Задачи тестирования
Итак, у нас есть два сценария тестирования:
- Доработка существующей витрины. Чаще всего при этом нужно либо добавить новые поля, либо с некоторого момента изменить логику имеющихся. Большая часть данных в исходных полях при этом не меняется.
- Создание новой витрины. В этом случае создается новая логика. Сравнить результат можно только с источником данных, обработанным по той же логике.
Покажем типовые шаги, которые мы применяем в обоих случаях.
Тестируем доработанную витрину данных
Первым делом важно убедиться, что в тех фрагментах витрины, которые не должны измениться, столько же строк, сколько в исходной витрине. Если строк больше, скорее всего, возникли дубли — например, из-за новых джойнов. Тогда следует обратить внимание на новые подзапросы и проверить, сколько строк выдается по полям, по которым происходит джойн.
Если строк больше, но дублей нет, нужно проверить, что значения старых полей за старые периоды не изменились. Это легко сделать, используя запрос с объединением типа EXCEPT DISTINCT. Оно позволяет вывести все строки первой таблицы, которых не нашлось во второй. Чтобы увидеть значения различающихся столбцов обеих таблиц, можно найти сначала отличия исходника от новой витрины, затем отличия новой от исходника — и объединить результаты. Шаблон запроса примерно такой:
(
SELECT "new vs old" AS _type, a, b, c
FROM new_table
EXCEPT DISTINCT
SELECT "new vs old" AS _type, a, b, c
FROM old_table
)
UNION ALL
(
SELECT "old vs new" AS _type, a, b, c
FROM old_table
EXCEPT DISTINCT
SELECT "old vs new" AS _type, a, b, c
FROM new_table
)
ORDER BY a, b, c, _type
Поле-маркер _type поясняет, что с чем мы сравниваем. В списке сравниваемых полей a, b, c мы оставляем только те, которые не должны измениться при доработке витрины.
Если в новой витрине появились новые строки, они выведутся со значением _type равным new vs old. Если значения в полях a, b, c изменились, то на каждую изменившуюся строку выведется пара строк с обоими маркерами — new vs old и old vs new, в которых мы увидим новые и старые значения соответственно. Если какие-то строки пропали, они отобразятся с маркером old vs new.
Добавленные поля, а также измененную с некоторого момента логику старых полей следует тестировать отдельно, так как со старым значением их не сравнишь. Методика здесь такая же, как для проверки витрин, создаваемых с нуля. Рассмотрим ее далее.
Тестируем вновь созданную витрину
В этом случае также важно проверить, нет ли дублей. Готового эталона для сравнения у нас нет, поэтому мы посчитаем строки с группировкой по составному ключу — набору полей, который должен быть в этой витрине уникальным.
SELECT a, b, c, COUNT(a) AS row_count
FROM new_datamart
GROUP BY 1, 2, 3
HAVING row_count > 1
Разумеется, так можно выявить дубли, только если в витрине нет агрегации. Иначе может выйти, например, так: один из столбцов выведет сумму по составному ключу, все строки будут уникальными, но если в агрегируемых строках затесался дубль — сама сумма задвоится. Именно поэтому дубли следует искать в каждом подзапросе витрины, а также после их объединения, но до агрегирования.
Помимо дублей, в новоиспеченной витрине могут встретиться дефекты трех видов:
- строка из источника попала в выборку, в которую не должна была попасть;
- значения расчетных столбцов неправильные;
- строка не попала в выборку, а должна была.
И вот как их можно отследить.
Находим лишние строки
Чтобы выявить строки, которые должны были отфильтроваться, можно выставить условия фильтрации, противоположные тем, что указаны в техническом задании (ТЗ). При этом, как и в случае с дублями, следует искать их до агрегации.
Допустим, по ТЗ нам нужно посчитать пользователей, заплативших за месяц не менее 10 000 рублей. Тогда вместо подсчета юзеров мы можем вывести все строки, которые будут считаться, и добавить условие с «инвертированным» требованием из ТЗ:
--SELECT COUNT(user_id) AS — для конечной витрины
SELECT user_id, monthly_turnover — для тестирования
FROM
(
SELECT user_id,
SUM(sum_paid) AS monthly_turnover
FROM user_transactions — таблица с транзакциями пользователей
GROUP BY 1
-- HAVING monthly_turnover >= 10000 — предположим, что это условие мы забыли указать при разработке витрины
) AS u
WHERE monthly_turnover < 10000 — для тестирования
Такой запрос не только покажет нам все строки, которые не должны были просочиться в результат, но и подскажет место, где следует искать ошибку: нужно лишь найти, где вычисляется проверяемая метрика.
Если витрина содержит множество подзапросов, проверить стоит каждый из них, а также итог каждого нового объединения.
Находим неверные значения
Чтобы проверить правильность значений расчетных столбцов, нужно прежде всего четко сформулировать ТЗ — конкретные условия и алгоритмы расчета. Когда они у нас есть, мы можем сформировать тестовые примеры для каждого варианта или диапазона условий. Это позволит разработчику лучше понять, что именно и как проверять.
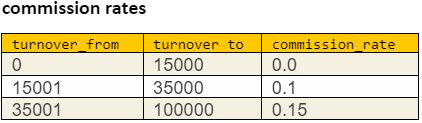
Допустим, нам нужно выбрать клиентов, их оборот за месяц и комиссию сотрудника отдела продаж (ОП) с каждого клиента. При этом для разных оборотов процент комиссии меняется, то есть клиенты сегментируются по оборотам. А сам оборот идет в зачет сотруднику ОП только за первые 90 дней активности клиента.
SELECT month, user_id, responsible, turnover,
turnover * commission_rate AS commission
FROM
(
SELECT month, user_id,
responsible, — ответственный за клиента сотрудник ОП
first_pay, — дата первого платежа клиента
SUM(turnover) AS turnover
FROM user_transactions
--WHERE DATE_DIFF(date_paid, first_pay, DAY) <= 90 — допустим, мы забыли указать это условие
GROUP BY 1, 2, 3
) AS t
LEFT JOIN
(
SELECT turnover_from, turnover_to, commission_rate
FROM commisson_rates -- таблица с комиссионными коэффициентами в привязке к оборотам
) AS c ON t.turnover >= c.turnover_from AND t.turnover < c.turnover_to
WHERE turnover > 0
Этот запрос может завысить сумму комиссионных, так как ограничение по «времени жизни» клиента оказывается не учтено. Но в конечном результате ошибка не обнаружится, ведь там нет этой метрики. Сформируем примеры по ТЗ.

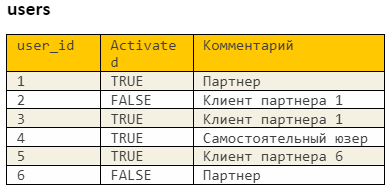
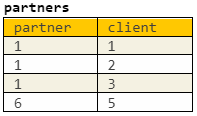
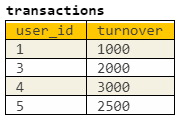
Нам требуется вычислить сумму оборотов активных партнеров и всех их клиентов. В users имеется флаг активации юзера, указывающий, что он хоть раз платил, то есть активировался. Первую версию запроса мы составили так:
SELECT partner,
SUM(turnover) AS partner_turnover
FROM
( -- Выберем всех активированных пользователей
SELECT user_id
FROM users — таблица со всеми юзерами
WHERE activated = TRUE — флаг активации юзера: такой юзер хоть раз платил
) AS u
JOIN
( -- Выберем из активных пользователей только партнеров и их клиентов
SELECT partner, client
FROM partner_client — таблица с клиентами партнеров
) AS p ON p.partner = u.user_id — каждый партнер, который клиент сам для себя
JOIN
( -- Выберем только платящих клиентов и их обороты
SELECT user_id, SUM(turnover) AS turnover
FROM transactions — таблица с оборотом
GROUP BY 1
) AS t ON t.user_id=ag.client — привязываемся к клиентам
GROUP BY 1
В примерах мы выделяем все комбинации пользователей в зависимости от их сегмента (партнер, клиент партнера, самостоятельный) и свойства активации (активирован, не активирован). Проведя каждый из примеров по запросу, мы видим, что не все желаемые строки попали в конечную выборку:

Ведь мы не учли, что партнер сам может быть неактивным, а его клиенты при этом могут иметь оборот. Такие тонкости очень сложно отследить, просто глядя на результат или на код. Нужно хорошо понимать бизнес-логику и уметь ее визуализировать до разработки.
В нашем примере правильнее было бы вовсе не привязываться к флагу активации, а просто взять все транзакции и выбрать из них юзеров — клиентов партнера:
SELECT partner,
SUM(turnover) AS partner_turnover
FROM
( — Выберем только платящих клиентов и их обороты
SELECT user_id, SUM(turnover) AS turnover
FROM transactions — таблица с оборотом
GROUP BY 1
) AS t
JOIN
( — Выберем из активных пользователей только партнеров и их клиентов
SELECT partner, client
FROM partner_client — таблица с клиентами партнеров
) AS p ON p.client = t.user_id
GROUP BY 1
Резюме
Итак, что мы делаем для проверки доработанной витрины:
- Проверяем ее на дубли подсчетом по уникальному составному ключу до группировки.
- Сравниваем старые поля новой версии с текущей с помощью EXCEPT DISTINCT.
- Новые поля проверяем так же, как при создании новой витрины.
Для проверки вновь создаваемой витрины:
- Проверяем ее на дубли.
- Находим лишние строки, фильтруя конечную витрину по «инвертированным» условиям ТЗ.
- Составляем на основе требований ТЗ примеры исходных данных и ожидаемых результатов для них — и убеждаемся, что запрос верно обрабатывает все варианты.