Проверка на дубли
Для разогрева начнем с простого. Посчитаем количество повторяющихся сочетаний имени и фамилии в таблице с данными о людях (например, актерах).
SELECT CONCAT(first_name, ' ', last_name) AS fio,
COUNT(*) AS c
FROM actors
GROUP BY 1
HAVING с > 1Последний элемент в исторических данных
Если имеем дело с таблицей, которая обновляется не перезаписью с нуля, а добавлением новых строк для объектов, которые изменились, вот как можно взять последнюю строку:
SELECT *
FROM
(
SELECT *
MAX(updated_at) OVER (PARTITION BY payment_id) AS last_update
FROM payment
)
WHERE updated_at = last_update
Здесь payment — таблица, содержащая транзакции пользователя. Одна строка отражает состояние транзакции на момент добавления строки, т. е. на дату updated_at. Каждая транзакция имеет уникальный идентификатор payment_id, но он не уникален в рамках всей таблицы.
Сводные таблицы
Предположим, у нас есть таблица с фильмами, где для каждого из них имеется столбец release_year с годом выпуска и length с длительностью в минутах. Мы хотим подсчитать количество фильмов до 90 минут, до 120 минут и более 120 минут.
Когда нужно подсчитать суммы или количество величин из разных категорий, содержащихся в одном столбце, можно делать так:
PostgreSQL
WITH films AS
(
SELECT 2006 AS release_year, 86 AS "length"
UNION ALL
SELECT 2006 AS release_year, 180 AS "length"
UNION ALL
SELECT 2006 AS release_year, 95 AS "length"
UNION ALL
SELECT 2006 AS release_year, 135 AS "length"
UNION ALL
SELECT 2006 AS release_year, 120 AS "length"
UNION ALL
SELECT 2007 AS release_year, 85 AS "length"
UNION ALL
SELECT 2007 AS release_year, 130 AS "length"
UNION ALL
SELECT 2007 AS release_year, 120 AS "length"
UNION ALL
SELECT 2007 AS release_year, 97 AS "length"
)
SELECT release_year,
SUM(CASE WHEN "length"<90 THEN 1 ELSE 0 END) AS less_90 ,
SUM(CASE WHEN "length">=90 AND "length"<120 THEN 1 ELSE 0 END) AS less_120,
SUM(CASE WHEN "length">=120 THEN 1 ELSE 0 END) AS over_120
FROM films
GROUP BY 1
-- GROUP BY ROLLUP (1) -- добавляет в конец строку с итогом
ORDER BY 1
ClickHouse
В Кликхаусе есть более изящная функция для подсчета по условию — countIf():
SELECT release_year,
countIf("length"<90) AS less_90 ,
countIf("length">=90 AND "length"<120) AS less_120,
countIf("length">=120) AS over_120
FROM films
GROUP BY 1
ORDER BY 1
Постфикс -If можно добавлять и к другим агрегирующим функциям.
BigQuery
Если категории уже определены и содержатся в строках, то в BigQuery есть специальный оператор для создания сводных таблиц. Например, у нас есть данные о количестве продаж фильмов и значение квартала продажи (здесь может быть и просто дата) в отдельном столбце. Чтобы вынести каждый квартал в свой столбец, используем код:
with films AS (
SELECT 'Film 1' as film, 51 as sales, 'Q1' as quarter UNION ALL
SELECT 'Film 1', 91, 'Q2' UNION ALL
SELECT 'Film 1', 45, 'Q3' UNION ALL
SELECT 'Film 1', 3, 'Q4' UNION ALL
SELECT 'Film 2', 77, 'Q1' UNION ALL
SELECT 'Film 2', 0, 'Q2' UNION ALL
SELECT 'Film 2', 25, 'Q3' UNION ALL
SELECT 'Film 2', 2, 'Q4'
)
SELECT * FROM
(
SELECT film, sales, quarter FROM films
)
PIVOT(SUM(sales) FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4'))
Сравнение таблиц
Я уже писал о том, как проверять свои витрины, сравнивая новую версию с предыдущей. Простой, но очень удобный прием — использовать EXCEPT DISTINCT:
CREATE TABLE t1 (a Integer, b varchar(255));
INSERT INTO t1 (a, b) VALUES (1, 'a'), (2, 'b'), (3, 'c'), (6, 'f');
CREATE TABLE t2 (a Integer, b varchar(255));
INSERT INTO t2 (a, b) VALUES (1, 'a'), (2, 'b'), (4, 'c'), (5, 'd');
(
SELECT 'old vs new' AS _type, *
FROM t1
EXCEPT DISTINCT
SELECT 'old vs new' AS _type, *
FROM t2
)
UNION ALL
(
SELECT 'new vs old' AS _type, *
FROM t2
EXCEPT DISTINCT
SELECT 'new vs old' AS _type, *
FROM t1
)
ORDER BY b, _type;
Заполняем пропущенные даты
Для многих задач обработки временных рядов (например, прогнозирования) важно, чтобы не было пропусков дат. Но входные данные зачастую этим грешат. Это можно чинить с помощью генератора дат:
PostgreSQL
SELECT date_paid, IFNULL(amount, 0) AS amount
FROM
(
SELECT gs::date AS date_paid
FROM generate_series('2005-05-24', '2005-08-23', interval '1 day') as gs
) AS dates
LEFT JOIN
( -- данные о платежах с пропущенными датами
SELECT DISTINCT DATE(payment_date) d,
SUM(amount) AS amount
FROM payment
GROUP BY 1
) AS p ON p.d = dates.date_paid
ORDER BY 1
BigQuery
Генерация ряда с датами с 2024-01-01 по вчера:
SELECT ds
FROM UNNEST(GENERATE_DATE_ARRAY('2024-01-01', CURRENT_DATE() - 1, INTERVAL 1 DAY)) AS ds
ClickHouse
В Кликхаусе всё несколько хитрее:
SELECT arrayJoin(
arrayMap(
x -> toDate(x),
range(
toUInt32(toStartOfDay(toDate('2024-01-01'))),
toUInt32(now() + toIntervalDay(1)),
24 * 3600
)
)
) AS ds
«Уплощение» таблиц
Предположим, в таблице films есть поле special_features, содержащее массив дополнительных материалов к фильму:
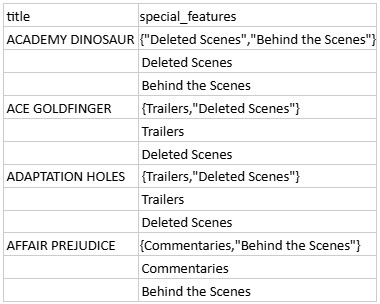
Мы хотим «уплощить» этот массив, т. е. сделать так, чтобы на каждую строку приходилось только одно его значение. Используем код:
PostgreSQL
SELECT title,
UNNEST(special_features) AS feature
FROM films
ClickHouse
SELECT title,
arrayJoin(special_features) AS special_features
FROM films
BigQuery
SELECT title, sf
FROM films, UNNEST(special_features) AS sf
WHERE 1=1 для отладки
Напоследок маленький совет, как сделать отладку запроса чуть удобней. Когда тестируем витрину и смотрим результат при разных условиях, можно добавить WHERE 1=1, а со следующей строки ставить AND и любые другие условия. Тогда всё, что после 1=1, можно спокойно убирать/добавлять, не заботясь о том, что забыли закомментировать какой-нибудь AND:
SELECT *
FROM datamart
-- Отладочный фильтр:
WHERE 1=1
--AND a='x'
--AND b=3
AND d>='2024-01-01'Резюме
Мы рассмотрели советы о том, как облегчить работу с SQL в некоторых случаях:
- Проверка на дубли
- Вывод последней строки в исторических данных
- Создание сводных таблиц в PostgreSQL, ClickHouse, BigQuery
- Сравнение таблиц и вывод различающихся строк
- Заполнение нулями пропущенных строк во временном ряду
- «Уплощение» таблиц, содержащих массивы в полях, для PostgreSQL, ClickHouse, BigQuery
- WHERE 1=1 для удобства отладки витрин