Возможность автоматически определять тематику множества сайтов может быть полезна массовым сервисам и агентствам или исследователям рынка для таких целей, как, например:
- быстрая сегментация клиентской базы;
- определение долей рынка по тематикам;
- персонализация рекомендаций;
- исследование распределения ниш в определенной отрасли (например, изучение рейтингового списка сайтов);
- проверка соответствия заявленной тематики фактической;
- разбор неструктурированного массива сайтов (например, контакты с большого мероприятия), полученного любым путем, для выявления потенциальных партнеров, клиентов, исполнителей и т. д.
Механизм определения тематик
Каким бы ни был сайт — красивым или кривым, продающим или дилетантским, но он содержит тексты, состоящие из ключевых слов.
Если составить список тематик и привязать к каждой из них список релевантных ключевых слов, то получим словарь соответствия слов и тематик. Сравнив ключевики с сайта со словами из такого справочника, можно подобрать наиболее подходящую тематику.
Идея проста, но таит в себе несколько существенных нюансов:
- Где взять исходный справочник тематик и ключей?
- Ключевики могут повторяться в разных тематиках.
- Омонимы будут вносить путаницу.
- Высокая частотность ключа далеко не всегда коррелирует с его ценностью для тематики.
- Что, если система определит тематику неверно?
Подход подразумевает, что справочник тематик мы предварительно создаем сами. Это логично, ведь мы хотим подстраивать свои бизнес-процессы под использование заранее известных обозначений индустрий.
А дополнить перечень тематик набором релевантных ключей — дело не такое уж сложное, особенно с появлением ИИ-ассистентов.
Вопросы, связанные с ценностью ключевых слов, можно решить путем добавления к ключам справочника весов, выраженных числом от 1 до 10. Чем более специфично данное слово для тематики, тем выше его вес.
Качество определения тематики алгоритмом тоже можно оцифровать, вычисляя уверенность определения. Формула расчета этой метрики должна учитывать факторы, влияющие на выбор, а также коэффициенты при них, подобранные опытным путем.
Подстраховать определяемость тематик можно введением в конец алгоритма человека — асессора, который будет утверждать или корректировать результат.
Таким образом, полный алгоритм определения тематик сводится к следующим шагам:
- Разово: составление словаря тематик (или дерева тематик) и соответствующих им ключевых слов с весами.
- Отбор новых сайтов клиентов.
- Парсинг сайтов и извлечение из них ключевых слов.
- Поиск совпадений между ключами сайтов и ключами из справочника, расчет балльной оценки.
- Выбор тематики с наивысшей оценкой.
- Расчет уверенности выбора.
- Утверждение выбора асессором.
Разберем эти пункты подробней.
Словарь соответствия тематик и ключей
Для двухуровневой иерархии тематик справочник имеет примерно такой вид:
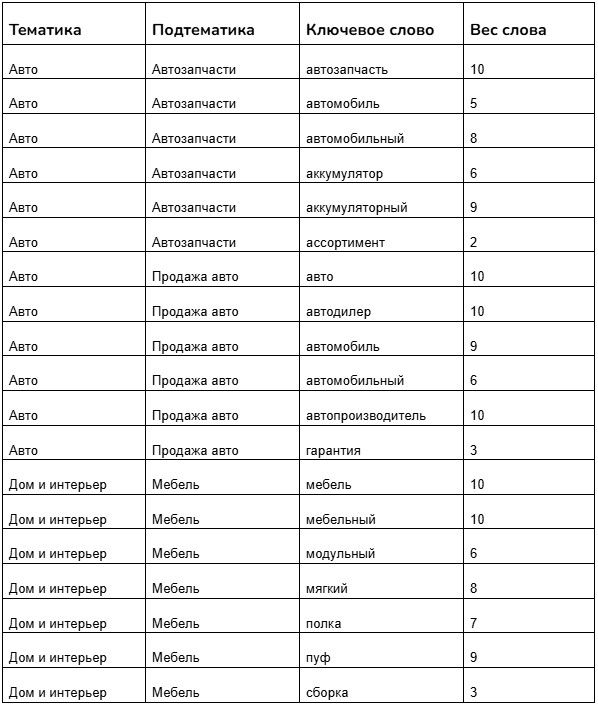
Ключевые слова приводим к нормальной форме, причем оставляем только существительные и прилагательные. Промпт к ИИ-ассистенту для первичного сбора ключей может выглядеть так:
<context>У меня есть набор тематик бизнеса и их подтематик</context>
<task>Подбери ключевые слова к тематикам и подтематикам, а также к каждому слову подбери
оценку релевантности тематике по шкале от 1 до 10</task>
<restrictions>
<keywords_quantity>
Количество ключей на подтематику: от 10 до 25, но чем больше в этих пределах, тем лучше
</keywords_quantity>
<keyword_form>
Каждый ключ должен состоять из одного слова. Все ключи должны быть представлены в базовой форме:
* именительный падеж
* единственное число (если слово имеет единственное число)
* мужской род для прилагательных
* только существительные и прилагательные
</keyword_form>
<relevance_calculation>
Релевантность оценивай, сравнивая выбранные слова друг с другом так, чтобы были представлены разные оценки шкалы.
</relevance_calculation>
</restrictions>
<output_format>
Выводи результат в виде словаря питон
</output_format>
<input_data>
Авто Автозапчасти
Авто Продажа авто
Дом и интерьер Мебель
</input_data>
Полученный от нейросети набор ключей стоит дошлифовать вручную: добавить и удалить ключи, докрутить веса. Широко используемые ключи («ассортимент», «заказ» и т. д.) лучше выбросить или использовать с низким весом. Слова релевантные, но имеющие несколько смыслов и могущие попасть в несколько тематик, снабжаем средними весами 4–6 («сеть», «инструмент», «программа» и т. д.). Узкоспецифичным словам («автосервис» для ремонта авто) проставляем высокие веса 8+.
Словарь соответствия загружаем в таблицу БД (мы используем ClickHouse).
Парсинг сайтов и определение тематик
Алгоритм определения, включающий в себя:
- загрузку словаря соответствия;
- парсинг сайтов и извлечение ключей;
- сравнение ключей сайта с ключами словаря и вычисление балльной оценки;
- выбор лучшей тематики;
- расчет уверенности;
- сохранение результатов;
реализуем в виде класса WebsiteAnalyzer. Он включает в себя методы:
- fetch_content() — извлечение контента с сайта;
- process_text() — извлечение из контента, нормализация и ранжирование ключевых слов;
- determine_theme_and_subtheme() — выбор тематики и расчет уверенности;
и несколько вспомогательных методов. Разберем основные методы немного детальней.
Парсинг контента сайта
Метод fetch_content выполняет следующие действия:
- Обращается к целевому урлу и получает его HTML-код.
- Извлекает из кода текст сегментов: метатеги, title, заголовки текста, первый и последующие абзацы текста, а также отсеивает ненужные элементы.
- Формирует content_structure — словарь сегментов контента.
Извлечение ключевых слов из контента сайта
Метод process_text выполняет следующее:
- Исправляет кодировку контента, если она сломана.
- Так как наш справочник тематик содержит только русскоязычные ключи, контент проверяется на язык, и, если язык не русский, метод завершает работу.
- Обработка русских текстов проводится с помощью библиотеки natasha (она показала лучший результат по сравнению с pymorphy2). Текст каждого сегмента разделяется на токены (слова), которые приводятся к нормальной форме.
- Ключам каждого сегмента назначается соответствующий вес. Наивысший — у meta keywords (этот элемент сейчас редко заполняется, так как поисковики давно не используют его для ранжирования, но для нас это яркое послание от веб-мастера о тематике сайта), а низший — у абзацев текста, начиная со второго.
- Рассчитывается рейтинг ключей сайта на основе их частотности и веса, который зависит от сегмента контента. Ключи сортируются в обратном порядке по этому рейтингу и выбираются 70 с наивысшим рейтингом.
Выбор тематики из справочника
Метод determine_theme_and_subtheme подбирает наиболее подходящую по ключам тематику и подтематику. Он выполняет следующие действия:
- Отобранные ключи сайта сравнивает с ключами каждой тематики справочника. Для совпавших ключей вычисляется вес совпадения как произведение весов ключа справочника и ключа сайта. Сумма весов совпадения внутри тематики есть балльная оценка этой тематики.
- Заодно рассчитываются некоторые метрики, нужные для вычисления уверенности определения: количество совпавших ключей, количество совпавших сильных ключей (с весом тематики 8+), доля балльной оценки тематики в общей сумме баллов по всем тематикам.
- Выбирается тематика и подтематика с наибольшей балльной оценкой. Они и будут результирующими.
- Рассчитывается уверенность в выборе по следующей формуле:
confidence = K × c1 + Kw × c2 + b × c3 + d × c4,
где:
- c1–c4 — веса факторов уверенности, подбирающиеся экспериментально (мы пришли к таким значениям: c = [0.1, 0.3, 0.5, 0.7]);
- K, Kw, b, d — факторы уверенности:
- K — количество совпавших ключей из сайта и из справочника для данной тематики (от 0.1 для менее трех ключей до 1 для более чем пяти);
- Kw — нормализованное количество сильных ключей, вычисляемое как
Kw = Kw_best / Kw_max, где Kw_best — количество сильных ключей для выбранной тематики, Kw_max — максимальное количество сильных ключей на тематику по всем тематикам с совпавшими ключами; - b — доля балльной оценки выбранной тематики в сумме баллов по всем тематикам;
- d — разница долей оценок выбранной тематики и следующей ближайшей к ней по оценке (этот фактор позволяет понять, насколько далеко от «конкурентов» оторвалась выбранная тематика: чем дальше, тем больше уверенности в результате).
Код классификатора тематик
Код класса WebsiteAnalyzer с рассмотренными методами, а также функции вызова этого класса для списка сайтов можно увидеть в репозитории. Код можно запускать хоть в Jupiter Notebook.
Перед запуском кода:
- Пропишите креды подключения к ClickHouse.
- Создайте в ClickHouse таблицу domain_theme_keywords с вашим справочником тематик и ключевиков.
- Убедитесь, что установлены все необходимые коду библиотеки.
Автоматизация запуска этого алгоритма, а также создание интерфейса пользователя для асессора — отдельная задача. Я надеюсь разобрать эту тему в отдельной статье.
Резюме
Для массового автоматического определения тематики бизнеса по сайту мы используем следующий подход:
- Собираем справочник соответствия тематик (и подтематик) и ключевых слов с их весами.
- Парсим текстовый контент сайта, извлекаем и нормализуем ключевые слова.
- Ищем ключевые слова сайта в справочнике соответствия, вычисляем балльную оценку для каждой тематики, для которой совпал хоть один ключевик.
- Тематика с наибольшей оценкой и есть тематика данного сайта.
- Числовая метрика. Уверенность позволит выявить результаты, требующие ручной валидации асессором.