Машинное зрение в ретейле: от распознавания объектов до анализа возраста
К нам нередко поступают любопытные запросы, и один из них касался именно разработки нейросети, которая может отличить совершеннолетнего человека от несовершеннолетнего. К слову, никакими готовыми наработками по распознаванию возраста мы на тот момент не обладали, но тема нас увлекла. В этой статье я расскажу, как происходил сбор датасета, зачем в него попали аниме-девочки и обезьяньи морды и какие результаты мы в итоге получили.
Почему бизнесу это важно
Нейросети, определяющие возраст, дают множество преимуществ:
- В ретейле они помогают соблюдать законодательство при продаже алкоголя, табака или ограниченной продукции.
- В рекламе обеспечивают доступ только для 18+ аудитории.
- В системах контроля — от клубов до казино — снижают очереди и повышают безопасность.
- На онлайн-платформах поддерживают безопасность и модерацию контента.
Эти решения не только уменьшают риски и оптимизируют процессы, но и улучшают пользовательский опыт.

Сбор датасета
Любая нейросеть для видеоаналитики (или компьютерного зрения) нуждается в большом объеме данных для обучения. Нужно четко понимать, какой искусственный интеллект планируется создавать. Если открытые базы готовых данных отсутствуют либо не совпадают с вашим запросом, без собственной разметки и формирования датасета не обойтись.
В нашем случае заказчик обозначил очень узкую цель — распознать совершеннолетних. Для этого потребовалось собрать два набора данных:
- Обучающий датасет с фотографиями людей разных возрастов.
- Обобщающий датасет, в котором оказались фотографии аниме-персонажей и обезьян.
Чем шире и необычнее подборка, тем лучше обобщающая способность нейросети. Чем более разнообразные образы мы «скармливаем» алгоритму, тем точнее он впоследствии определяет цель, даже если сталкивается с обстоятельствами, не встречавшимися на этапе обучения.
Разнообразие данных усиливает обобщающую способность: модель лучше справляется с шумом, вариациями освещения и нештатными входящими данными. Мы специализируемся на сложных задачах видеоаналитики, где требуется глубокая экспертиза в данных. Например, в одном проекте мы собирали датасет с имитацией оружия для распознавания угроз, а в другом фиксировали уличные инциденты для анализа поведения.
Что такое обобщающая способность нейросетей? Представьте: вы учите компьютер отличать кошек от любых других объектов. Показав ему десятки или сотни фотографий котов, вы обучите компьютер видеть ключевые признаки кошки. Однако, если вы добавите снимки собак, птиц и рыб, компьютер научится общим паттернам распознавания всех животных и лучше выделит уникальные характеристики кошек. Аналогичным образом мы расширяем «кругозор» нашей нейросети, погружая ее в самые разные примеры.
Тестирование модели
Когда требуется понять, насколько эффективна нейросеть, распознающая возраст, мы погружаемся в тесты. Этот этап показывает, правильно ли мы выбрали подход к разработке с самого начала.
- Визуальные отчеты. Алгоритм автоматически строит графики по итогам каждого теста. Это удобно: вся команда разработчиков видит, что пошло не так и где ожидаются потенциальные баги.
- Мониторинг продакшен-серверов. Мы следим за загрузкой процессора, сетевой активностью, использованием оперативной памяти и диска, а также за метриками API.
- Автотест из 23испытаний. Он каждые 15 минут запускается через GitLab Pipeline schedules, результаты фиксируются в Prometheus/Grafana, а в Телеграм уходит уведомление, если что-то пошло не так.
Сначала у нас был единый телеграм-канал для уведомлений о состоянии dev-сервера и продакшен-сервера. Но мы быстро поняли: когда тесты падают на dev, это может быть нормой из-за новых фич, а вот если ошибка на продакшен-сервере — будем реагировать молниеносно. Именно поэтому каналы разделили.
Матрицы конфузий и отчеты Allure
В результате тестов формируются:
- матрица конфузий с промежутками 5 лет в абсолютных значениях;
- нормализованная матрица конфузий с промежутками 5 лет;
- график «Реальный возраст — Предсказанный возраст».
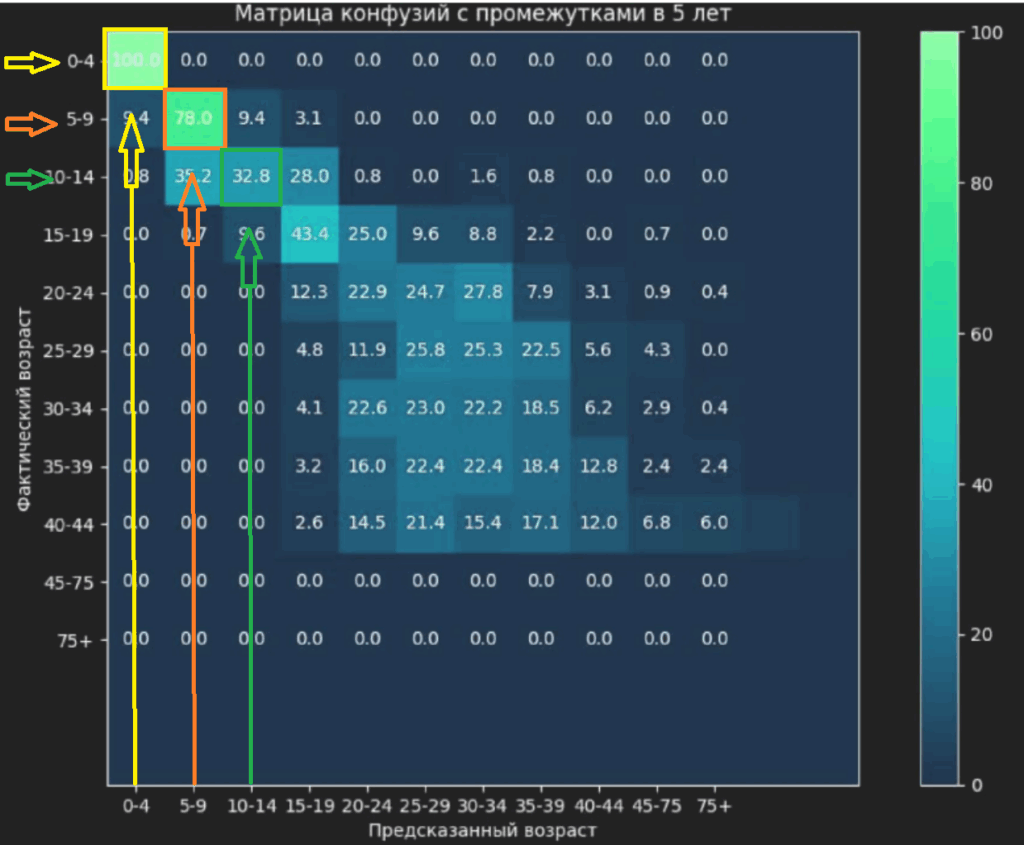
Что такое матрица конфузий? Это таблица, наглядно показывающая, куда «сместились» прогнозы модели: сколько раз она угадала класс, а сколько ошиблась. Строки обычно отображают реальный класс, а столбцы — предсказанный. Для задач по распознаванию возраста так легко увидеть, где именно модель допустила неточность. Спойлер: в конце статьи вы увидите матрицу конфузий по этому проекту 🙂
В отчете Allure можно увидеть, сколько раз нейросеть правильно определила совершеннолетних/несовершеннолетних, а где дала сбой: например, низкое качество фото, несколько лиц на одном снимке, отсутствие человека в кадре. По итогам тестирования нейросеть успешно справилась с 1820 тест-кейсами, что соответствует 80,32% точности.
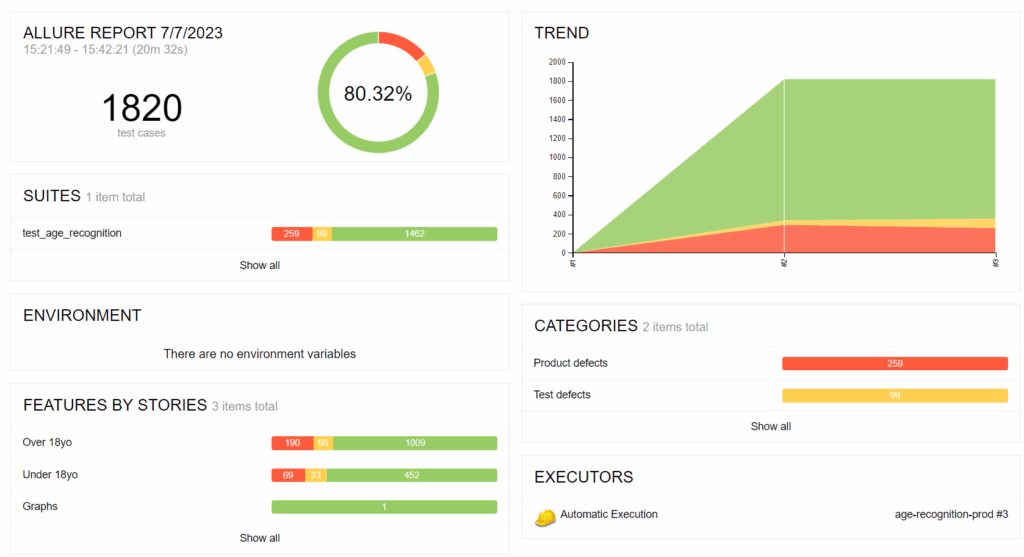
Для чего используется Allure? Allure-отчеты визуализируют результаты тестов. Они дают подробное описание по каждому тестовому шагу и позволяют разработчикам оперативно понимать, где именно вернулась ошибка. Дополнительные метаданные (теги, описания) помогают структурировать тестовую документацию, а значит, упрощают анализ.
Все эти детали позволяют анализировать каждый отдельный сбой: мы видим реальный возраст, предсказанный возраст и причину пропуска. Можно сделать срезы: какие случаи «падали» в предыдущем запуске, но вдруг стали зелеными сейчас. Или наоборот. Такой подход помогает нам своевременно улучшать модель и повышать точность распознавания возраста.
Результаты
Матрица конфузий наглядна: если число в ячейке близко к 100%, значит, модель хорошо определила возрастную группу. Но основная задача была отсеивать несовершеннолетних и не давать им «18+». И вот некоторые итоги:
- Ни одного младенца нейросеть не признала совершеннолетним.
- В группе 5–9 лет отсутствуют ложные «18+».
- В группе 10–14 лет в 3,2% случаев модель ошиблась и назначила «18+».
Итоги тестирования
Тестирование — это ключевой этап, позволяющий оценить реалистичность и пригодность разработанной модели для выполнения поставленных задач. Конкретно для нашей модели, распознающей возраст, результаты оказались следующими:
- Мы проводили автотесты каждые 15 минут на серверах, результаты которых фиксировались в системах мониторинга.
- Алгоритм результативно преодолел 1820 из 2265 тест-кейсов, что составило 80,32% качества распознавания.
Особая задача, стоявшая перед нашей командой, заключалась в том, чтобы минимизировать количество ошибок именно в возрастной категории 15–18 лет. Вот как модель справилась с этой группой: в 4,3% случаев возраст был предсказан неверно. Это немного выше общего среднего значения. Эти ошибки были связаны в основном с качеством снимков и неоднозначностью внешнего вида некоторых тестируемых (например, подростки с нехарактерным для их возраста макияжем или стилем одежды). Мы продолжаем совершенствовать эту зону модели благодаря дополнительным данным.
Вывод
На финальном этапе проектирования система была внедрена в сети партнеров, торгующих товарами возрастного ограничения. Что это изменило?
- Сокращение времени проверки паспортов на кассах на 45%.
- Снижение количества штрафов на 22% по сравнению с ручной проверкой.
- Повышение отзывов — клиенты отметили ускорение операций и меньшее число конфликтов в случаях неверного определения возраста сотрудником.
Этот кейс по распознаванию возраста — лишь один пример, подробнее о наших подходах к видеоаналитике можно узнать на сайте или в телеграм-канале. В мире, где технологии эволюционируют быстрее, чем мы успеваем адаптироваться, видеоаналитика на базе ИИ становится не просто инструментом, а настоящим катализатором трансформации бизнеса. Мы в NeuroCore строим как раз такие системы, которые становятся мостами между сырыми данными и реальными результатами для бизнеса.