S3 или HDFS?
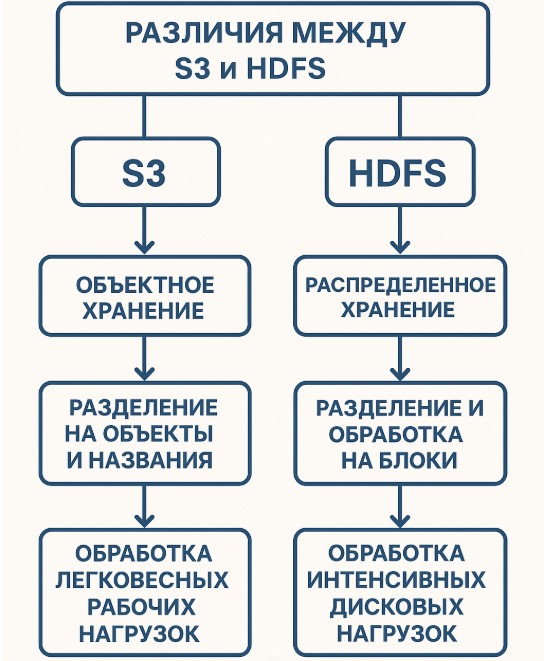
Если позволите, расскажу, что я вкладываю в эти понятия со своей колокольни. S3 — это объектное хранилище. Представьте огромный склад, где вещи (данные) лежат в отдельных ячейках (объектах) и у каждой есть свой уникальный адрес. Достать нужную «коробку» можно быстро по этому адресу, но заглянуть внутрь и поменять что-то по частям — задача нетривиальная. Вы либо берете весь объект целиком, либо кладете новый. Зато такой склад практически безграничен: добавляй сколько хочешь, провайдер (облачный сервис) позаботится о том, чтобы места хватило всем и ваши данные не потерялись, — он хранит копии, распределяет их между дата-центрами, следит за сохранностью.
HDFS, напротив, напоминает мастерскую с собственным складом при ней. Это распределенная файловая система: файлы режутся на блоки и раскладываются по множеству узлов-«полочек» (серверов) внутри кластера. За порядком следит главный распорядитель (NameNode), который помнит, где что лежит. Если один «стеллаж» выходит из строя, ничего страшного — данные дублируются в нескольких экземплярах по разным узлам, так что система устойчива к поломкам отдельных серверов.
HDFS создавался для того, чтобы данные хранились рядом с вычислениями: там же, в кластере, работают Hadoop, Spark и другие инструменты, которым важна скорость доступа. Проще говоря, HDFS хорошо умеет кормить данными тяжелые аналитические «мельницы» напрямую с места хранения, минуя узкие места вроде сетевых каналов наружу.
Интересно, что изначально эти подходы росли в разных областях. HDFS родом из мира больших данных: в начале 2010-х, если у тебя Hadoop, то и данные по умолчанию живут в HDFS. S3 же пришел из облаков: Amazon придумал его для универсального хранения чего угодно — от фотографий котиков до бэкапов корпоративных баз.
Со временем миры, конечно, столкнулись: Hadoop научился подключаться к S3, а объектные хранилища стали стремительно набирать популярность для аналитики (вспомним модный теперь термин Data Lake, подразумевающий именно хранение сырых данных в объектном виде). Однако, несмотря на эту взаимную интеграцию, разница философий осталась. Поэтому так часто звучит вопрос: а что нужнее — максимальная производительность на вычислительных задачах или гибкость и простота в управлении данными?
Гибкость vs скорость
Я вижу эту дилемму с двух сторон. Со стороны бизнеса и клиентов всё выглядит просто: хочется надежное хранилище, чтобы данные были доступны всегда, чтобы масштабировалось без головной боли и не требовало армии инженеров для поддержки.
В этом плане простоты использования S3 почти идеален: вы складываете данные, а о внутренней кухне думает облачный провайдер. Не нужно ставить и настраивать сервера, следить за NameNode, расширять кластер вручную — достаточно отправить файлы в облако. Более того, объектное хранилище разворачивается сразу на всю компанию: им могут пользоваться разные команды, приложения, внешние сервисы через API, нет жесткой привязки к одному кластеру или технологии. Гибкость и простота использования — огромный плюс для компаний, у которых нет цели самой заниматься железом.
Но есть и другая сторона медали, о которой нельзя забывать. Стоит ли любому большому проекту сразу бежать в объектное хранилище? Не всегда. Например, когда речь о крайне интенсивной обработке данных, высокой частоте чтения и записи или о специфических требованиях к согласованности данных в реальном времени, старый добрый HDFS может выступить лучше. Он находится близко к вычислениям, практически внутри них — а значит, и скорость обработки заметно выше.
Когда у вас сотни узлов прожевывают терабайты информации, им важнее минимальная задержка и гарантия, что данные на диске доступны мгновенно и последовательно. HDFS обеспечивает эту предсказуемость: если файл записан, все узлы кластера сразу знают о нем. Если нужно быстро прочитать гигантский массив данных, кластеру не надо тянуть его по сети извне — всё уже локально, на своих узлах или соседних. Кроме того, HDFS исторически заточен под потоковую запись больших файлов и пакетное чтение: ему не очень нравятся миллиарды крохотных файлов, зато выдайте ему несколько сотен больших — и он отработает бесперебойно.
Примеры из практики
Один из наших клиентов хранил огромные архивы данных — буквально десятилетия статистики, логов и резервных копий. Объемы росли, и держать всё это на собственных серверах становилось накладно и рискованно. Мы предложили вынести архивы в объектное хранилище. Решение оказалось удачным: исторические данные перекочевали в облако S3, где им обеспечена надежность (копии, геораспределенность) и при этом оплата идет «за фактическое потребление». Клиент избавился от головной боли, связанной с железом и администрированием HDFS-кластера, и смог сосредоточиться на анализе свежих данных, зная, что архив в безопасности и доступен по запросу.
А вот другой случай: стартап, работающий с VR- и 3D-контентом. Они каждый день генерируют терабайты сырых видеозаписей и телеметрии с устройств виртуальной реальности. Им нужно не просто хранить эти данные, но и в режиме, близком к реальному времени, обрабатывать их: строить модели, анализировать, применять машинное обучение для улучшения опыта пользователей.
Такой ворох данных они сначала пытались складывать в облако, но быстро уткнулись в ограничение по скорости отдачи при анализе. Решение пришло в виде собственного Hadoop-кластера на платформе Облакотеки: данные текущего дня собирались в HDFS, и все вычислительные задачи крутились прямо там, без лишних задержек.
Уже обработанные результаты и исторические пласты данных они выгружали обратно в объектное хранилище — для долговременного складывания и чтобы при необходимости делиться с другими сервисами. В итоге получилось выжать максимум из обеих технологий: горячие данные день в день живут в HDFS ради скорости, а всё, что стало неактуальным, переезжает в S3, где экономично и удобно хранится сколько угодно долго.
Что в итоге
Таких историй много, и вывод всегда один: не существует универсального чемпиона, который побеждает во всех номинациях. S3 и HDFS не заменяют друг друга, а дополняют. Выбор зависит от стоящих перед вами задач. Объектное хранилище станет надежным фундаментом для провайдера услуг или компании, которой важна масштабируемость, простота и широкий доступ к данным. HDFS-кластер может стать эффективным инструментом, если у вас внутри есть мощная экспертиза в Big Data и задачи, требующие максимальной скорости на уровне хранения. А иногда лучший подход — сочетать оба варианта, как это сделали наши коллеги из примера: использовать сильные стороны каждой технологии.
Лично мой подход как руководителя — всегда искать способ, как решить проблему оптимальнее. S3 и HDFS — как разные инструменты в арсенале: молоток и отвертка. Иметь под рукой оба и понимать, когда какой применять, куда ценнее, чем пытаться выбрать что-то одно. В конце концов, технологии существуют для того, чтобы служить нашим целям, а не наоборот.