Разработка новых фич в отдельных ветках
Первое требование к качеству продукта — тестирование на всех уровнях. У нас в HFLabs это юнит-тесты в коде, интеграционные автотесты разных уровней, запускаемые при каждом коммите, прогон тестов при сборке билда заказчика, нагрузочное тестирование на выделенном стенде по сценариям, скопированным с боевых сред заказчиков. Но только тестами работа над повышением качества продукта не исчерпывается. Расскажу, что мы еще делаем, чтобы наши приложения работали стабильно и без багов.
Нашему флагманскому продукту — системе класса Customer Data Integration «Единый клиент» — уже 10 лет, и он постоянно развивается. Мы работаем двухнедельными спринтами. Раньше у нас была одна общая ветка, в которой велась разработка по всем новым задачам. В ней же разработчики исправляли баги, запланированные на спринт. Из-за этого создавался хаос, и на этапе тестирования сложно было понять, в чем причина возникновения того или иного бага. Кроме этого, ночные сборки часто роняли тесты, и нужен был отдельный человек, который разбирался, кто именно виноват в упавших тестах, и распределял их починку на того или иного разработчика.
Пару лет назад мы решили поменять этот подход. Теперь каждая новая задача, будь то большая фича или мелкий баг, разрабатывается в отдельной ветке. Это упрощает их тестирование: в «песочнице» мы можем проверить, какие изменения конкретная задача внесла в код, и оценить их. И только после всех проверок мы объединяем изменения, сделанные по конкретной задаче, со всем остальным кодом. Это позволяет нам жить со стабильной trunc-веткой и каждое утро получать стенд, куда установлена версия продукта со всеми последними изменениями.
Контроль за кодом
Мы выполняем автоматическую проверку в инструменте разработки на соблюдение code style. Как известно, большую часть времени разработчик читает код. Code style обеспечивает понятное оформление кода, единую конвенцию наименований функций и переменных, поэтому новые разработчики легче погружаются в продукт. Сама среда разработки не дает программисту закоммитить код, который не проходит проверку. Поэтому кто бы ни вносил изменения, код всегда сохраняет единый стиль.
Помимо проверки code style у нас есть требование указывать задачу, по которой произведены изменения. Когда происходит проблема, мы можем быстро восстановить ход событий — для чего меняли код в этом месте.
Единый code style повышает культуру разработки и эффективность работы программистов. И, в конце концов, с чистым кодом просто приятно иметь дело!
Автоматическая документация
Документация — это тоже часть продукта. Если с ней всё в порядке, это упрощает интеграцию с продуктом и его использование. Скажу честно, что еще пару лет назад у нас были проблемы с актуальностью документации. Бывало, после изменений в коде мы забывали обновить документацию или делали это намного позже. Спасением стала автоматическая документация: теперь она всегда отражает актуальный код и сразу «приезжает» в Confluence.
Дополнительно мы завели глоссарий для наименования полей модели данных. Раньше у разных заказчиков одни и те же поля назывались по-разному, а теперь — одинаково. Так у нас меньше путаницы, и каждый сотрудник при добавлении нового поля не выдумывает для него название, а берет стандартное из глоссария.
Упрощение интерфейсов
Несмотря на то что мы работаем с B2B-клиентами, они также ждут интуитивно понятной работы с приложением. Так что удобный интерфейс — один из показателей качества продукта.
Мы следим за тем, чтобы элементы управления в интерфейсе были единообразными и у пользователя не возникало вопросов, почему в одном месте поиск выполнен так, а в другом иначе. Это упрощает использование продукта.
Большое внимание уделяем максимально гладкому взаимодействию пользователя в фокусе на его основной работе. Ввели запрет на раздражающие поп-апы: теперь приложение предлагает отменить удаление в течение 15 секунд, но не препятствует действиям человека в моменте. По аналогичным соображениям добавили автосохранение изменений. А если какие-то важные изменения нельзя сохранить без подтверждения, то подсвечиваем их и предупреждаем о том, что нужно сохранить вручную при попытке покинуть страницу. На этом моменте пользователь может или подтвердить внесенные изменения, или беспрепятственно покинуть страницу — в этом случае приложение их отменит автоматически.
Такие, казалось бы, мелочи влияют на эмоциональное восприятие продукта. Пользователь может спокойно выполнять необходимую ему работу, а система вежливо помогает ему в этом.
Автоматический сбор информации по проблемам
Качественная IT-система для энтерпрайза — та, что работает без сбоев. Но в реальности сделать продукт, в котором никогда не возникнет ошибок, невозможно. Вопрос в том, что вы будете с этими ошибками делать.
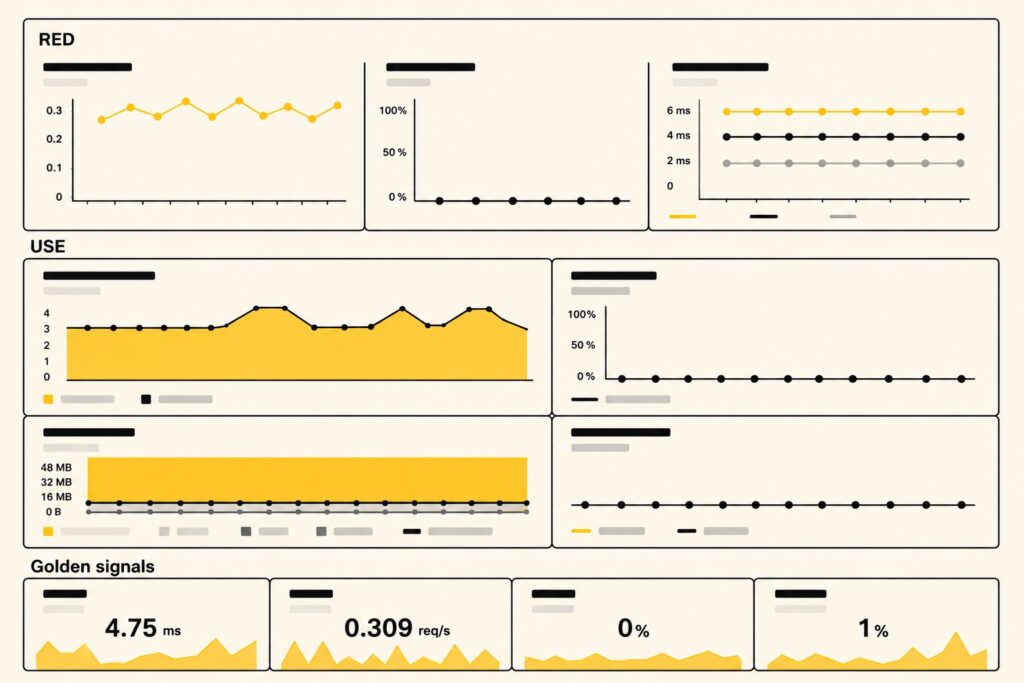
У нас выстроен автоматический сбор логов и статистики работы системы. Это позволяет заметить ошибки раньше, чем это сделает заказчик, а также не допускать падений системы в плане производительности.
- Мониторинг логов происходит на предмет ошибок или необычного поведения системы. Так мы можем заметить, если выполнение той или иной задачи замедлилось. Например, запросы начали выполняться дольше 1 секунды, хотя штатно на каждый из них требуется 200 миллисекунд. В таком случае система сама присылает нам алерт.
- Два раза в сутки мы получаем слепок состояния системы от каждого заказчика, который на это согласился. Это дает нам возможность превентивно бороться с замедлением работы системы, так как обычно снижение производительности происходит постепенно. В таких случаях мы можем, например, подсветить клиенту, что у него количество записей увеличилось с 10 млн до 50 млн, а ночное окно осталось прежним по времени. Или подсказать, что пора обратить внимание на железо.
Автоподнятие среды в случае проблемы
Предыдущим пунктом работа над ошибками в системе не исчерпывается. Допустим, в системе возник сбой. Нужно разобраться, в чем его причина.
Чтобы это сделать быстро, мы запустили автоподнятие среды с версией продукта заказчика и информацией о проблеме. Это нужно для ее воспроизведения на тестовом контуре и создания теста на основе присланных данных.
С помощью телеграм-бота разворачивается стенд, к которому могут подключиться специалисты поддержки и разработчики продукта. Далее этот стенд используем для тестирования: накатываем новую версию, смотрим, осталась проблема или исчезла.
Разделение ядра продукта и конфигураций заказчиков
Этот архитектурный паттерн облегчает тестирование и развитие IT-системы. Кроме того, он позволяет делать качественный продукт, который прекрасно обновляется даже с версии пятилетней давности на актуальную!
У нас есть ядро продукта, которое проверяется на «эталонном» заказчике (внутренняя сборка, эмулирующая типичного клиента), и dev-стенды под каждого заказчика, где разворачивается билд с конкретной конфигурацией, которую он использует. На этих стендах мы тестируем, как будет происходить переход на новую версию приложения, проверяем, правильные ли у нас инструкции для админов, смотрим, как работают разные фичи.
И еще одна фишка для успешного обновления системы. Бесперебойная работа нашего продукта обеспечивается за счет двух серверов (нод) с идентичной функциональностью, которые работают одновременно. Когда приходит время обновления, одна из нод продолжает работать, но при этом становится недоступной для потребителей. Администратор же имеет возможность провести необходимые действия по обновлению. Затем то же самое он может сделать и со второй нодой.
Иногда нам нужно что-то поменять в продукте, и мы подозреваем, что это может повлиять на интеграции. По возможности мы делаем все наши изменения обратно совместимыми и всегда обязательно предупреждаем заказчиков о том, какие изменения произойдут.
Взаимодействие поддержки и разработчиков
Хочу поделиться и организационными моментами, которые помогают нам поддерживать качество продукта. Во-первых, у нас есть единая система учета всех заявок, которые поступают в поддержку по разным каналам — от почты до Телеграма. Так ни один тикет не остается без внимания команды.
Во-вторых, есть четко организованный саппорт. Все наши специалисты поддержки понимают, как работает продукт, разбирают логи, смотрят конфигурации, воспроизводят проблемы. Если их знаний оказывается недостаточно, они передают исследование разработке, где есть выделенные дежурные специалисты. Они могут сразу же приступить к исследованию проблемы и не только быстрее помочь заказчику в моменте, но и найти фундаментальное решение для устранения причины проблемы.
Вместо резюме
В заключение скажу, что к текущему состоянию мы пришли не сразу. И если вы всерьез озабочены качеством продукта, начать стоит с простых вещей — code style, устранения самых раздражающих моментов в интерфейсе, выделения помощи поддержке. Далее можно автоматизировать рутинные вещи: поднятие стендов для воспроизведения проблемы, автоматический сбор информации для исследования проблемы, автоматизацию документации.
Настройтесь на то, что всё это небыстрые процессы. Документацию мы автоматизируем уже три года и сделали только половину из того, что нам хочется. Аналогично и со стендами для поддержки: начали с того, что собирали минимально необходимую информацию (версии приложения, ОС, параметры железа), и постепенно расширяли этот набор. Научились в чистую базу заливать слепок данных для воспроизведения проблемы, а потом уже поднимать всё приложение в Docker автоматически. Затем прикрутили телеграм-бота, которому можно «скормить» архив с данными, а он сам развернет среду. Когда перестало хватать одного стенда, сделали пул стендов и очередь, за которой следит тоже телеграм-бот.
В общем, мой совет — начинать с простого, двигаться итерационно и не бояться экспериментировать и предлагать нововведения соседним командам (поддержке, разработке).