
Поток
А что же такое «поток» в целом? Поток — это набор каких-то инструкций, которые идут друг за другом и должны выполняться последовательно. Термин можно немного расширить, сказав «поток исполнения инструкций».
На примере
Представьте себя школьником, который решает задачу по математике — например, вычисляет скорость на основе времени и расстояния. Вы знаете формулу, исходные данные, поэтому нужно просто подставить числа. Посчитав результат, вы выполнили некоторую инструкцию (или несколько инструкций).
Теперь представьте, что нужно решить несколько задачек и делаете вы это со своим другом. Вы берете первую задачу, а он — вторую. И одновременно решаете свои задачки, выполняете свои наборы инструкций и получаете результат. В момент вычислений вы — один поток исполнения инструкций, а ваш друг — второй поток исполнения инструкций.

А теперь к делу!
Аппаратная часть
Внутри процессора
Процессор — это «мозги» компьютера. Тут происходят все сложные вычисления и выполнение различных команд. Для простоты определим, что процессор «складывает байтики», а то, если погружаться в тему инструкций, можно немного сойти с ума.
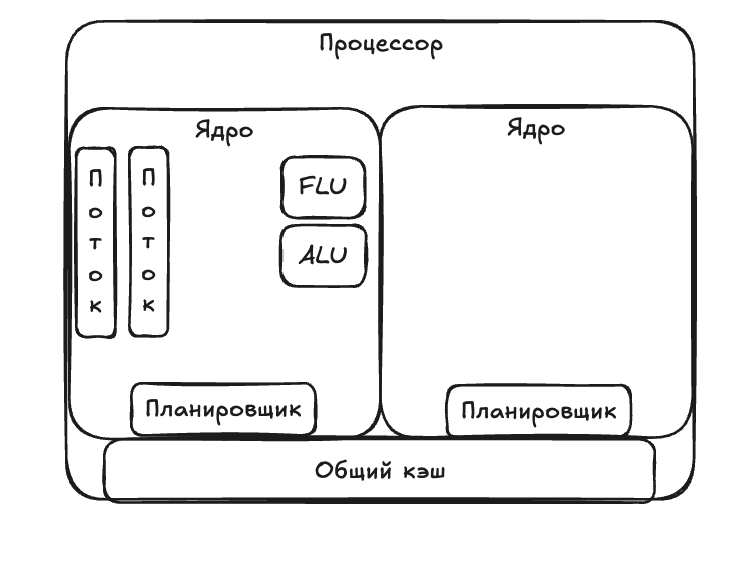
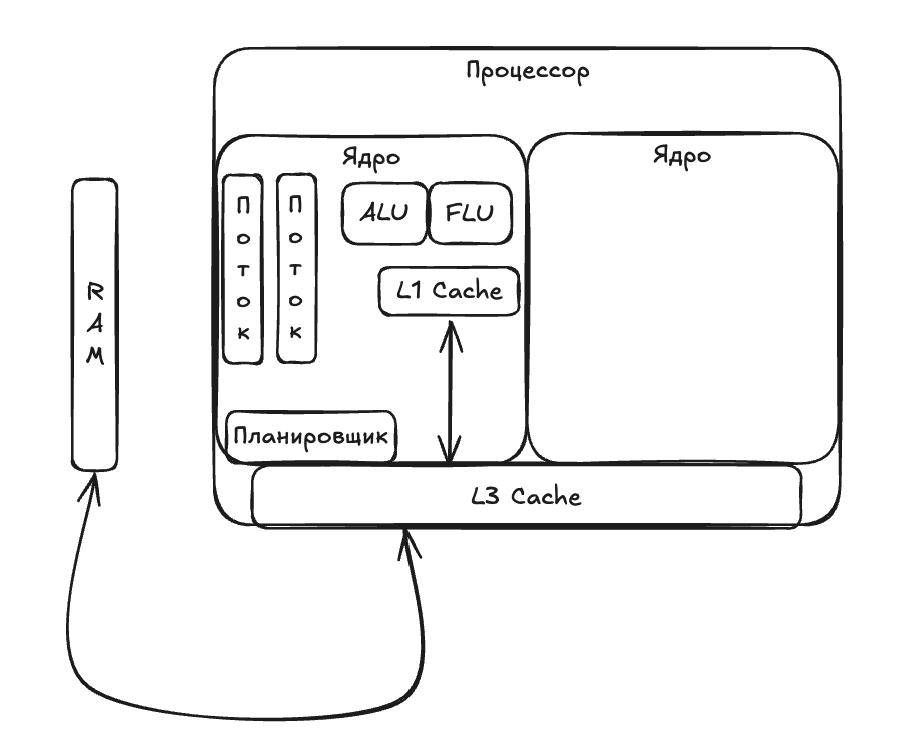
Процессор состоит из множества функциональных частей, но мы остановимся на тех, что непосредственно относятся к многопоточности, — на ядрах.
Внутри каждого ядра процессора есть следующие элементы:
- Исполнительные блоки — это части процессора, которые относятся к непосредственному исполнению инструкций. Например, блок ALU нужен для выполнения арифметических операций с целыми числами, а FPU — для чисел с плавающей запятой.
- Управляющие блоки — это части процессора, которые получают инструкции, декодируют их и выбирают, когда и на каком исполнительном блоке они будут выполнены. Пример управляющего блока — планировщик задач, который как раз определяет, когда и где выполнить инструкцию.
Упрощенно процессор выглядит примерно так:
С составом разобрались, теперь переходим к делу.
Многопоточность в процессоре
Разберем, как работает многопоточность на уровне процессора. А для этого провалимся в ядро.
Итак, напоминаю, что поток — это просто последовательность инструкций. Для наглядности возьму три базовых вида инструкций, которые могут быть в потоке:
- Арифметическая операция без плавающей запятой (выполняется на ALU).
- Арифметическая операция с плавающей запятой (выполняется на FPU).
- Ожидание данных из памяти.
У нас есть два потока с инструкциями, и мы хотим, чтобы эти инструкции выполнялись параллельно. Но ядро может выполнять один тип операции в один момент времени! Так как тогда происходит выполнение команд?
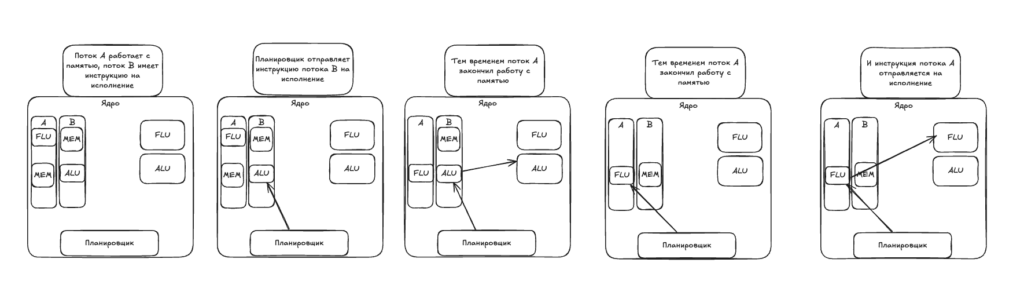
Допустим, у нас есть ядро с поддержкой двух аппаратных потоков, и на него назначено два потока, A и B.
Поток A содержит:
-
- Инструкция 1: загрузить данные из памяти.
- Инструкция 2: выполнить арифметическую операцию с плавающей запятой.
Поток B содержит:
-
- Инструкция 1: выполнить сложение в ALU.
- Инструкция 2: переместить данные в память.
Планировщик «думает» примерно так:
- Пока поток А загружает данные из памяти, я могу сделать что-то из потока В. Выполню сложение, если ALU свободен.
- Задача потока B закончена, и теперь он работает с памятью. А поток А как раз прочитал данные и ждет выполнения инструкции. Сделаю ее на FPU.
С учетом многоядерности процессоров на самом деле это выглядит примерно так:
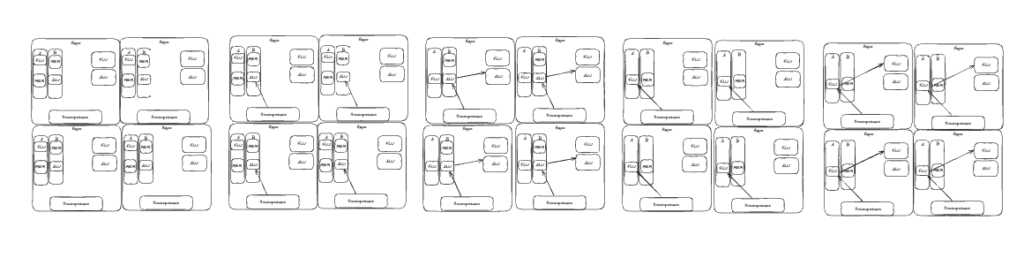
Инструкции из разных потоков чередуются между собой при выполнении, из-за чего создается ощущение параллельности их выполнения. Еще на разных исполнительных блоках могут выполняться разные инструкции — например, пока ALU занят, можем выполнить инструкцию для FPU из другого потока.
Проблема общих ресурсов
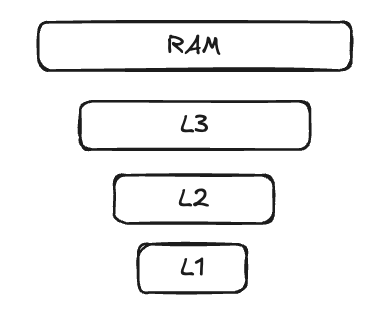
В процессорах существует кеш. Он создан для быстрого доступа к данным, чтобы не было необходимости постоянно «ходить» в оперативную память. У него обычно несколько уровней:
- L1 (Primary Cache) — самый маленький кеш, локальный для каждого ядра. Доступ к данным оттуда очень быстрый, но сам кеш очень маленький.
- L2 — этот кеш немного больше и немного медленнее, чем L1. Он может быть общим для группы ядер в многоядерных процессорах.
- L3 — общий кеш. Он используется для передачи информации между всеми ядрами и хранения часто запрашиваемых данных.
Потоки используют кеш L3 для передачи данных между ядрами. Например, если поток обновляет значение переменной, это значение обновляется в кеше и становится доступным другим потокам.
Детализируем наш процессор:
А вот так выглядит иерархия памяти:
Там, где есть общие ресурсы, возникают конфликты доступа к этим ресурсам. Они могут меняться, устаревать, а из-за этого появляются проблемы с конечным результатом операций. И тут на помощь приходит когерентность (согласованность) кеша — Cache Coherence.
Отвлечемся на аналогии.
Представьте, что вы сделали шаблон какого-то документа в MS Word и несколько человек его распечатали. И тут выяснилось, что шаблон необходимо поменять. Вы исправили свой документ, но людей не предупредили — и они некорректно его заполнили.
Ваш документ — это L3-кеш, а люди — это ядра процессора, которые эти данные сохранили в кеши L2 или L1 для использования. Если при модификации данных не сообщить, что они изменились, возникнут проблемы.
Итак, когерентность — это свойство кеша, которое означает целостность данных для копий общего ресурса. Кеш называется когерентным, если выполняются следующие условия:
- Информирование о записи: изменение данных в любом из кешей должно быть распространено на другие копии этих данных (этой линии кеша) в соседних кешах.
- Видимость чтения: операции чтения и записи в одну и ту же ячейку памяти должны быть видимы для всех процессоров в одинаковом порядке.
Для соблюдения этих свойств существуют протоколы когерентности, например MESI.
Этот протокол добавляет некоторые статусы для данных в памяти:
- Modified (M) — данные были получены из основной памяти (например, из оперативной) и изменены. Эти данные нельзя изменять, пока они не синхронизируются с основной памятью. После синхронизации с основной памятью состояние данных будет Shared.
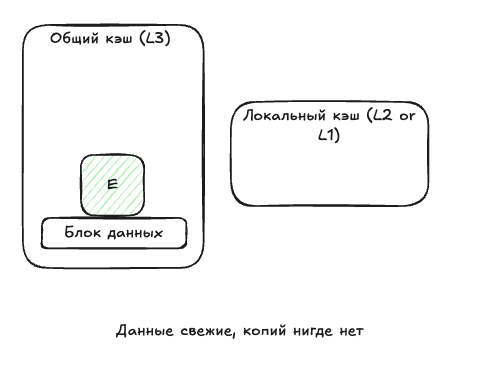
- Exclusive (E) — данные находятся только в текущем кеше, и они совпадают с основной памятью. Если ядро прочитает данные из этого кеша, они получат статус Shared. Если запишет, статус будет Modified.
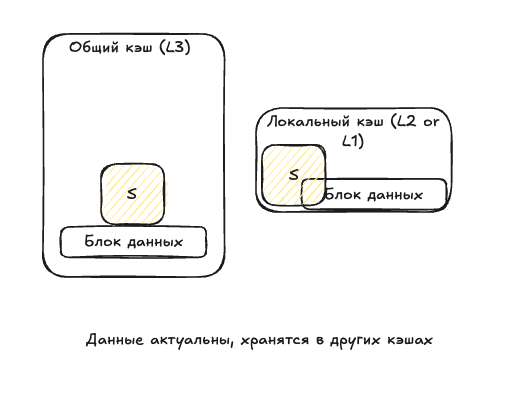
- Shared (S) — данные совпадают с основной памятью, а также хранятся в других кешах. Если в одном из кешей данные изменятся, статус изменится на Modified.
- Invalid (I) — данные устарели и не используются. Когда данные помечаются статусом M или E, их копии помечаются как Invalid.
Как только данные появляются в одном кеше, им назначается статус E:
Ядро забирает эти данные и помещает их в локальный кеш, статус теперь — Shared:
Раз данные в одном кеше изменились, его копии стали неактуальны. Таким образом, в основном кеше у нас статус Modified, а в локальном — Invalid:
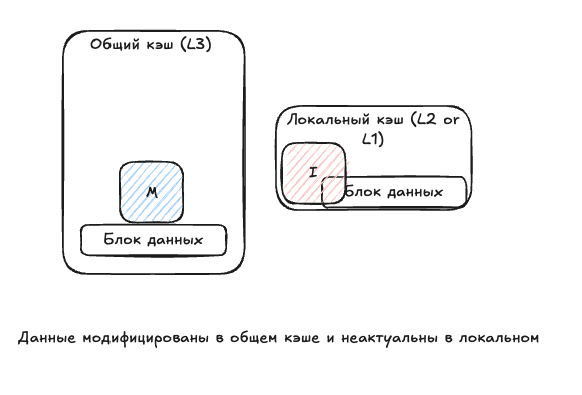
Когда ядро получит новые данные, они снова станут Shared:
С помощью такой модели статусов процессор понимает, можно или нельзя записывать данные в кеши, а также являются ли они устаревшими. Именно поэтому операции записи/чтения меняют состояния данных, которые видимы для всех других потоков со своими кешами.
Заключение
Это статья — введение в многопоточность на аппаратном уровне. В первую очередь она предназначена для разработчиков, которые редко работают с потоками в процессоре напрямую и хотят немного расширить кругозор. А для тех, кто хочет углубиться в аппаратную часть, я рекомендую почитать про SMT и их различия у AMD и Intel — кажется, это будет интересно 🙂
Спасибо за прочтение статьи! Также я веду телеграм-канал Flexible Coding, где рассказываю о своем опыте в программировании!




