Иллюзия ясности: что есть что на самом деле
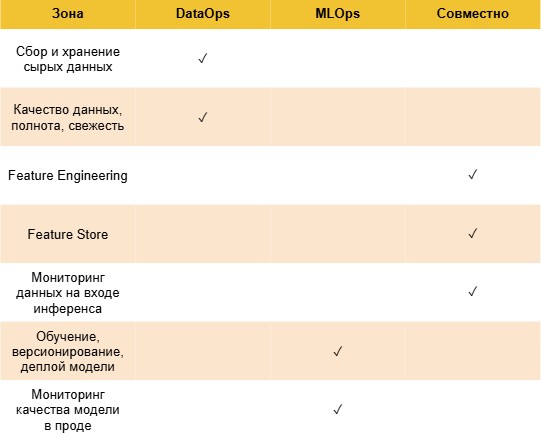
По своей сути DataOps — это DevOps для данных. Его цель — обеспечить скорость, качество и надежность доставки. Это CI/CD для пайплайнов, версионирование датасетов, тестирование на полноту и свежесть. Зона ответственности DataOps заканчивается там, где данные загружены в хранилище или переданы потребителям. Для DataOps модель — это черный ящик, который просто потребляет данные.
MLOps, в свою очередь, занимается инженерией жизненного цикла моделей. Это воспроизводимые эксперименты, автоматизация обучения, деплой и мониторинг качества предсказаний. MLOps принимает данные как данность. Откуда они взялись и как были очищены, часто остается за скобками.
Концептуально граница проходит между статусом «фичи готовы» и «обучение началось». В идеальной картине мира DataOps готовит чистые, версионированные данные в Feature Store, а MLOps забирает их для обучения. Но именно здесь идеал сталкивается с реальностью.
Feature Engineering: главный камень преткновения
Преобразование сырых данных в признаки требует понимания и данных, и модели одновременно:
- Data-инженер не знает, какие преобразования нужны модели.
- ML-инженер не знает, что возможно сделать с данными и какова их природа.
В итоге Feature Engineering либо делает ML-инженер сам поверх сырых данных (дублируя трансформации, не договариваясь с DataOps), либо это «ничейная земля».
Feature Store является архитектурным решением для этой проблемы: единый репозиторий признаков, которые вычисляются один раз, хранятся и переиспользуются для обучения и инференса.
Это снимает сдвиг между обучением и продакшеном — одну из самых частых и незаметных причин деградации модели в проде. Сдвиг возникает, когда признак при обучении вычислялся одним способом, а при инференсе (расчете от ML-модели) — немного другим: разные библиотеки, разные версии трансформаций, разное время выполнения. Модель при этом ведет себя непредсказуемо, и воспроизвести проблему крайне сложно.
Пограничные зоны и кто ими владеет
Типичные ошибки внедрения: где ломаются процессы
На организационном уровне компании часто бросаются в крайности. Первая: все в одной команде. Это работает только на старте, пока в проде не более 3–5 моделей. Дальше начинается хаос: инциденты разбираются в режиме «выясняем, чья вина», а не «чиним быстро». Вторая крайность: жесткое разделение без общего SLA и определения качества. Конфликт «плохие данные» против «плохой модели» не имеет механизма разрешения, и каждый инцидент превращается в политическое противостояние.
Технические процессы страдают не меньше. Частая проблема: разные версии преобразований данных. Обучение и инференс работают на разных версиях трансформаций без единого паттерна. Рано или поздно это приводит к необъяснимой деградации. Решением становится либо внедрение Feature Store, либо явное версионирование трансформационного кода с фиксацией версии при деплое.
Связанная с этим ошибка — отсутствие метрики качества данных «в конце пайплайна». DataOps считает работу завершенной, когда данные загрузились в таблицу, а MLOps уверен, что качество данных — не его проблема. В итоге сдвиг между обучением и продакшеном и тихая деградация модели живут месяцами, пока не станут критическими.
Сюда же относится утечка данных (data leakage), когда в обучающую выборку попадают признаки, которые в реальном инференсе недоступны или вычисляются некорректно. Модель показывает неправдоподобно высокое качество на валидации, а в проде — значительно хуже. Частый случай: в фичи попадают признаки, которые на инференсе приходят позже, чем нужен ответ модели, или информация из будущего относительно момента предсказания. DataOps здесь часто ни при чём: это ошибка на этапе Feature Engineering, которая живет до первой серьезной оценки в проде.
Не менее опасны ошибки в постановке целей и управлении релизами. Классический случай: оптимизация метрики вместо бизнес-результата. Модель обучают на accuracy или AUC, получают хороший результат на валидации и деплоят. В продакшене оказывается, что техническая метрика не коррелирует с тем, что важно бизнесу. Например, модель прогнозирует отток с высокой точностью, но большинство «предсказанных» клиентов всё равно бы не ушли даже без вмешательства. Удержание таких клиентов стоит дороже, чем отсутствие действий. Корень проблемы в том, что метрика выбирается без участия бизнеса и без связи с реальным решением.
Наконец, часто игнорируется безопасность релиза. Модель выкатывают в прод без определенного порога, при котором нужно откатиться на предыдущую версию. Когда качество падает, команда начинает обсуждать, что считать «довольно плохим», уже в режиме инцидента. Это типичная ошибка первого деплоя: процедура отката (rollback) не прописана, потому что все были уверены, что откатываться не придется. Часто отсутствует и baseline: модель соотносят саму с собой на тестовой выборке, но не сравнивают с простым базовым уровнем — например, с правилом, средним значением или предыдущей версией системы. В итоге непонятно, насколько ML реально лучше более дешевого решения, что создает проблему при оценке ROI и обосновании затрат на дорогостоящую ML-инфраструктуру.
Зрелая конфигурация: как должно быть
Зрелая конфигурация при критичном ML и долгоживущих моделях определяется не столько набором инструментов, сколько качеством договоренностей между командами. Фундаментом становится явный контракт на границе DataOps и MLOps. Это не только схема данных, но и SLA на свежесть и полноту, а также прописанная процедура действий при нарушении контракта. Без этого команды остаются один на один с проблемами, не имея механизма разрешения конфликтов вида «плохие данные» против «плохой модели».
На практике контракт должен быть операциональным, а не декларативным. Схема с типами полей — это только начало. Нужны конкретные пороги: «не более 3% null в поле X», «признаки поступают не позднее 15 минут после события», «разрыв в поставке данных не превышает одного часа». Контракт должен иметь версию: мажорная версия означает критическое изменение и требует совместного ревью перед внедрением. И главное — контракт должен проверяться автоматически при каждом запуске пайплайна, а не только в момент первоначального согласования. Документ, который не верифицируется кодом, перестает быть контрактом и становится артефактом прошлого.
Технически эту связку должен поддерживать единый слой признаков — Feature Store, или версионированный репозиторий трансформаций, который используется одинаково и при обучении, и при инференсе. Это дополняется сквозным мониторингом: данные и модель должны быть видны в едином контексте, а не разнесены по разным дашбордам, где невозможно отследить причинно-следственные связи деградации.
Если полноценный Feature Store организационно недостижим, минимально работающий вариант выглядит так: версионированный репозиторий трансформаций, где каждый признак имеет описание, владельца и changelog, а при деплое модели в ее метаданные прописывается точная версия трансформаций. Это решает training-serving skew (проблему различия данных при обучении и при использовании модели в продакшене) без отдельного инфраструктурного продукта. Для мониторинга принципиально не красота дашборда, а то, что в одном месте видны сразу null rate и свежесть на входе инференса, PSI относительно референса, распределение предсказаний, бизнес-метрика. Референсное окно при этом нужно явно обновлять при каждом переобучении, иначе спустя несколько месяцев любое распределение будет выглядеть «задрейфовавшим» просто потому, что референс устарел. Если для расследования инцидента нужно открывать два разных дашборда, это уже не техническая проблема, а организационная.
Наконец, критична безопасность процессов. Необходима четкая процедура эскалации: если качество входных данных проседает ниже порога, система должна автоматически сигнализировать об этом, позволяя заморозить обновление модели, или переключиться на fallback. Всё это работает только при наличии регулярных точек взаимодействия между командами, где не только разделяются зоны ответственности, но и пересматриваются контракты по мере развития продукта.
Всё это должно быть зафиксировано в runbook — не как принцип, а как набор конкретных параметров. Его ключевые элементы фиксируются до деплоя: список критических признаков, пороги срабатывания по каждому из них, автоматические действия при нарушении, например пауза батч-инференса или переключение на fallback и маршрут оповещений. Деление на «критические» и остальные — не техническая, а договорная задача. Не всё требует одинакового SLA, и это разграничение лучше сделать спокойно до деплоя, чем выяснять в момент инцидента. Для реального времени минимальная конфигурация — это shadow mode: новая версия модели работает параллельно с действующей, и при аномальном распределении предсказаний трафик автоматически возвращается назад.
Регулярные точки взаимодействия имеют конкретный формат. Раз в месяц инженерное ревью контракта — не управленческое совещание, а разбор метрик за период, обсуждение изменений и того, что контракт не предусмотрел. После каждого значимого инцидента — совместный разбор, где анализируется не только что сломалось, но и какие допущения в контракте оказались неверными. Именно через постмортемы контракт эволюционирует. Без них он застывает и перестает отражать реальность — ровно так же, как модель, которую перестали переобучать.
Вместо заключения
Граница между DataOps и MLOps проходит там, где заканчивается работа с данными как активом и начинается работа с моделью как продуктом. Но эта граница проницаема: ключевые зоны вроде Feature Store требуют совместного владения и явных контрактов на качество.
Зрелость процесса начинается не с инструментов, а с договоренностей. Когда команды согласуют SLA на входе и метрики успеха на выходе, исчезает почва для конфликтов. В противном случае вы рискуете получить дорогую инфраструктуру, которая не приносит бизнес-ценности, и команду, которая вместо развития продукта занимается поиском виноватых.