

Постановка задачи
Итак, рассмотрим следующую ситуацию. Есть аналитическое хранилище, содержащее широкие витрины данных из десятков колонок. В них собраны разнородные данные, например о клиентах, об их финансовых транзакциях, о маркетинговых активностях, примененных к ним, и так далее.
Доступ конечных пользователей к витринам обеспечивается в том числе напрямую, то есть пользователи могут обращаться к хранилищу через SQL-запросы (или сервисы Self Analytics, которые выполняют запросы от имени пользователей).
Требуется при сохранении структуры данных организовать доступ пользователей только к тем данным, которые им нужны для выполнения своих служебных обязанностей. Например, финансистам нужны данные об оборотах клиентов, но не нужны их контактные данные.
Определяем классы данных
По сути, нам нужно сделать так, чтобы пользователь имел разный доступ к разным колонкам в витринах. В BigQuery существует изящный механизм Policy tags, отвечающий этой потребности. Каждой колонке назначается определенный «тег политики», а к каждому тегу у пользователей устанавливается соответствующий доступ.
Но сначала придется заняться скучным — разделить все ваши данные на классы, то есть выделить все сущности, которые есть в хранилище, сгруппировать их и каждую группу отнести к определенному классу. Ладно, не всё так плохо, можно выделить только классы, к которым следует ограничить доступ, а остальные, «несекретные» данные записать в «общие», то есть доступные всем пользователям хранилища.
Далее нужно обратиться к каждой группе пользователей (или к руководителям групп) и согласовать, какой роли и (или) сотруднику в их командах какие классы данных необходимы для работы. На выходе будем иметь расклад по пользователям или по ролям.
Теги политики (Policy tags)
Теперь, когда мы классифицировали все свои данные, можно назначить соответствующий класс каждому полю. Создадим теги политики: в интерфейсе BigQuery открываем выпадающее меню — BigQuery — Policy Tags.
Откроется страница, где можно создать таксономию (то есть иерархическую структуру) тегов политики доступа. Нажимаем кнопку CREATE TAXONOMY и создаем теги для каждого класса данных, а также подтеги в рамках классов для соответствующих полей (или групп полей) с данными. Вложенность облегчает управление доступом: задав доступы пользователям к тегу класса данных, вы задаете их всем полям класса.
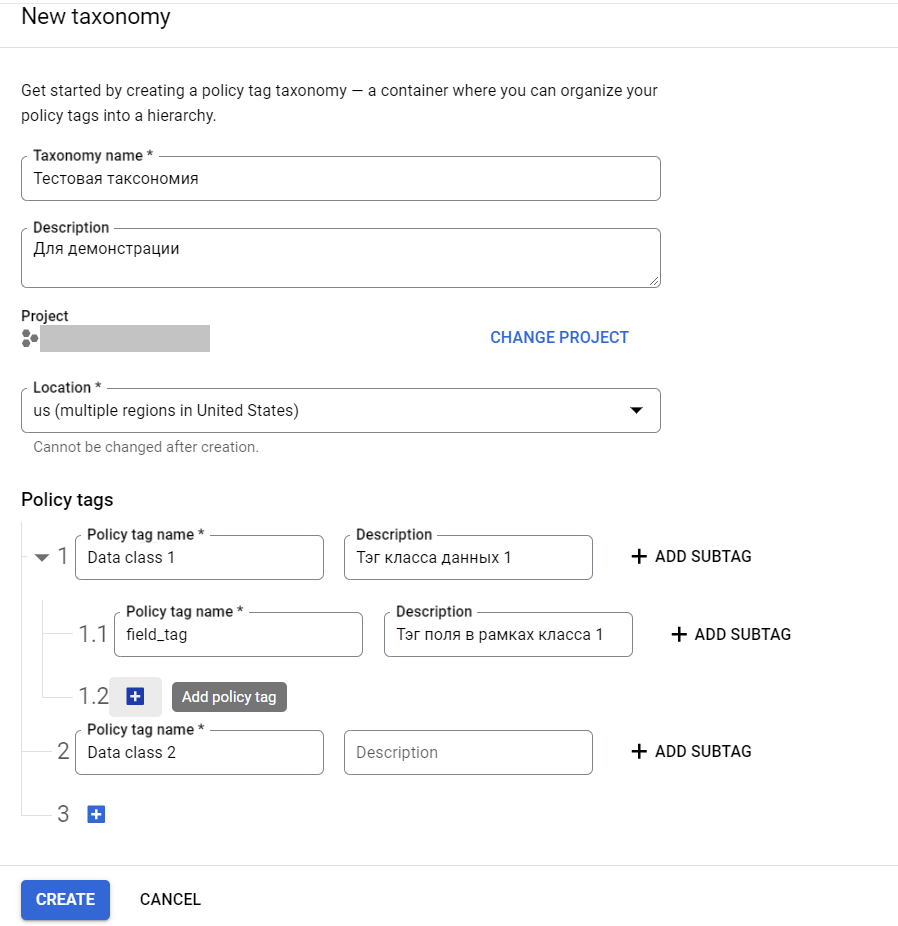
Описав все теги, нажимаем CREATE. Можно создавать несколько таксономий. Например, у нас это выглядело так:
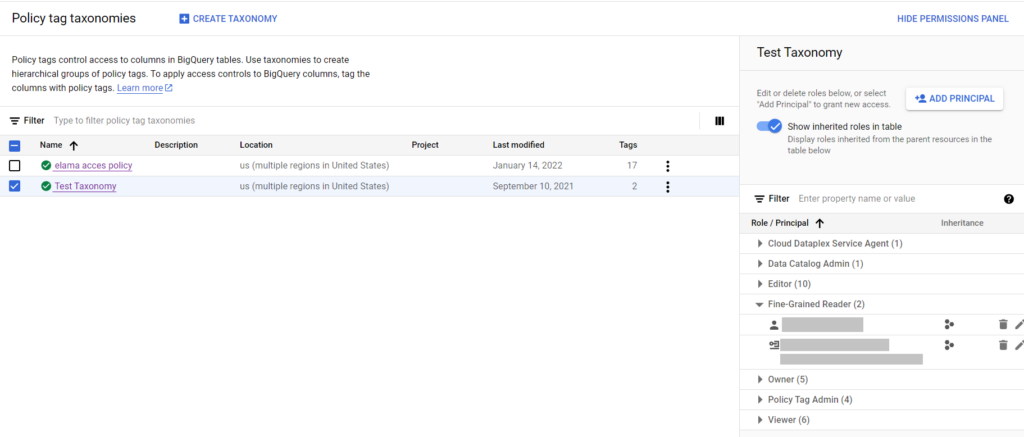
Отметив чекбокс рядом с таксономией, вы откроете в правой панели список ролей, отражающих уровень доступа к ней, и пользователей, которым назначены эти роли. Если панель не открылась, нажмите в правом верхнем углу SHOW PERMISSION PANEL.
Роль, позволяющая пользователю читать поле, называется Fine-Grained Reader, ее достаточно для большинства пользователей. Для добавления пользователю доступа ко всем тегам таксономии отметьте чекбокс рядом с ней и нажмите кнопку ADD PRINCIPAL.
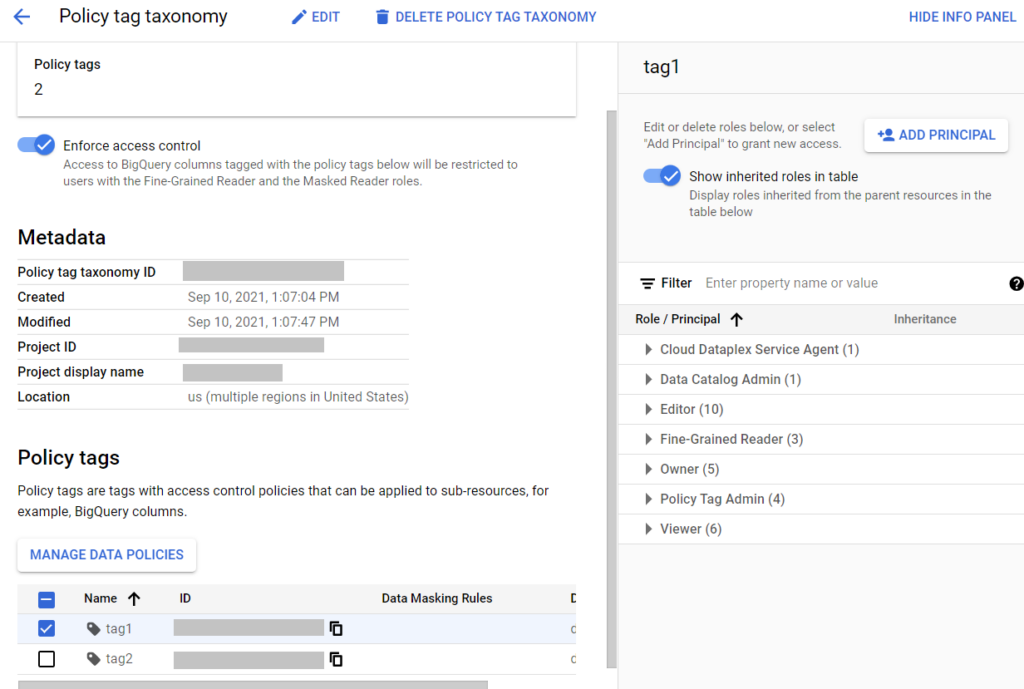
Зайдя внутрь созданной таксономии, вы можете таким же образом задать доступы не на всю таксономию, а только на классы данных или конкретные теги.
Почтовые группы
Если у вашего хранилища данных десятки пользователей, добавление каждому доступа ко всем необходимым тегам может стать довольно трудоемкой задачей. Однако ее могут упростить почтовые группы Google. Дело в том, что почтовой группе тоже можно назначать доступ к тегам политики. Создайте по одной группе для каждого тега, выдайте имейлу группы доступ Fine-grained Reader к соответствующему тегу, а затем добавьте всех юзеров, требующих доступ к тегу, в эту группу.
Чтобы отслеживать, кому какие доступы выданы, удобно использовать таблицу такого вида:
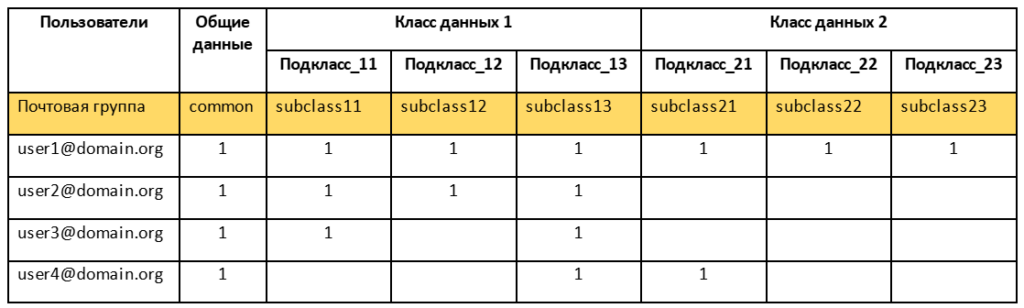
Каждый подкласс в таблице соответствует одному тегу политики, которым помечается одно или несколько полей с одинаковым доступом. Например, данные о финансовой активности клиентов, которые могут состоять из полей: пополнения баланса, переводы, оборот и тому подобное.
В первой колонке содержится список логинов ваших пользователей BigQuery, а в строках проставлены единицы под теми подклассами данных, то есть тегами политики, к которым они должны иметь доступ.
Каждому тегу назначена своя почтовая группа Google (домен опущен для наглядности), именно в нее нужно добавить пользователя, чтобы он получил доступ к этому тегу.
Запись тегов в таблицы BigQuery
Итак, мы разделили данные на классы, создали теги политики и выдали пользователям доступ к этим тегам. Теперь необходимо присвоить теги соответствующим полям таблиц в BigQuery. Плохая новость в том, что при обновлении, то есть перезаписи витрин, все их метаданные, включая теги, слетят. Если ваша витрина, например, раз в сутки перезаписывается в целях обновления данных, то описания полей, как и policy tags, потрутся.
Как автоматически переприсваивать таблицам дескрипшены после обновления, мы уже описывали. Мы использовали Airflow, который в даге обновления отдельным таском брал метаданные из Google-таблицы и писал их в витрины. Доработаем этот механизм для обновления тегов политики так, чтобы, помимо дескрипшенов полей, писались и теги политики.
Справочник тегов политики
Сначала создадим вот такую табличку в Google Sheets:
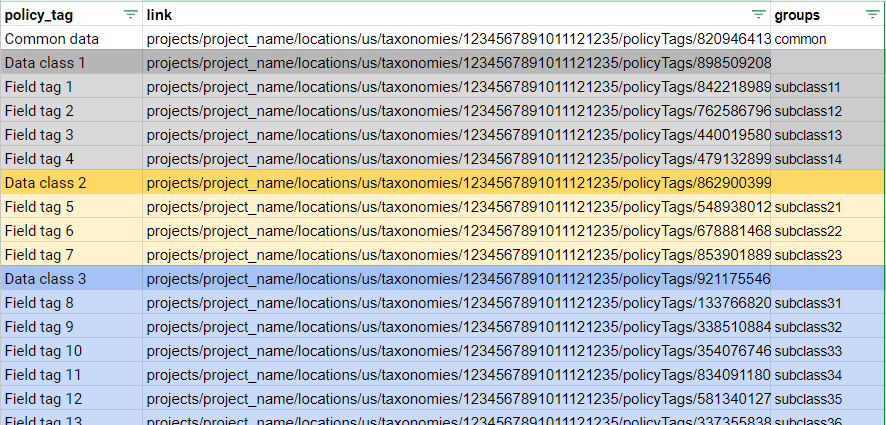
Она содержит:
- policy_tag — название тега (из нашей таксономии);
- link — имя ресурса тега, которое формируется следующим образом:
projects/<имя проекта BigQuery> /locations/us/taxonomies/<id таксономии>/policyTags/<id тега>; - groups — почтовую группу Google (без домена).
Эта таблица послужит справочником для простановки тегов полям, описанным в нашем перечне метаданных (см. статью). Мы расширим этот перечень столбцами с тегами политики:
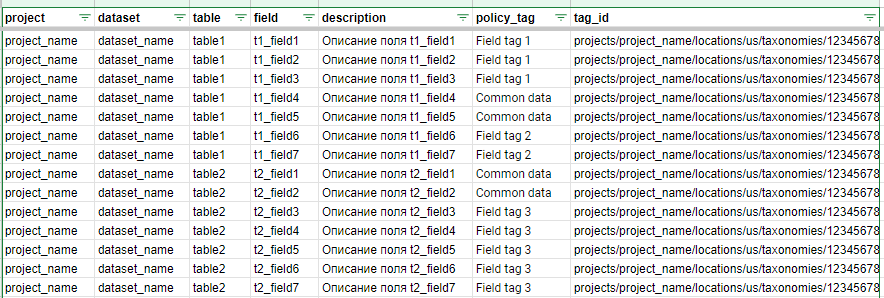
В колонке policy_tag — человекопонятное название тега, которое проставляем каждому полю вручную. Значение колонки tag_id подтягивается функцией ВПР() из справочника тегов с другого листа.
Обновление Policy tags в витринах
Добавим в код функций обновления метаданных присвоение тегов политики. Новый код здесь.
Даг вызова функций обновления метаданных изменится несущественно: просто добавим в его аргументы флаг необходимости обновления тегов политики:
update_bq_metadata = PythonOperator(
task_id='update_metadata_bq.update_bq_metadata',
executor_config=config.K8S_EXECUTOR_CONFIG,
python_callable=update_tables,
op_kwargs={
'sql_metadata': 'update_metadata_bq/sql/bq_dowload_metadata_table.sql',
'project_id': config.BQ_PROJECT_ID_ANALYTICS,
'update_description': UPDATE_DESCRIPTION,
'update_policy': UPDATE_POLICY
},
templates_exts=['.sql'],
dag=dag)
Флаг UPDATE_POLICY может быть задан, например, в конфиге вашего Airflow для указания, следует ли обновлять теги политики или оставлять их в таблицах неизменными. (Флаг UPDATE_DESCRIPTION, в свою очередь, определяет необходимость обновления дескрипшенов полей.)
Резюме
Чтобы задать для пользователей права доступа на отдельные поля таблиц в BigQuery, удобно использовать механизм Policy tags (тегов политики). Для этого выполняем следующее.
- Разделяем все свои данные на классы.
- Создаем таксономию, где прописываем теги для каждого класса.
- Создаем столько почтовых групп Google, сколько у нас тегов.
- Определяем список необходимых классов (а значит, тегов) для каждого пользователя. Добавляем пользователей в соответствующие их тегам почтовые группы.
- Выдаем в таксономии роль Fine-grained Reader почтовым группам для соответствующих тегов.
- Создаем в Google Sheets справочник тегов и таблицу соответствия полей и тегов.
- Создаем даг в Airflow (или другом инструменте автоматизации), обновляющий теги в таблицах с нужной периодичностью.





