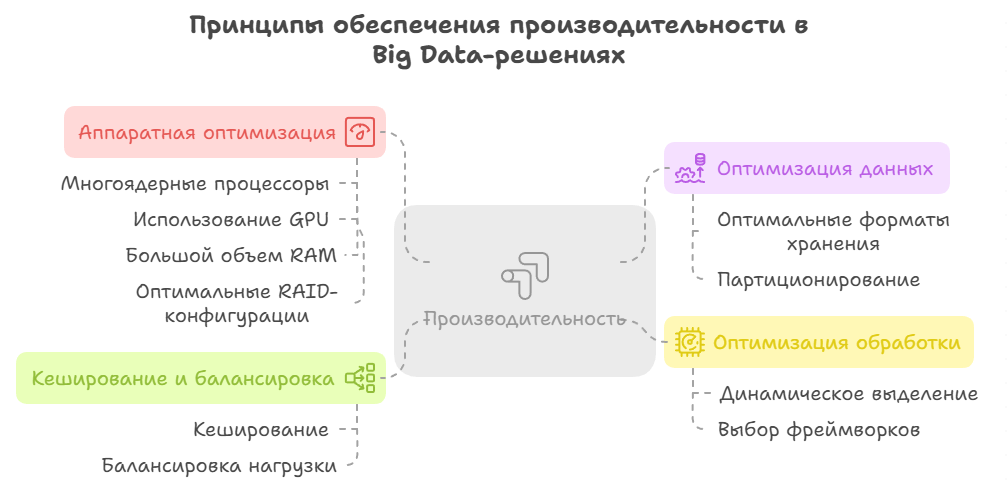
Принципы обеспечения производительности
Для Big Data решений производительность является одним из важнейших критериев. В целом следует отметить, что проектирование высокопроизводительной инфраструктуры для Big Data требует оптимизации на всех уровнях — от железа до алгоритмов.
Ниже представлены ключевые принципы, следование которым позволяет создать систему, обладающую высокой производительностью.
1. Оптимизация на аппаратном уровне, включающая:
- Использование многоядерных процессоров и соответствующе большого объема RAM.
- Использование GPU для ML/DL-задач при оптимальном соотношении CPU к RAM.
- Использование оптимальных RAID-конфигураций.
- Использование выделенных VLAN и RDMA-технологии.
Так, использование многоядерных процессоров позволяет осуществлять параллельную обработку и поддержку векторных инструкций. Использование выделенных VLAN просто необходимо для обеспечения высокоскоростного межсерверного трафика. Кроме того, рекомендуется обратиться к RDMA-технологиям, интеграция которых позволяет обеспечить снижение задержек. Однако всегда следует учитывать, допускает ли бюджет проекта использование оборудования и сетевой конфигурации, необходимых для работы данной технологии.
2. Оптимизация данных, включающая:
- Использование оптимальных форматов хранения.
- Партиционирование при сканировании данных.
В качестве оптимальных форматов хранения можно отметить такие, как колоночные форматы, сжатие, индексация и использование фильтров. Что касается партиционирования при сканировании данных, то здесь общей практикой является партиционирование, в том числе по времени/дате для временных данных, а также по хешу ключа для равномерного распределения.
3. Оптимизация обработки, включающая:
- Реализацию динамического выделения и локализация данных.
- Выбор и настройку фреймворков для партиционирования, сериализации, а также для оптимального размера буферов.
В частности, в целях обеспечения динамического выделения и локализации данных следует размещать задачи обработки рядом с данными, а также объединять файлы в HDFS.
4. Кеширование и балансировка.
Принципы обеспечения отказоустойчивости
Проектирование надежной и отказоустойчивой инфраструктуры для Big Data требует комплексного подхода, учитывающего такие особенности работы данных решений, как распределенность данных, высокая нагрузка и возможные сбои. Вот ключевые шаги и принципы.
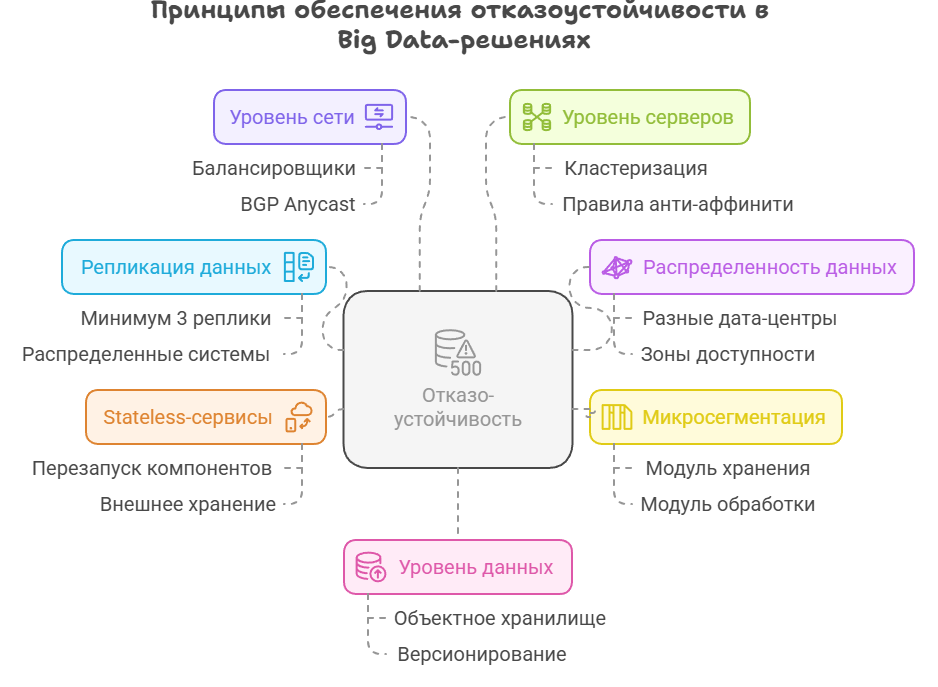
Ключевыми архитектурными принципами, позволяющими обеспечить отказоустойчивость, являются следующие:
- Репликация данных: использование распределенных файловых систем с репликацией данных (минимум 3х).
- Распределенность данных: размещение реплик в разных зонах доступности или разных дата-центрах.
- Микросегментация: разделение инфраструктуры на независимые модули (это могут быть, например, отдельный модуль для хранения данных, отдельный модуль для обработки данных и отдельный модуль для аналитики этих данных), чтобы сбой одного не влиял на другие.
- Реализация принципов stateless-сервисов: обеспечение возможности перезапуска компонентов без потери состояния за счет внешнего хранения.
Кроме того, для обеспечения отказоустойчивых Big Data решений следует обеспечить отказоустойчивость на всех уровнях.
Так, для обеспечения отказоустойчивости на уровне сети следует использовать балансировщики, а также маршрутизацию BGP Anycast для критических сервисов. В свою очередь, для обеспечения отказоустойчивости на уровне серверов требуется кластеризация и применение антиаффинити-правил для размещения серверов в разных стойках.
Наконец, для обеспечения отказоустойчивости на уровне данных необходимо обеспечить возможность проведения регулярных бэкапов в объектное хранилище с версионированием, а также инкрементальных снепшотов.
И конечно же, при проектировании следует обеспечить возможность мониторинга и автоматического восстановления системы.
Принципы обеспечения масштабируемости
Проектирование масштабируемой инфраструктуры для Big Data требует архитектуры, которая способна гибко расширяться, адаптируясь под увеличение объема данных и нагрузки на систему без потери производительности.
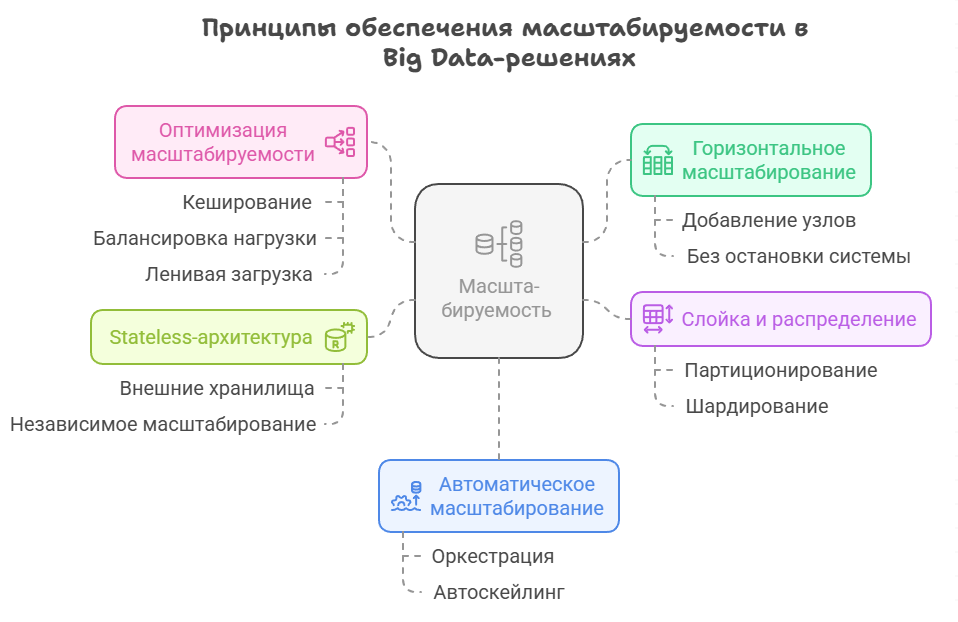
Ключевые принципы обеспечения масштабируемости Big Data решений следующие:
- Горизонтальное масштабирование.
- Разделение на слои и обеспечение распределения.
- Реализация принципов Stateless-архитектуры.
- Обеспечение автоматического масштабирования.
Горизонтальное масштабирование подразумевает добавление новых узлов в кластер вместо увеличения мощности существующих. При этом следует обеспечить возможность добавления этих узлов без остановки системы. Разделение на слои и обеспечение распределения данных и вычислений по узлам реализуется посредством партиционирования или шардирования.
Реализация принципов Stateless-архитектуры, когда состояние выносится во внешние хранилища, позволяет независимо масштабировать сервисы. Наконец, автоматическое масштабирование можно реализовать посредством оркестрации и автоскейлинга.
Кроме того, одним из значимых принципов здесь является принцип оптимизации масштабируемости, который достигается в том числе за счет:
- Реализации кеширования для снижения нагрузки на хранилища.
- Использования балансировщиков для распределения запросов.
- Реализации принципа ленивой загрузки, то есть использование columnar-форматов для чтения только нужных данных.
Принципы обеспечения безопасности
Проектирование безопасной Big Data инфраструктуры требует комплексного подхода. Важнейший принцип здесь заключается в использовании подхода security-by-design, когда защита встраивается на этапе проектирования, а не добавляется постфактум.
Ниже представлены основные принципы, следование которым позволяет обеспечить высокий уровень безопасности такой системы:
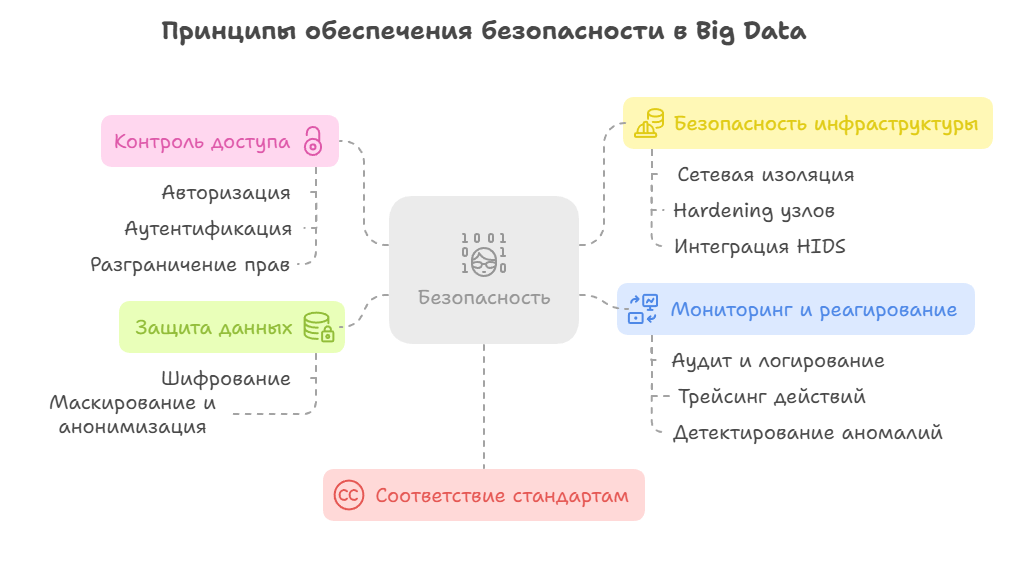
1. Комплексная защита данных посредством реализации:
- Шифрования данных: в движении, в покое (то есть данных на дисках или в базах данных), а также сквозного шифрования, то есть шифрования клиентских данных перед отправкой, а также шифрования ключей.
- Маскирование и анонимизация, включая динамическую маскировку, токенизацию конфиденциальных полей, а также использование математического принципа дифференциальной приватности в аналитике.
2. Реализация контроля доступа посредством:
- Авторизации и аутентификации.
- Разграничения прав.
Одним из надежных решений при авторизации является доступ на основе меток. Для реализации аутентификации используются, как правило, многофакторная аутентификация, ограничение времени жизни токенов при реализации принципа единого входа. Кроме того, для безопасного подтверждения личности пользователей и сервисов в распределенных системах без передачи паролей по сети необходимо использовать сетевой протокол аутентификации Kerberos.
Что касается реализации принципа разграничения прав, то здесь можно отметить такие практики, как настройка ролей и выделение зон безопасности (изоляция продакшена и тестовых сред).
3. Обеспечение безопасности самой инфраструктуры посредством:
- Сетевой изоляции и сегментации сети.
- Реализации принципа Zero Trust.
- Hardening и защита узлов.
- Интеграции HIDS-инструментов.
Обеспечение сетевой изоляции и сегментации сети можно реализовать посредством использования DMZ для шлюзов, приватных подсетей для данных, а также Security Groups/NACLs для AWS или Firewall Rules для GCP.
В целях обеспечения hardening и защиты узлов следует настроить файрвол и отключение ненужных сервисов, регулярно выпускать патчи, а также реализовать принцип минимальных привилегий, при котором пользователи работают с минимально необходимыми правами.
Наконец, интеграция HIDS-инструментов в решение позволит оперативно обнаруживать вторжения на уровне отдельного хоста и осуществлять мониторинг изменений состояния в реального времени.
4. Обеспечение мониторинга и реагирования посредством:
- Аудита и логирования.
- Трейсинга действий.
- Детектирования аномалий, поиска подозрительных паттернов и анализа угроз.
5. Соответствие стандартам (особенно для персональных данных).
Вместо заключения
Несмотря на то что выше шла речь о таких принципах проектирования, которые бы позволили обеспечить отказоустойчивость, масштабируемость, безопасность, производительность, ключевым принципом проектирования Big Data решений (как, впрочем, и любых других ИТ-решений) является принцип тщательного определения и изучения требований.
В этом контексте следует отметить, что прежде чем выбирать конкретные технологии, на которых будет строиться инфраструктура для работы с Big Data, важно четко понимать:
- Объем данных (терабайты, петабайты, потоковые данные).
- Скорость обработки (batch или real-time).
- Типы нагрузок (ETL, аналитика, машинное обучение).
- Требования к отказоустойчивости и SLA (доступность 99,9% или ниже).
И конечно же, важно помнить, что даже лучшие технологии требуют грамотной эксплуатации.