Что такое качество данных?
Очевидно, аналитические данные должны как можно более точно отражать действительность. Существует, однако, немало факторов, ухудшающих качество данных и подрывающих доверие к ним. Эти факторы могут быть как техническими, так и организационными, и борьба с ними заслуживает отдельной статьи (даже серии статей). Мы же пока не будем трогать первопричины проблем, а сосредоточимся на их выявлении.
Чтобы отловить изъян в данных, нужно как-то измерить качество данных. Как?
Можно использовать множество метрик качества данных, отсылаю интересующихся к фолианту DAMA DMBOK или чему-то подобному. Среди критериев качества и полнота, и консистентность (согласованность), и актуальность, и уникальность, и допустимость, и много чего еще.
Мы рассмотрим лишь самые простые и автоматически проверяемые условия.
Количество строк
Пожалуй, самый простой способ измерить полноту загружаемых в аналитическое хранилище таблиц — посчитать количество загруженных строк и сравнить с таким же показателем за предыдущие периоды. Механизм не очень точный, конечно, так как сравнение производится не с источником, но зато легко реализуем и при этом позволяет обнаружить существенные проблемы.
Как производится сравнение:
- Для проверяемой таблицы рассчитывается таблица с двумя полями: period — временной период данных, rows — количество строк.
- Rows за последний загруженный период сравнивается с предыдущим либо прямо, либо по среднему или медиане.
- Если сравнение rows выявило сильное отклонение, выходящее за пределы некоторого диапазона, генерируется инцидент.
Поле period требует пояснений. Предположим, мы загружаем каждый день по утрам новые данные за предыдущий день, то есть за вчера.
Если в таблице с проверяемыми данными есть временная метка (например, дата регистрации пользователя), берем ее. Если нет, можно ориентироваться на дату загрузки, если она пишется в сырые данные. В любом случае какая-то дата в сырых таблицах должна быть предусмотрена если не структурой данных, то самим устройством вашего ETL-процесса.
Сравнивать можно rows за день — например, вчерашний день с позавчерашним или вчерашний вторник с предыдущим вторником, а также за несколько дней — например, rows за последние семь дней и за предпоследние семь дней (это позволяет сгладить естественные выбросы).
Юнит-тесты
Позаимствуем этот термин из программирования, где под юнит-тестированием понимают проверку отдельных модулей большой программы. Так же, по частям, и мы будем проверять консистентность наших данных.
Это более кропотливая работа. Требуется сначала выявить зависимости между полями и (или) между таблицами, затем облечь их в конкретные условия. В итоге остается только посчитать количество строк, которые нарушают эти условия. Если 0, то всё в порядке, иначе генерируем инцидент.
Таким образом, мы создаем набор юнит-тестов, каждый из которых проверяет консистентность одного логического правила. Например, дата регистрации юзера должна быть не позже, чем дата его активации.
Механизм проверки
Для автоматизации проверок мы используем тот же инструмент, который загружает данные, — старый добрый Airflow.
Предположим, у нас есть даг, загружающий данные из источников в аналитическое хранилище, за которым следует даг, запускающий обновление витрин данных. Допустим, сырые данные мы проверяем на количество строк, а витрины — на консистентность. Тогда логическая схема процесса выглядит так:
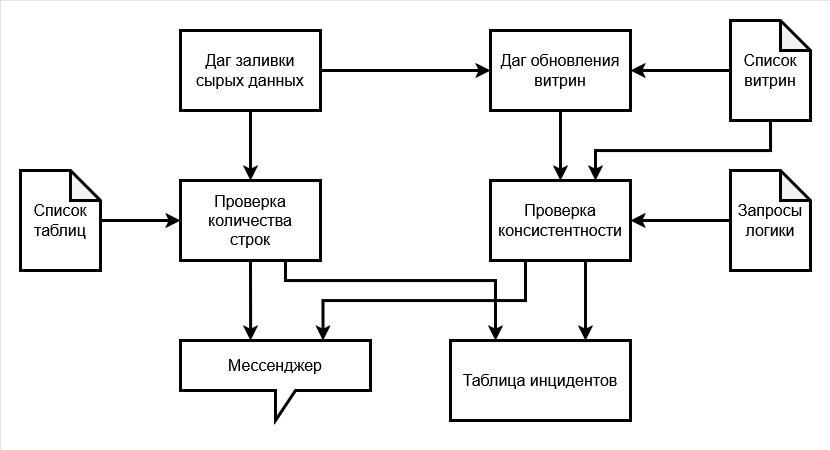
После выполнения таска заливки данных выполняется таск проверки их на полноту. Он выполняет следующее:
- берет имя таблицы и поле с датой из списка и подставляет в типовой SQL-запрос для подсчета количества строк;
- запускает запрос;
- проверяет, входит ли результат в заданный диапазон, и если нет, то отправляет сообщение в корпоративный мессенджер и при необходимости добавляет запись об инциденте в таблицу с инцидентами.
Даг (или таск) обновления витрин запускается, когда сырые данные залиты, то есть после дага заливки. Его задача — перерассчитать витрины с готовыми данными с учетом новых сырых данных. Перечень витрин для обновления подтягивается из соответствующего списка (примерно так, как я писал тут).
За таском обновления витрин (или параллельно ему) можно поставить таск проверки витрин на консистентность. Он получает на вход уже не просто имена таблиц, а запросы, выявляющие строки с нарушенной консистентностью. Эти запросы он запускает и, если обнаруживает непустой ответ, пишет в мессенджер и в таблицу инцидентов.
SQL-запросы
Типовой запрос проверки количества строк на диалекте ClickHouse выглядит примерно так:
SELECT
-- Количество строк за вчера (последний полный день)
COUNT(IF(period = today() - 1, 1, NULL)) AS count_d,
-- Количество строк за предыдущий такой же день недели, как вчера
COUNT(IF(period = today() - 8, 1, NULL)) AS count_w,
-- Количество строк за последние полные 7 дней
COUNT(IF(period > today() - 8 AND period < today(), 1, NULL)) AS count_7d,
-- Количество строк за предпоследние полные 7 дней
COUNT(IF(period > today() - 15 AND period <= today() - 8, 1, NULL)) AS count_7d_prev,
-- Разница в строках между вчерашним днем и предыдущим таким же днем недели
count_d - count_w AS diff_day,
-- То же в процентах
ROUND(100*diff_day/count_w, 2) AS perc_diff_day,
-- Разница в строках между последними 7 днями и предпоследними
count_7d - count_7d_prev AS diff_7days,
-- То же в процентах
ROUND(100*diff_7days/count_7d_prev, 2) AS perc_diff_7days
FROM
(
SELECT toDate({date_field}) AS period
FROM {database_name}.{table_name}
)
Где переменные подставляются из соответствующего списка:
- {database_name} — база данных ClickHouse;
- {table_name} — проверяемая таблица;
- {date_field} — поле с датой.
Результат выглядит приблизительно так:

Дневное приращение строк составило 2,31%, а за семь дней — 3,26%. Допустимый диапазон приращения строк зависит от контекста: какие данные изучаем, насколько их много? Чем больше данных, тем меньше будет флуктуаций, выбросов и тем стабильнее будет разница в строках.
Запросы на проверку консистентности все разные: сколько условий проверяем, столько и запросов. Например, мы хотим убедиться, что для всех пользователей нашего приложения дата активации (то есть первого платежа) всегда не раньше даты регистрации. Такой запрос (или юнит-тест) может выглядеть так:
SELECT 'registrations' AS table_name,
COUNT(DISTINCT user_id) AS users
FROM registrations
WHERE date_activation IS NOT NULL
AND date_activation < date_registration
Если запрос выдает 0 строк, консистентность соблюдена. Иначе генерируем инцидент.
Сигнализация и таблица инцидентов
Результаты проверок отправляются в два канала.
В корпоративный мессенджер (например, Squadus, Slack, Telegram и т. д.) уходят разные типы сообщений: уведомления о ходе проверки, предупреждения, инциденты. Это нужно для оперативного контроля процессов обновления и проверки качества.
В таблицу инцидентов пишутся только достаточно серьезные поломки. Делается это для двух целей.
Во-первых, для ведения истории, которую можно потом проанализировать, чтобы как-то повлиять на первопричины частых проблем.
Во-вторых, на эту таблицу могут смотреть BI-отчеты. При появлении инцидента в отчете появляется соответствующее уведомление для пользователей о том, что данные неполные или вовсе отсутствуют. Уведомление генерируется только для нерешенных инцидентов, помеченных соответствующим флагом (например, поле solved со значением False означает, что инцидент еще не решен).
Резюме
Качество данных должно проверяться автоматически в составе работ по регулярному обновлению данных.
Необходимо проверять как минимум полноту загруженных данных. Самый простой способ — считать количество строк и сравнивать его с предыдущим периодом.
По возможности также следует проверять консистентность (согласованность) данных. Для этого нужно описать правила их взаимосвязи и настроить проверку выполняемости соответствующих условий связанности.
Автоматизацию можно проводить с помощью Airflow. Даги проходятся по списку сырых таблиц и готовых витрин и проверяют каждую на полноту и (или) консистентность. Результаты проверки отправляются в мессенджер и (или) таблицу инцидентов.