Выбор метода обучения
Чтобы ИИ был способен к анализу и распознаванию естественного языка, его необходимо этому научить, как, например, младенца — держать ложку. В качестве метода обучения искусственного интеллекта я рассматривала глубокое и машинное обучение, а также корпусную лингвистику.
Как можно понять из названия метода, используя корпусную лингвистику, вы предоставляете ИИ огромное собрание текстов на разные тематики. Чем больше объем, тем «умнее» будет интеллект. Вот только у данного подхода есть минус: прямая зависимость от качества и количества текста. Если так выйдет, что в текстах ни разу не упоминается буква «ь», интеллект и вовсе не узнает о его существовании.
Значит, будем добиваться результатов при помощи глубокого обучения, которое, кстати, основано на нейронных сетях. Именно нейросети позволяют сделать искусственный интеллект отражением человеческого мозга. Благодаря нейросетям в голове мы способны применять дедукцию и не наступать на одни и те же грабли. Правда, нейронные сети трудно сделать совершенными. ИИ, обученный этим методом, не склонен к забыванию информации. Если представить ему понятие, имеющее несколько значений и зависящее от контекста, в одном из определений, при столкновении с этим понятием ИИ будет подразумевать единственное имеющееся его значение, из-за чего происходит путаница и не всегда выдаются корректные ответы на заданные вопросы.
В таком случае мы выбираем использовать наиболее эффективный метод машинного обучения для обеспечения работы искусственного интеллекта. ML имитирует то, как люди учатся в образовательных учреждениях: школах, колледжах, университетах и так далее, поэтому этот способ «воспитания» ИИ подходит лучше всего. Сначала — наблюдение, получение опыта, инструкций по нахождению закономерностей в данных. Затем — последующая коррекция поведения в похожих ситуациях. В точности как человек методом проб и ошибок учится жизни.
В силу того, что мне, как начинающему разработчику, пока что знакомы только базовые функции распространенных языков программирования, я выбрала Python — один из наиболее легких языков программирования. Благодаря простоте использования и краткости команд его легко изучать новичкам. Также этот язык считается наиболее популярным для разработки ИИ, поэтому я остановила выбор на нем.
Определение конкретной задачи
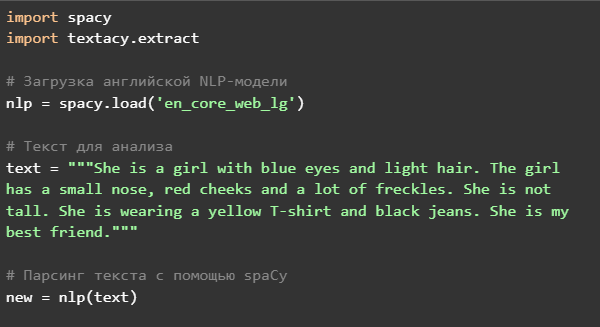
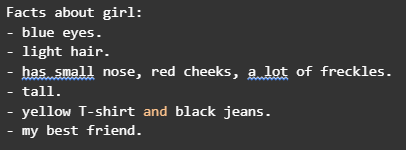
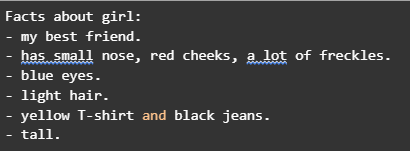
Чтобы ИИ научился генерировать собственные тексты, нужно сначала научить его разбираться в уже существующих. Первая задача искусственного интеллекта будет состоять в формулировании выводов на основе некоторого комментария. Например, мы предоставим ИИ отрывок текста: She is a girl with blue eyes and light hair. The girl has a small nose, red cheeks and a lot of freckles. She is tall. She is wearing a yellow T-shirt and black jeans. She is my best friend.
Теперь нужно сделать так, чтобы ИИ смог выделить и вывести основные факты из текста. Необходимо заметить, что это лишь первые шаги на пути к достижению масштабной цели: реализации искусственного интеллекта для создания новых шедевров в стиле великих классиков литературного искусства.
Рабочий процесс
Человеку проще понять единственное высказывание, одиночную мысль, чем сразу делать выводы на основе целого параграфа. Поэтому прежде всего ИИ должен разделить текст на отдельные предложения. В отрывке их пять:
- She is a girl with blue eyes and light hair.
- The girl has a small nose, red cheeks and a lot of freckles.
- She is tall.
- She is wearing a yellow T-shirt and black jeans.
- She is my best friend.
Так как иногда предложение целиком анализируется тяжело, мы разделим каждое на слова — это называется токенизация. На этом шаге создается массив данных, пополняющийся каждый раз, когда встречается пробел.
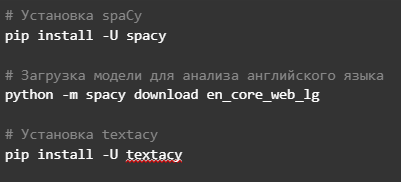
Далее запрограммируем ИИ анализировать слово и относить его к определенной части речи: girl — существительное (noun), yellow — прилагательное и так далее. Для реализации этого процесса в Python есть библиотека spaCy, а в ней уже имеется специально обученная модель en_core_web_sm. Однако, прежде чем приступать к группировке слов по частям речи, необходимо произвести лемматизацию — приведение слова к его начальной форме.
После завершения лемматизации междометия, предлоги, союзы и другие похожие части речи не несут в себе смысловой нагрузки, поэтому можно их вовсе удалить.
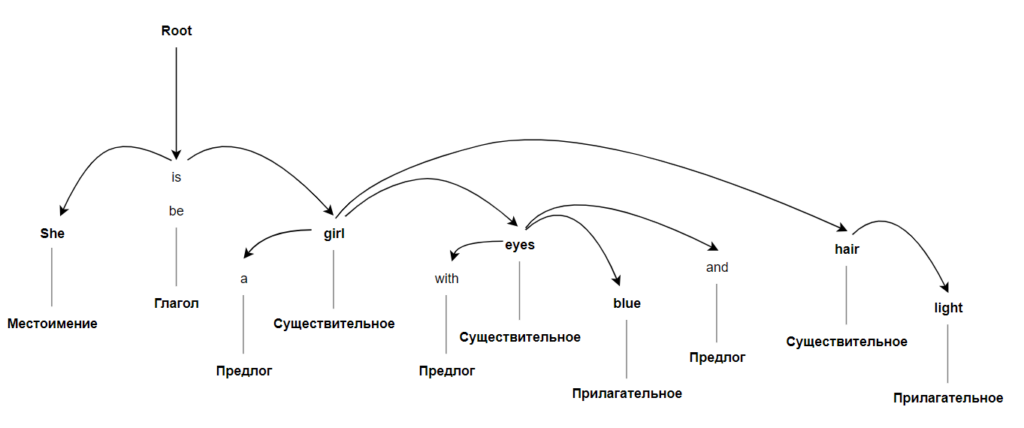
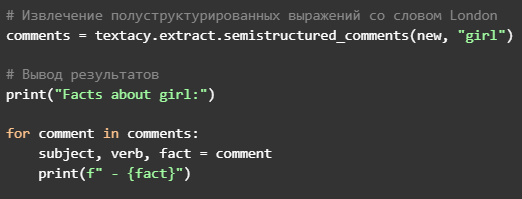
Наконец, ИИ готов к парсингу, то есть определению зависимостей. Машине необходимо найти взаимосвязь между полученным набором слов, чтобы составить представление о тексте и о том, как с ним работать. Результатом парсинга является дерево, в котором каждая форма имеет единственного «родителя», а также определены типы связи между словами.