Контекст: почему возникла необходимость переноса
Обычно тип XML-файлов используется для разметки данных, разметки текста по смыслу, хранения настроек или разметки веб-страниц по смыслу. Но иногда XML-файл применяют в качестве своеобразной базы данных, используемой для обычных десктопных приложений Windows.
Мне пришлось столкнуться с таким случаем использования XML-документа в качестве базы данных в программе для настройки интеллектуальных приборов с протоколом Modbus RTU.
Modbus — коммуникационный протокол, который основан на архитектуре «ведущий — ведомый» (master — slave). Прибор или датчик с таким протоколом содержит десятки, а порой и сотни регистров, хранящих различную информацию о его настройках и различные выходные параметры, в соответствии с функциями вычисления, заложенными в него.
Существует множество программ для взаимодействия с устройствами Modbus, но они неудобны для работы с наборами регистров конкретного прибора, потому что нужно вводить номера регистров, чтобы прочитать или записать в них данные. Если количество регистров несколько сотен, то работать с цифровыми обозначениями человеку становится очень сложно.
Для удобства работы с такими приборами нужно разработать специальную программу и перенести набор регистров прибора в меню с группировкой по функциям регистров, ввести их наименования, адреса, типы и другие характеристики исходя из назначения регистров.
В моем случае группировка регистров и их характеристики содержались в XML-файле, отображаясь на конкретный прибор. Но типов приборов было 40–50, и их файлы XML отличались количеством тегов и типом. При каждом выпуске новой версии внутреннего программного обеспечения прибора нужно было всегда дорабатывать его XML-файл, отображая его на добавленную в новой версии функциональность.
С простыми файлами на одну страницу проблем не было, но большинство файлов были на десятки страниц, и программист внутреннего ПО тратил много времени на непрофильную работу. Тот, кто пробовал редактировать XML-файлы объемом больше десяти страниц, понимает, что это не просто неудобно, а катастрофически неудобно из-за большого риска ошибок и опечаток. И какой-нибудь редактор типа Notepad++ тут не особо помогает. Любой XML-файл имеет неудобочитаемый формат, с которым человеку работать сложно, особенно при больших размерах файла.
К тому же надо было развивать саму программу для работы с приборами Modbus, вводить новые фичи, а отсутствие нормальной БД сдерживало этот процесс. Проблема усугубилась еще и тем, что разработчик, который придумал использовать XML, покинул компанию. Легаси-код на С# «оброс» за несколько лет стольким количеством программных «костылей», что и сам разработчик с большим трудом вспоминал, зачем и почему так было сделано. Поддерживать дальше «спагетти-код» не было смысла, поэтому встал вопрос о полном обновлении программы.
Задача: что нужно было сделать, чтобы новая система работала правильно
Новая программа должна была работать только с базой данных — как в серверном, так и в локальном варианте. Необходимо было перенести уже наработанные данные из XML-файлов в базу данных и добавить новую функциональность, табличный редактор, вычисляемые регистры и настраиваемые формулы их расчета в табличном редакторе, выбор порядка следования пунктов меню и списков регистров, тестовый и рабочий раздел карт приборов.
Таким образом, появилась задача рефакторинга и разработки новой программы и переноса около 40 XML-файлов. Нужно было избавиться от хранения карт регистров приборов в формате XML и создать дружественный человеку интерфейс редактирования карты прибора. В качестве базы данных хранения карт приборов было решено использовать уже имеющуюся в компании БД MS SQL SERVER и локальную SQLite.
Локальная SQLite нужна для использования программы у конечного пользователя, так как ПО доступно пользователю с сайта компании. Серверная БД должна была использоваться только внутри компании для отладки встроенного программного обеспечения прибора в процессе разработки и в производстве на этапе финальной настройки при изготовлении прибора.
Для описания способа переноса XML-файла я использую один из простейших файлов XML, посмотреть его можно здесь.
Этот файл показывает, что меню прибора содержит информацию о приборе, его наименование, характеристики в полях MB_ID и TypeDev, указатель на пункт меню sheet и его название в поле caption. Далее идут строки с полями названия регистра, его номера и описание типа данных в регистре.
Некоторые регистры имеют следующие за ним по тексту и связанные с ним поля item, например перечень единиц мгновенного расхода, величина которого хранится в связанном с item регистре. В других файлах количество пунктов меню (sheet), регистров (register) и их атрибутов значительно больше. Кроме того, в XML-файле используются атрибуты, указывающие на элементы управления и интерфейса (кнопки, комбобоксы), разделители в списке регистров и заголовки групп регистров, указатели на таблицы.
Анализ иерархической структуры XML-файла показал, что для переноса в базу данных нужно в БД создать пять таблиц.
DEVICE
- Номер прибора (порядковый номер в списке файлов переноса).
- Тип прибора.
- Идентификатор Modbus.
- Название прибора.
MENU
- Номер меню.
- Название пункта меню.
REGISTERS_FROM_XML
- Идентификатор.
- Идентификатор родителя (меню).
- Название регистра.
- Адрес.
- Тип регистра.
- Формат.
ITEMS
- Идентификатор item.
- Идентификатор родителя (регистр).
- Значение.
ID_XML
- Уникальный идентификатор регистра.
Конечно, в таблицах для других XML-файлов требуется больше полей, которых нет в примере, но для иллюстрации метода переноса показанных полей вполне достаточно.
Кратко о подключении прибора по Modbus RTU. В процессе подключения прибора по протоколу Modbus прибор выступает как slave, то есть по требованию мастера (программы) выдает ему свой идентификатор modbus MB_ID , по которому программа определяет записанный в таблицу DEVICE прибор и открывает связанное с таблицей DEVICE меню из таблицы MENU. Далее при выборе пункта меню программа считывает данные из указанных в связанных с таблицей MENU адресах регистров прибора и отображает эти параметры. То есть в БД должна быть связанная по полям идентификаторов приборов и их «родителей» иерархическая структура таблиц, указанных выше.
Создаем таблицу в базе данных MS SQL Server
Для переноса файлов нужно создать таблицу — источник файлов в БД.
[TABLE_XML_FILE_DEVICE]
[ID_DEVICE] [int] NOT NULL, — номер прибора
[FILE_PATH] [nvarchar](255) NULL, — путь до файла
[FILE_DATE] [datetime] NULL, — дата файла
[DATE_MOVE] [datetime] NULL) — дата переноса
Теперь нужно заполнить информацию о файлах для всех 40 приборов. Обычно такой список создается в Excel и далее переносится в таблицу средствами импорта в БД.
Поле [ID_DEVICE] будет уникальным номером прибора в таблице DEVICE.
Далее нужно в БД создать таблицу-приемник TABLE_DEVICE_XML для переноса XML.
[ID] [int] NULL,
[PARENT_ID] [int] NULL,
[nodetype] [int] NULL,
[LOCALNAME] [nvarchar](50) NULL,
[prev] [int] NULL,
[text] [nvarchar](4000) NULL,
[item] [int] NULL,
[PK_IDENT] [int] IDENTITY(1,1) NOT NULL
Структура этой таблицы для любого XML-файла не меняется. В эту таблицу будет записываться переносимый XML-файл c помощью скрипта SQL, приведенного ниже. Файлы XML должны быть доступны вашему SQL-серверу по указанному пути.
DECLARE @hdoc int — указатель на файловый поток XML
,@file_stream XML — файловый поток
,@SQL_command nvarchar(1000) — команда импорта SQL
,@filePath NVARCHAR(255) — путь до файла XML
SELECT
@FilePath = FILE_PATH — путь
FROM
TABLE_XML_FILE_DEVICE — таблица с информацией и путем до файла XML
WHERE
ID_DEVICE = @ID_DEVICE
Для получения данных используем оператор OPENROWSET в Transact SQL. Формируем запрос динамического SQL для получения данных из файла, так как в OPENROWSET может указывается только строка пути до файла и ее нельзя заменить на переменную @filePath. При использовании динамического SQL такое ограничение снимается.
SET @SQL_command = N' SELECT @file_xml = (SELECT *
from OPENROWSET(BULK ''' + @filePath + ''', SINGLE_BLOB) as [XML])'
/* запуск запроса @SQL_command и получение файлового потока в переменной @file_stream */
EXEC sp_executesql @SQL_command,
N'@file_xml XML OUTPUT',
@file_xml = @file_stream OUTPUT
/* связывание идентификатора @hdoc с файловым потоком @file_stream и запись в этот идентификатор данных из XML с помощью служебной процедуры */
EXEC sp_xml_preparedocument @hdoc OUTPUT,@file_stream
— очищаем таблицу-приемник
TRUNCATE TABLE [Table_device_xml]
/*загружаем таблицу-приемник из разобранной строки @file_stream запросом по идентификатору @hdoc оператором OPENXML */
INSERT Table_device_xml
SELECT [ID] ,
[PARENTID] as PARENT_ID,
[nodetype],
[LOCALNAME],
[prev] ,
[text],
NULL
FROM OPENXML (@hdoc, '/',1)
EXEC sp_xml_removedocument @hdoc — удаляем @hdoc из памяти сервера (важно!)
В результате в таблице Table_device_xml получится перенесенный иерархический набор данных из XML-файла @filePath. Если структура XML-файла будет другая, то все теги в любом случае будут записываться в Table_device_xml в поле LOCALNAME. Поля ID, PARENT_ID, nodetype генерируются автоматически при выполнении встроенной процедуры sp_xml_preparedocument. Они указывают на иерархическую структуру таблицы, где ID — номер «родителя», PARENT_ID — указатель на этот номер, nodetype — уровень вложенности.
Первые 50 строк этой таблицы показаны здесь.
Раскладываем данные по разным таблицам без потери связи между атрибутами
Сразу возникает вопрос об алгоритме обработки иерархической структуры для раскладки данных из получившейся таблицы по пяти таблицам без потери связи между тегами-атрибутами по полям ID и PARENT_ID.
В MS SQL для обхода двоичного дерева можно применить так называемые CTE с рекурсией.
CTE — это временная таблица, формируемая для следующего за определением CTE оператора SELECT. Но мои эксперименты с использованием рекурсивных запросов оказались безуспешными ввиду наличия значительного количества атрибутов в других, более сложных файлах XML. С простыми файлами, как в приведенном примере, это работало, но со сложными это была проблема, потому что было слишком много ручной работы, не поддающейся автоматизации.
Я нашел другое решение: вместо рекурсии использовать обычные циклы обработки пар атрибутов с фильтрацией по полю LOCALNAME, используя свойство иерархии связности тегов в LOCALNAME сверху вниз.
Для начала было бы значительно удобнее для дальнейшей обработки, чтобы значения по полям caption и text были бы в одной строке, без связки через неинформативную промежуточную строку.
Следующий код легко и просто это делает:
/* для ускорения работы предварительно нужно создать кластеризованный индекс по полю pk_ident */
DECLARE @NEXT_LINE int = (select min([pk_ident[)+1 from Table_device_xml)
/* в cтроку localname='caption' переносим название из строки ниже */
WHILE @NEXT_LINE is not null
BEGIN
----смещение на одну строку--------------------------------------
UPDATE Table_device_xml
SET [text] = (
SELECT [text]
FROM Table_device_xml
WHERE [pk_ident]= @NEXT_LINE + 1
)
WHERE [pk_ident] = @NEXT_LINE
SELECT
@NEXT_LINE = MIN([pk_ident])
FROM
Table_device_xml
WHERE
pk_ident > @NEXT_LINE
END
Этот SQL-код демонстрирует принцип оптимальной и быстрой обработки набора данных без применения оператора FETCH, который сложно оптимизировать по быстродействию. Быстрый метод обработки называется «агрегат min to min». Цикл обработки начинается с оператора WHILE. Параметр цикла — это минимальный уникальный номер записи в таблице Table_device_xml.
Переход к следующему номеру записи внутри цикла осуществляется по запросу:
SELECT
@NEXT_LINE = MIN([pk_ident])
FROM
Table_device_xml
WHERE
pk_ident > @NEXT_LINE
Новое значение параметра цикла @NEXT_LINE вычисляется как минимальное, которое больше текущего. Когда обработанных записей в наборе не остается, параметр @NEXT_LINE становится NULL. Это контролируется в начале цикла оператором WHILE @NEXT_LINE is not null. Цикл выполняется, пока @NEXT_LINE не принимает значение NULL, которое генерирует агрегатная функция SQL MIN() в случае отсутствия значения при pk_ident больше @NEXT_LINE.
Так как я решил отказаться от рекурсии, то для упрощения обработки можно удалить в таблице Table_device_xml неиспользуемые в переносе записи с ненужными значениями в поле LOCALNAME.
В других более сложных файлах XML хранятся и указатели на элементы интерфейса, такие как разделители, кнопки, комбобоксы и чекбоксы. В новой программе я решил отказаться от множественных элементов управления вводом данных, применяемых в старой программе, и использовать только табличный ввод данных, а из элементов управления использовать кнопку и picklist в таблицах.
Код ниже показывает удаление строк с ненужными атрибутами LOCALNAME:
DELETE
Table_device_xml
WHERE
LOCALNAME = '#text' and text is null and localname !='sheet'
DELETE
Table_device_xml
WHERE
LOCALNAME in ('row','edit.registers', 'indicator.registers' ,
'register' ,'edit',
'depend','button.depends',
'passwd','list','list.registers','list.items',
checkbox.registers','checkbox',
'editSTR.registers','editSTR','table.colnames',
'graph.depends','button.registers',
'isStart','edit.depends')
После последнего преобразования таблица Table_device_xml преобразуется в удобный вид для дальнейшей обработки (показана часть таблицы):
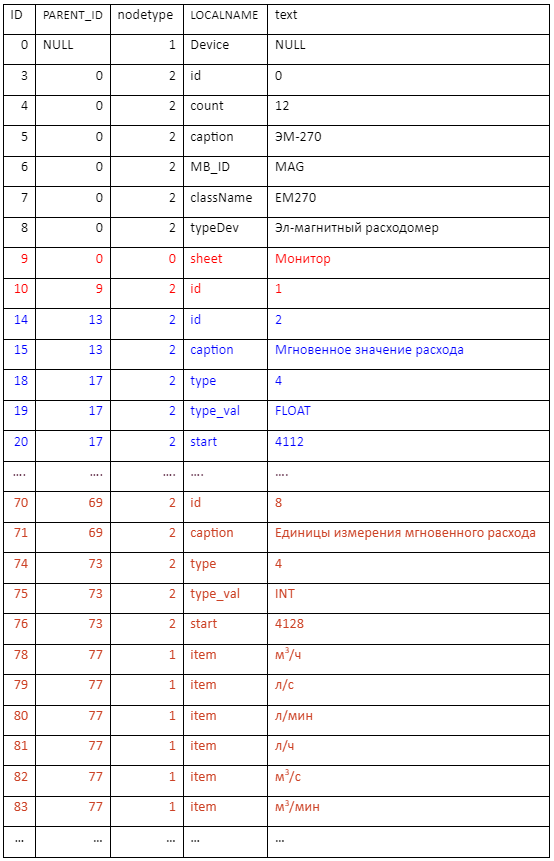
Анализ таблицы показывает, что меню прибора имеет корень с названием sheet = Монитор. Все необходимые нам данные расположены в нужных строках сверху вниз.
Так как после удаления части записей с ненужными атрибутами связность по ID и PARENT_ID не гарантируется, то обработку для раскладки по целевым таблицам нужно делать в циклах с фильтрами и сортировкой по ID и PARENT_ID для восстановления связности в таблицах.
Так как обработка и модификация осуществляется в одной и той же таблице, то обрабатываемый набор нужно сначала скопировать во временную таблицу и в процессе обработки наборов во временной таблице модифицировать основную таблицу.
Код обработки можно посмотреть в этом файле.
Заключение
Есть и другой алгоритм обработки с использованием уровня связности по полю nodetype таблицы Table_device_xml. В этом случае удаление лишних тегов не применяется и связность не нарушается. Здесь тоже нужны фильтры по парам атрибутов с учетом nodetype. Но интуиция подсказала мне, что этот алгоритм сложнее в реализации и требует больше времени на разработку и отладку, потому что уровень вложенности в XML-файлах разный.
Приведенный выше способ показал хорошую переносимость и связность данных для всех, в том числе и самых сложных и объемных XML-файлов. Итоговые файлы потребовали минимального редактирования во встроенном табличном редакторе новой программы. Это потребовалось потому, что у некоторых XML-файлов был четвертый уровень вложенности меню, а в новом редакторе ограничение установлено на третьем уровне. Такая вложенность оказалась более удобной для пользователей.