Компания Statanly Technologies занимается разработкой готовых решений и моделей искусственного интеллекта. Одна из основных областей разработки — это компьютерное зрение (computer vision, CV).
Область CV включает в себя задачи, связанные с анализом изображений и видео. Чаще всего это классификация изображений. Например, отличать собак от кошек или машины скорой помощи от пожарных и полицейских. Эти задачи относительно несложные, поскольку классов всего два (кошки и собаки) и много данных.
Еще одной задачей является детекция и сегментация объектов — например, определить местоположение человека на камере или вырезать машину из картинки. Иногда нужно со всех ракурсов определять марку и модель машины, даже по фотографиям отдельных деталей. Тогда в каждом классе получается большое разнообразие объектов, и это усложняет задачу. Если классов очень много и требуется высокая точность, то необходимы еще более тяжеловесные модели.
Для решения этих задач нужны датасеты — размеченные наборы данных, на которых будет учиться модель искусственного интеллекта. Чем больше данных, тем лучше качество модели. После успешного обучения модель можно выводить в продакшен.
Основные задачи продакшена — чтобы все работало качественно и быстро. Достичь обеих целей сложно, поэтому требуется компромисс.
Сколько памяти нужно моделям ИИ для работы и обучения
В области CV суперлегкие модели имеют до 5 млн параметров, легкие — от 5 до 10 млн, средние — от 10 до 50 млн, тяжелые — от 50 до 100 млн, супертяжелые — от 100 млн. Для сложных задач, в которых на вход приходят очень разнообразные данные, подходят тяжелые модели, которые выдают топовое качество и имеют внутри очень много настраиваемых обучаемых параметров. При этом они потребляют много памяти и работают очень долго. Это в большей степени справедливо для текстовых моделей, например GPT — GPT-3, BERT. В области CV это относится к современным генеративным моделям — например, диффузионным моделям Stable Diffusion и DALL-E, и к классификаторам, основанным на архитектуре «трансформер», — например, Vision Transformer и Swin Transformer.
Важно отметить, что количество потребляемой памяти определяет не только сама модель, но и размер входа — количество данных, которое должен обработать алгоритм. Для текстовых моделей это размер текста, для классификаторов изображений — размер картинки.
В свою очередь размер входа влияет на общий требуемый объем оперативной памяти и количество данных, которые мы зараз подаем в модель, — батч (batch size).
Для примера возьмем очень крупную модель ResNeXt101, предназначенную для классификации изображений. На ней картинка со стандартным для этой модели входом 224 на 224 и batch size 32 занимает 2 ГБ оперативной памяти на тестировании. Если мы запускаем 10 таких классификаторов, каждый из которых отвечает за какую-то свою задачу, нужно уже 20 ГБ оперативной памяти GPU.
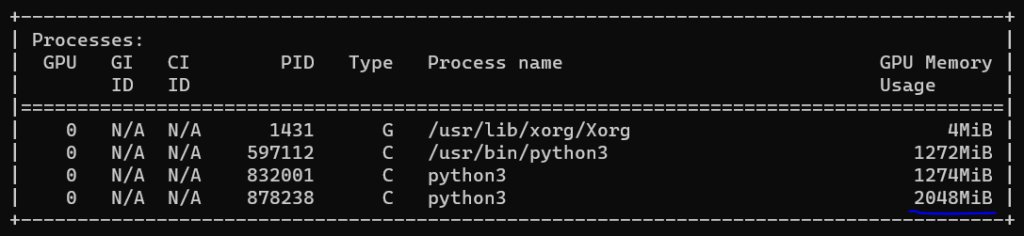
Для запуска в режиме тестирования ResNeXt101 нужны 2 ГБ, но для обучения модели ИИ размер необходимой памяти увеличивается в несколько раз. В случае ResNeXt101 — в 8 раз, то есть до 16 ГБ. Так происходит потому, что во время обучения модели также нужно хранить граф вычислений и считать производные (градиенты), с помощью которых обновляются параметры (веса) нейронной сети.
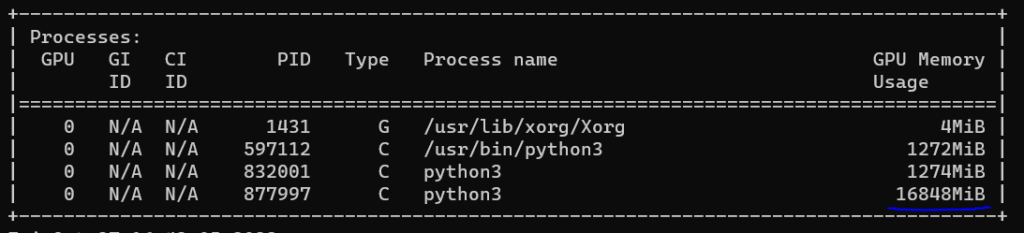
Модель обучается так: через нее проходит наш вход, а мы считаем градиенты, чтобы с помощью градиентного спуска обновлять веса модели — числа, которые были подобраны при обучении. Поэтому дорогие видеокарточки с большим количеством памяти нужны в большей степени для обучения крупных моделей, а затем для запуска на них разных моделей и сервисов.
Также бывают легковесные модели, которые показывают качество пониже, но зато работают очень быстро и не так сильно нагружают систему.
Как тип процессора влияет на работу моделей ИИ
Однако не только выбор модели влияет на скорость работы, но и используемое железо, причем порой даже гораздо больше. Исторически взлет машинного обучения произошел благодаря тому, что люди научились запускать модели машинного обучения на видеокартах (GPU).
Почему так? На самом деле ML-модели внутри себя выполняют на каждый входной объект примерно от 10⁶ до 10⁹ матричных операций, которые на обычном процессоре (CPU) выполняются довольно медленно, так как CPU изначально разрабатываются как универсальные и гибкие инструменты вычислений.
GPU, в отличие от универсальных CPU, изначально проектировались для обработки многомерных изображений, для которой как раз нужны матричные вычисления. Они исполняются с помощью вычислительных блоков, которых в GPU гораздо больше, чем в CPU. Таким образом, нейронные сети довольно успешно можно запускать на GPU.
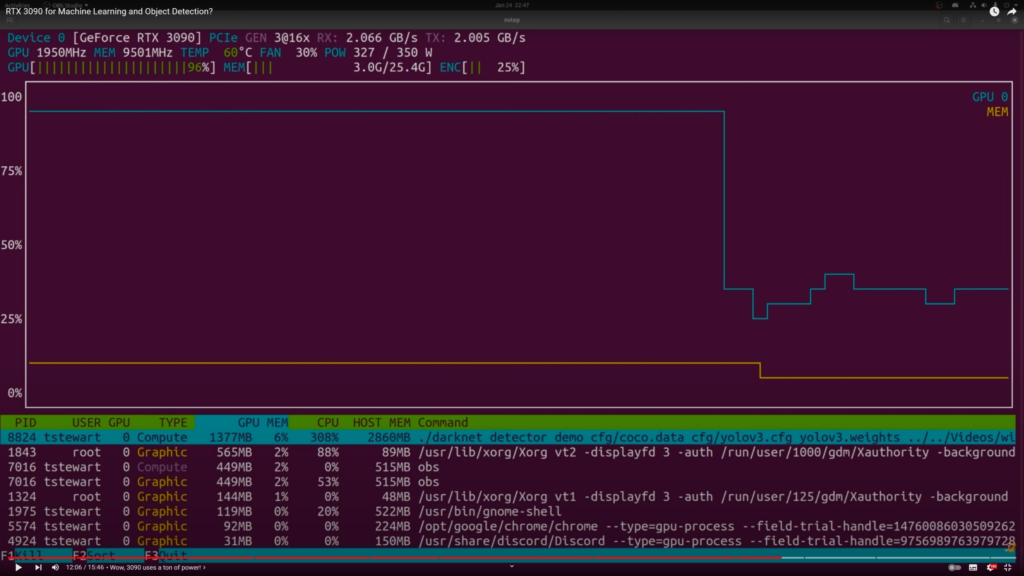
Важные параметры для машинного обучения — размер оперативной видеопамяти и в целом производительность процессора GPU. Крупные ML-модели требуют много видеопамяти. Например, карта RTX 3090 имеет 24 ГБ оперативной памяти и производительность: 35,58 TFLOPS. Это немало, но эта карточка является одной из топовых и стоит от 120 000 ₽.
TPU как альтернатива CPU и GPU
Помимо CPU и GPU, еще есть TPU — тензорные процессоры, которые разработаны специально для максимально эффективного запуска нейронных сетей. При этом они, к сожалению, не умеют ничего другого.
Изначально TPU — это разработка Google, предназначенная для фреймворка машинного обучения TensorFlow. Однако Google не продает своих решений напрямую. Компания всего лишь предоставляет облачный доступ к TPU-серверам по подписке, к которой у россиян нет доступа.
Несмотря на это, свойства облачных решений можно воспроизвести и на физических устройствах. Например, отказоустойчивость облачных решений можно воспроизвести, если купить несколько TPU-серверов.
Мы выбрали в качестве аналога NVIDIA TPU-серверы SOPHON, разработанные в Китае, из-за опыта и профессиональных достижений производителя.
Сравниваем характеристики GPU и китайских TPU
Производительность
Заявляемая производительность устройства SOPHON AI Micro Server SE8-192 — 96 TFLOPS. При этом она рассчитана для вычислений с весами в виде чисел формата float32. Но есть способ еще сильнее ускорить вычисления — использовать числа формата int8. В таком случае производительность вырастет до 192 TOPS.
Особенности конкретных моделей TPU
Приведу пример того, как TPU заточены под работу с нейросетями. Мы разрабатываем для Краснодара систему видеоаналитики и поиска злоумышленников «Умный город», для которой создаем много моделей. Систему еще не выпустили в продакшен, поэтому точно сказать не можем, что нам хватит одного сервера на 192 TOPS SOPHON AI Micro Server SE8-192.
Но есть надежда на это, потому что этот TPU имеет дополнительные вычислительные блоки по декодированию видео и изображений. В результате он умеет обрабатывать 192 видеоканала, то есть можно обслуживать 192 камеры в режиме реального времени.
При этом в обычных GPU гораздо меньше декодеров, поэтому они умеют обрабатывать меньше потоков. RTX 3090 с производительностью 35,58 TFLOPS не умеет обрабатывать 36 каналов.
Цена
Стоимость TPU в целом ниже, чем игровых и серверных GPU. Например, сейчас топовая серверная видеокарта Tesla H100 стоит 4 000 000 ₽.
Более или менее аналогичный TPU стоит чуть более 1 000 000 ₽ и заточен больше под видеоаналитику — то, что нам нужно больше всего для проекта «Умный город».
Сложности в работе с TPU
Когда мы начали работать с TPU, то столкнулись со сложностями.
Не хватает информации и библиотек
Основная сложность с использованием китайских TPU — малое количество доступной информации для разработки ввиду того, что используется новая иностранная технология. Китайцы предоставляют минимальные библиотеки для запуска моделей на TPU, однако они очень низкоуровневые и не позволяют бесплатно адаптировать решение, которое изначально написано для GPU. Поэтому мы создаем свои более удобные библиотеки-обертки на основе китайских.
Перевод чисел float32 в int8, чтобы повысить производительность модели ИИ
Обычно нейронные сети производят вычисления с 32-битными числами в формате float32, но с небольшими потерями в качестве можно обрезать эти числа и получить float16, int8 или даже int4.
Перевод чисел нужен, потому что менее битными числами можно быстрее проводить вычисления и они занимают меньше памяти. При этом чем больше мы обрезаем числа, тем сильнее проседает качество.
Если мы заранее знаем, что будем квантизировать модель, стоит использовать Quantization Aware Training (QAT) — обучение, при котором мы включаем ошибку квантования. Сейчас это наиболее предпочтительный метод для уменьшения потери качества.
Для перехода из float32 в int8 нам нужно подобрать калибровочный датасет, с помощью которого модель подстраивает веса в формате int8, чтобы на этих картинках или текстах из калибровочного датасета получались нормальные результаты. То есть это дополнительная доработка моделей. После этого уже получается квантизованная модель, потому что она была перекомпилирована из float32 в int8.
Важно, чтобы калибровочный датасет был максимально приближен к реальности. Допустим, если мы хотим классифицировать автомобили, а данные приходят с камеры видеонаблюдения, то в калибровочном датасете должны быть картинки желательно с этих камер. Автомобили с выставок для калибровочного датасета в этом случае не подойдут.
Фотографии должны быть мутными и блеклыми, как на обычных камерах видеонаблюдения. Если цель — также получать приемлемый результат на нечетких фотографиях, то они должны быть включены в набор вместе с качественными изображениями.
При этом надо понимать: если в основном данные приходят в виде незашумленных картинок, то качество их анализа просядет, когда мы добавим в набор мутные изображения. В этом случае результат будет лучше, если не включать в набор зашумленные картинки и оставить только изображения хорошего качества.
При обучении датасет тоже должен отражать реальный мир, но калибровочному датасету нужно в еще большей степени соответствовать реальности, иначе модель очень сильно просядет в точности.
Модели, разработанные для GPU, не запускаются на TPU
Китайские библиотеки предоставляют нам низкоуровневые методы для запуска модели. В основном они все написаны на языке C++, а мы разрабатываем модели машинного обучения на Python с помощью фреймворка PyTorch. Чтобы не переписывать весь код на С++, мы решили, что будет удобнее и проще написать обертки над функциями, которые предоставляются китайскими библиотеками.
Мы изучаем документацию, которую предоставили китайцы. Пытаемся понять, какие функции есть, что они принимают на вход, что делают и что отдают. На основании этой информации пишем обертки на Python с помощью специальных фреймворков, которые связывают Python с С++.
Инструкция по переводу на TPU некоторых моделей ИИ, написанных для GPU
Мы сделали инструкцию, которую используем сами. В ней поэтапно рассказано о том, как переписать на TPU некоторые свои модели, написанные под GPU.
Первый этап: экспортируем модель в формат .ONNX. Это общепринятый стандарт для сохранения архитектуры, то есть вызываемых функций и весов модели. Обычно у каждого фреймворка собственный формат, допустим у PyTorch формат .pt, у TensorFlow — .h5 или .tf. Их можно экспортировать в ONNX. В инструкции есть два примера такого экспорта.
Второй этап: для использования на TPU полученную модель в формате .ONNX необходимо скомпилировать в формат .BMODEL. Согласно нашей инструкции, для этого требуется запустить скрипты, в которых нужно указать пути к входным и выходным файлам и путь к калибровочному датасету, если производится квантизация в int8. Результатом компиляции является файл .BMODEL, который для дальнейшего применения нужно скопировать на TPU.
Важно, что стандартные фреймворки, допустим PyTorch, позволяют принимать динамические входные данные различных размеров. Для ускорения работы модели на TPU они компилируются с заранее оговоренным размером входа. То есть мы фиксируем размер батча и размер входного изображения.
Перед запуском модели на TPU необходимо также установить нашу обертку с Python-функциями, вызывающими внутри С++-функции. Прямая установка пока не предусмотрена, но предлагается вариант с кросс-компиляцией библиотеки для получения .so-файла. Сейчас мы автоматизировали кросс-компиляцию для Python 3.8 и 3.9. Для этого требуется запустить желаемый скрипт и после успешной компиляции скопировать на TPU сгенерированный .so-файл в корень вашего проекта. После этого он автоматически будет подтягиваться при импорте библиотеки в Python.
После этого можно подключаться к TPU и запускать модель, используя Python-обертку. Сейчас у нас есть обертка для наиболее популярной модели детектора реального времени YOLOv8 и для простейших классификаторов — обычных PyTorch-моделей. Но существуют и другие фреймворки. Например, MMDetection. Для него мы также планируем в скором времени написать полную адаптацию.