Зачем в SRE паттерны
Представьте, что вы настраиваете мониторинг с нуля. Открываете документацию, а там сотни доступных метрик: latency, CPU, GC, heap, connections, queue length. Что выбрать?
Обычно берут то, что кажется важным. В итоге получается дашборд на два экрана, алерты на всё подряд — и полная каша в момент реального инцидента, потому что непонятно, куда смотреть.
Паттерны RED, USE и Four Golden Signals позволяют не думать о том, какие метрики выбрать. Они показывают, на какие вопросы должен отвечать дашборд и что служит хорошим направлением для выбора метрик.
SLI, SLO, SLA
SLI (Service Level Indicator) — измеримая характеристика поведения сервиса. Доля успешных запросов за последние 5 минут, p99 latency, процент времени, когда сервис был доступен, — всё это SLI. По сути, любая метрика, которую ты снимаешь с системы и которая что-то говорит о качестве обслуживания.
SLO (Service Level Objective) — целевое значение для SLI. Не просто latency, а «p99 latency ≤ 300 мс». Не просто «доля ошибок», а «доля ошибок < 0,1% за скользящее окно 30 дней». SLO — это внутреннее обещание команды самой себе: вот граница, за которой начинается «что-то пошло не так».
SLA (Service Level Agreement) — договор с пользователем или клиентом, основанный на SLO. Если SLO нарушается достаточно долго, наступают последствия: возврат денег, штраф, разговор с аккаунт-менеджером.
Связь между ними простая: SLI — измеряем, SLO — договариваемся внутри, SLA — договариваемся снаружи.
Обзор фреймворков
RED — взгляд со стороны клиента
RED придумали в компании Weaveworks. Она делала инструменты для Kubernetes, где основная работа происходила с подами. Компании нужен был способ мониторить сервисы, отсюда:
- Rate — запросов в секунду.
- Errors — доля или количество упавших подов.
- Duration — распределение latency (гистограммой, не средним).
Слепая зона RED: нет saturation. Сервис может отвечать быстро и без ошибок, но при этом тред-пул копит очередь, и через 30 секунд всё рухнет. RED этого не покажет.
Saturation — это степень заполненности ресурса. Показывает, насколько ресурс близок к своему пределу и есть ли у него отложенная работа, которую он не успевает выполнить прямо сейчас.
USE — взгляд со стороны ресурса
Фреймворк USE возник в эпоху классического хостинга с понятными ресурсами (CPU, диск, сеть). Админы смотрели на систему со стороны железа:
- Utilization — процент времени, что ресурс занят.
- Saturation — длина очереди / отложенная работа.
- Errors — счетчик ошибок ресурса.
Ключевая фишка USE — это не три обособленные метрики, а набор из трех метрик для каждого ресурса отдельно: для CPU, диска, ThreadPool, пула соединений HttpClient или БД.
Слепая зона USE: нет latency со стороны пользователя. Ресурс может быть недогружен (utilization 30%, queue пустая, errors нулевые), но пользователь всё равно ждет, потому что медленный, например, внешний API, который USE-метрик хоста не касается вообще.
Four Golden Signals — взгляд со стороны SLO
Четыре золотых сигнала придумали в Гугле (SRE Book, 2016) — это описание того, что Гугл эмпирически считает важным мониторить для user-facing сервисов:
- Latency — время ответа, причем отдельно для успешных и неуспешных запросов.
- Traffic — нагрузка в единицах, релевантных сервису (RPS для API, MB/s для стриминга).
- Errors — доля упавших запросов.
- Saturation — насколько ресурс близок к лимитам.
Гибрид RED и USE, но с двумя ключевыми различиями. Первое — деление latency по статусу. Второе — saturation определена через связь с пользовательским опытом, а не как абстрактная «длина очереди». То есть Four Golden Signals отвечают на вопрос «При каком уровне saturation начинается просадка для пользователей?».
Слабое место Four Golden Signals: saturation определена мутно. Гугл в книге сама признает — это hardest to measure. Для каждого ресурса метрика своя, порог свой, способ нормализации свой. На практике это означает, что Four Golden Signals не работают без USE-слоя под ними: нужно сначала собрать USE-метрики со всех ресурсов, а потом из них создать композитный saturation для дашборда.
Демо
Постановка задачи
Один эндпоинт — POST /payments. Принимает платеж, делает HTTP-запрос во внешнюю «платежную систему» (заглушка с настраиваемой latency), возвращает результат.
app.MapPost("/payments", async (PaymentRequest req, IExternalProcessor processor) =>
{
var result = await processor.ChargeAsync(req);
return Results.Ok(result);
});
IExternalProcessor — это HttpClient, который ходит в фейковую внешнюю систему. У нее есть параметр SET_LATENCY_MS, через который я в нужный момент включу деградацию.
Стек
- .NET 8 Minimal API.
- OpenTelemetry с Prometheus exporter — основной выбор для метрик.
- Prometheus + Grafana в docker-compose с pre-provisioned дашбордом.
docker-compose.yml:
services:
external-processor:
build:
context: .
dockerfile: src/ExternalProcessor/Dockerfile
ports:
- "8081:8080"
environment:
- ASPNETCORE_URLS=http://+:8080
- ASPNETCORE_ENVIRONMENT=Production
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/healthz"]
interval: 10s
timeout: 5s
retries: 5
start_period: 20s
payments-api:
build:
context: .
dockerfile: src/PaymentsApi/Dockerfile
ports:
- "8080:8080"
environment:
- ASPNETCORE_URLS=http://+:8080
- ASPNETCORE_ENVIRONMENT=Production
- ExternalProcessorUrl=http://external-processor:8080
depends_on:
external-processor:
condition: service_healthy
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/healthz"]
interval: 10s
timeout: 5s
retries: 5
start_period: 40s
deploy:
resources:
limits:
cpus: "2"
memory: 512m
prometheus:
image: prom/prometheus:latest
command:
- --config.file=/etc/prometheus/prometheus.yml
- --enable-feature=exemplar-storage
- --storage.tsdb.retention.time=1d
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
depends_on:
payments-api:
condition: service_healthy
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_USERS_ALLOW_SIGN_UP=false
- GF_AUTH_ANONYMOUS_ENABLED=false
- GF_DASHBOARDS_DEFAULT_HOME_DASHBOARD_PATH=/etc/grafana/provisioning/dashboards/red-use-golden.json
volumes:
- ./grafana/provisioning:/etc/grafana/provisioning:ro
depends_on:
- prometheus
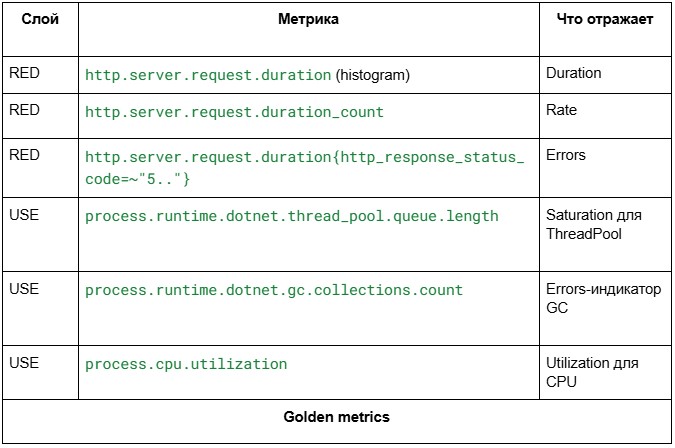
Минимальный набор метрик
Program.cs:
builder.Services.AddOpenTelemetry()
.WithMetrics(metrics => metrics
.AddAspNetCoreInstrumentation() // RED-слой
.AddHttpClientInstrumentation() // USE-слой (исходящие)
.AddRuntimeInstrumentation() // USE-слой (ThreadPool, GC)
.AddProcessInstrumentation() // USE-слой (CPU)
.AddPrometheusExporter());
app.MapPrometheusScrapingEndpoint();
Четыре строчки инструментации — это весь набор метрик, на котором собирается дашборд.
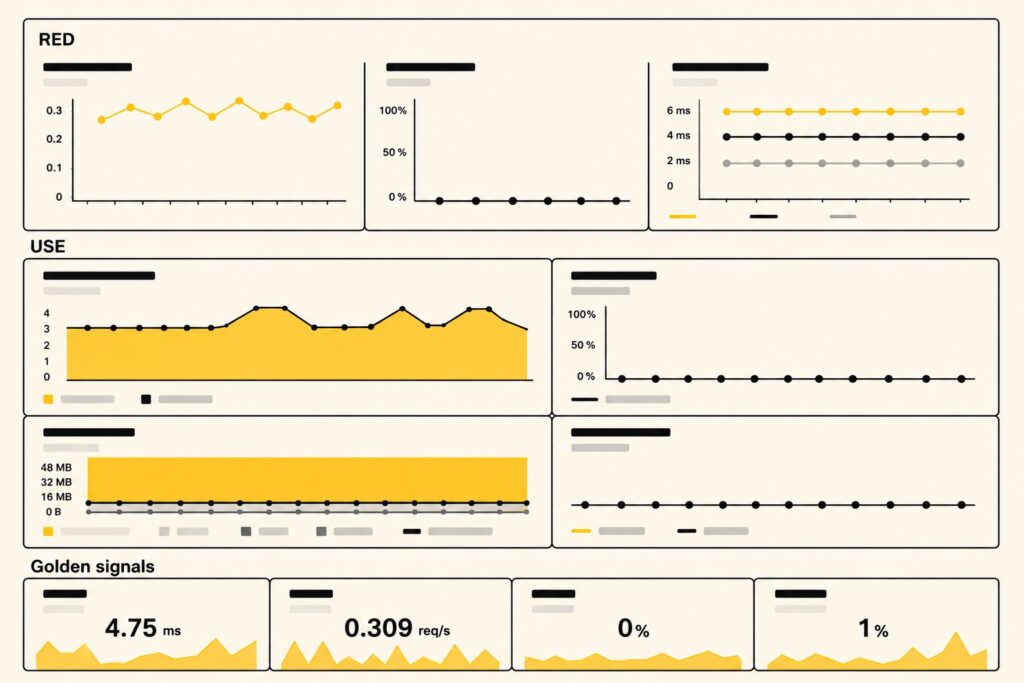
Что мы получаем:
Инцидент
Сценарий
- Запускаем генератор нагрузки: 200 RPS на
POST /payments. - Первые 30 секунд внешний API отвечает за ~100 мс, всё стабильно.
- На 30-й секунде меняем условия — внешний API начинает отвечать за 2 секунды.
- Запросы копятся, ThreadPool начинает разгребать очередь, p99 latency растет.
- В конце концов Kestrel начнет отбивать новые соединения.
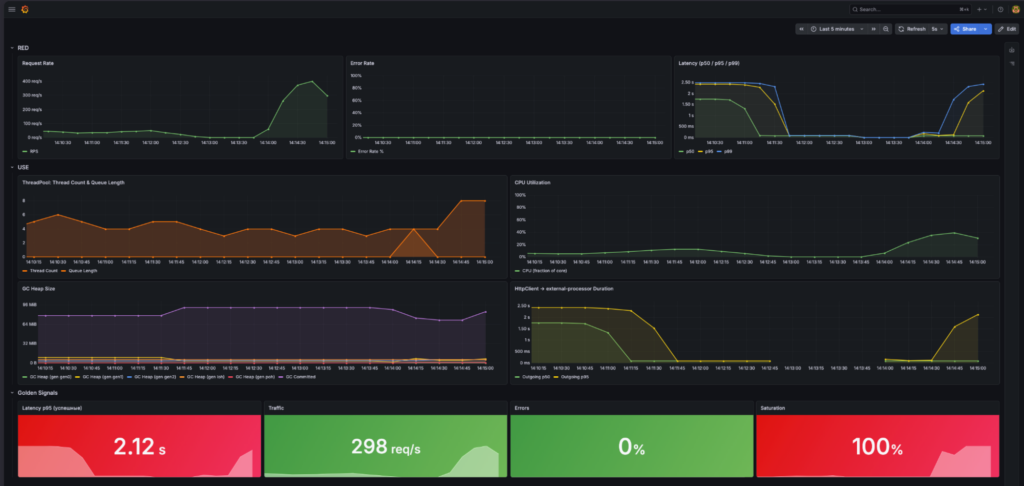
Что показывает каждый ряд
RED:
- Duration p99 растет с 150 мс до 2,1 с.
- Rate стабилен — 50 RPS.
- Errors = 0 (внешний API не вернул ни одной ошибки).
USE:
process.runtime.dotnet.thread_pool.queue.lengthрастет.- CPU utilization при этом низкий, около 40% — потоки заняты ожиданием, а не работой.
- GC ведет себя нормально.
Four Golden Signals видят:
- Latency: растет, как в RED.
- Traffic: стабилен.
- Errors: пока 0.
- Saturation: 100% — и очень скоро мы начнем падать.
Заключение
Мы разобрали паттерны в SRE — RED, USE, Four Golden Signals, а также посмотрели на их применение в инциденте.
Спасибо за прочтение! Кроме того, я веду телеграм-канал Flexible Coding, где рассказываю о программировании и не только.