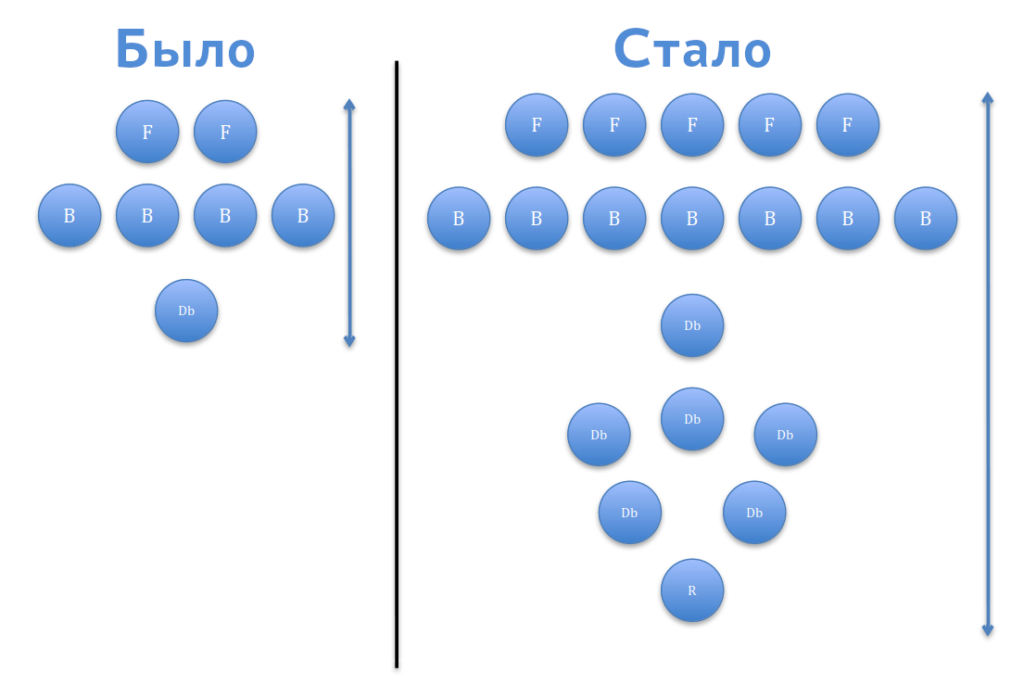
Увеличение количества бэкендов и фронтендов
Описанные выше меры позволили оптимизировать работу сайта и эффективно использовать существующие серверные мощности: ядра и память были загружены. Всё бы хорошо, но через месяц такой напряженной работы начали выходить из строя различные хардовые детали серверов, где-то память, где-то сетевой интерфейс или диск. Стало ясно, что оптимальным будет использование серверных мощностей не на 70–80% их возможностей, а примерно на 40–50%.
Кроме того, тормоза на сайте всё равно периодически случались. Тогда мы приняли решение увеличить количество фронтендов до пяти, а бэкендов — до семи.
В заключение
История оптимизации на этом не закончилась. Следующим узким местом системы стал 20-гигабитный канал, который периодически заполнялся на 100%. Наиболее приемлемым решением во всех отношениях представлялась доработка сайта на использование CDN, но это уже другая история.
Кроме первоначального проектирования системы под высокие нагрузки, важно также придерживаться определенных правил на всех этапах разработки, с учетом того, что проект будет работать под большой нагрузкой. Вот некоторые из этих правил:
- использовать запросы с параметрами, чтобы не обрабатывать весь массив объектов ради одного свойства;
- минимизировать использование циклов с запросами к БД;
- вникать во внутреннюю работу функций и методов сторонних разработчиков, различных бандлов и плагинов, использовать их с пониманием и учетом их особенностей, использовать по возможности встроенные функции языка;
- где это возможно, использовать очереди для асинхронной обработки ресурсоемких и долгих операций, например отправки email, загрузки файла;
- кешировать всё, что можно;
- переносить части функционала с бэка в браузер пользователя;
- выделять статический контент в отдельный сегмент с возможностью подключения к CDN.