Постановка задачи
Задачу мы ставили в следующей формулировке.
Требуется объединить все анонимизированные цифровые следы одного клиента (человека или группы людей, представляющих одного и того же клиента) в единую сущность со своим уникальным идентификатором user_entity. Далее можно будет по этому идентификатору объединить все касания.
У нас есть идентификатор client_id посетителя из системы веб-аналитики и идентификатор user_id личного кабинета пользователя в нашей системе.
Идея в том, чтобы объединить пользователей по одинаковым client_id или user_id. Пользователь, который заходил с разных девайсов в разные аккаунты Elama, должен идентифицироваться как один и тот же. Примерно вот так:
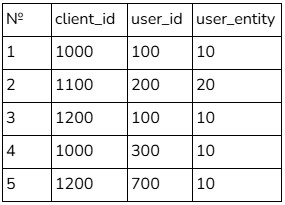
Строки 1, 3–5 относятся к одному и тому же клиенту. Почему?
- 1 и 3 связаны по
user_id; - 1 и 4 связаны по
client_id; - 3 и 5 связаны по
client_id.
Таким образом, можно установить, что эти строки принадлежат одному субъекту.
Способ решения
Перед нами классическая задача склейки профилей (Identity Stitching): связать анонимные сессии с устройств (client_id, обычно куки или device_id) с авторизованными профилями (user_id) для создания единого идентификатора пользователя (user_entity). Кроме того, необходимо отловить существующие связи между профилями.
Ниже приведено подробное описание алгоритма и логики работы разработанного нами скрипта.
Основная концепция
Скрипт рассматривает связи между client_id и user_id как двудольный граф, где:
- узлы — это идентификаторы клиентов и пользователей;
- ребра — это факты их совместного появления в аналитике (например, пользователь залогинился с этого устройства).
Главная проблема при такой склейке — аномалии, или, как мы их называем, «нелегальные мосты». Когда сотрудник Elama авторизуется в ЛК многих клиентов, он становится «мостом» между разными аккаунтами через свой client_id и искусственно связывает никак не связанных друг с другом пользователей.
Другие примеры (не наши):
- Публичный компьютер в библиотеке: один
client_idможет быть связан с сотнямиuser_id. - Бот или парсер: один
user_idможет авторизоваться с тысяч разныхclient_id(прокси).
Если не отфильтровать такие узлы-мосты, скрипт склеит тысячи независимых людей в одного гигантского «суперпользователя».
Пошаговый алгоритм работы
Разберем поэтапно, как работает скрипт, который мы приведем ниже.
Весь процесс запускается через главную функцию defining_users_entity() и делится на пять основных этапов:
Этап 1. Загрузка данных
Скрипт подключается к базе данных ClickHouse и скачивает сырые пары client_id + user_id.
Этап 2. Профилирование и анализ графа
Функция analyze_connections() вычисляет, сколько связей имеет каждый идентификатор. Скрипт строит распределение (медиана, 90/95/99 перцентили, максимумы) и логирует информацию. Это нужно для мониторинга: дата-аналитик может по логам понять, не слишком ли жесткие или мягкие выбраны пороги для фильтрации.
Этап 3. Итеративная фильтрация мостов
Это самая важная защитная часть скрипта (функция iterative_filtering()).
Скрипт ищет узлы-аномалии:
client_id, у которых большеMAX_CLIENT_CONNECTIONSавторизаций;user_id, у которых большеMAX_USER_CONNECTIONSустройств.
Такие связи удаляются из графа. Затем процесс повторяется (до MAX_ITERATIONS раз). Это важно, потому что удаление «суперузла» может изменить топологию графа и выявить новые подозрительные узлы, которые раньше скрывались за ним. Отфильтрованные узлы попадают в черный список (suspicious_clients, suspicious_users).
Этап 4. Поиск компонентов связности (склейка)
После очистки данных от ботов и публичных устройств начинается сама склейка (внутри process_data_with_iterative_filtering()):
- Union-Find (Система непересекающихся множеств). Скрипт использует классический алгоритм графов (функции
find_strиunion_str) для объединения узлов в компоненты связности. Если Клиент_А связан с Юзером_1, а Юзер_1 связан с Клиентом_Б, они все попадают в одну группу. - Определение
user_entity. Для каждой полученной группы скрипт находит минимальныйuser_id. Именно он назначается главным идентификатором (user_entity) для всей группы. - Защита от гигантских групп. Если размер склеенной группы всё равно превышает
MAX_COMPONENT_SIZE, скрипт признает эту группу бракованной. Все участники этой группы принудительно разъединяются и считаются изолированными.
Размеры самых больших групп стоит постоянно мониторить. Если они вылазят, возможно, появился новый нелегальный мост, который стоит выявить и удалить из исходных данных. - Обработка отфильтрованных узлов. Для всех узлов, которые попали в черный список на шаге фильтрации или из-за размера компонентов, склейка не применяется. Их
user_entityприравнивается к их собственномуuser_id(они остаются сами собой).
Этап 5. Формирование результата и выгрузка
- Результаты упаковываются в Pandas DataFrame. Каждая строка исходных данных теперь обогащена колонкой
user_entity. - Считается метрика качества — коэффициент сжатия (насколько уменьшилось число уникальных сущностей по сравнению с сырыми
user_id). - Скрипт очищает целевую таблицу в ClickHouse (TRUNCATE TABLE) и заливает в нее новые данные батчем (с использованием массивов NumPy для максимальной скорости INSERT).
Код скрипта
Код функций на Python расположен в репозитории. Можно вызывать функцию defining_users_entity() вручную или поставить на расписание (например, через Airflow).
Резюме
Кросс‑девайсное и кросс‑юзерное отслеживание необходимо для качественной оценки многоканальных последовательностей в маркетинговой аналитике и для правильного учета персональной истории в коммуникациях с клиентами.
Наша реализация такого отслеживания предполагает объединение цифровых следов клиента в единую сущность (user_entity).
Склейка профилей происходит через построение двудольного графа, в узлах которого — идентификаторы client_id и user_id, а в ребрах — обнаруженные факты их совместного появления в истории.
Главная проблема алгоритма — «нелегальные мосты», то есть узлы, которые неестественно связывают огромное количество реально не связанных пользователей (тестовые, технические, менеджерские аккаунты и т. п.). Отсеивать их следует как при формировании исходных данных, так и в самом алгоритме, ограничивая порогом размер конечных групп.