Мы использовали сначала GitHub, потом переехали на GitLab. В этой статье я расскажу, как мы настроили CI/CD (continuous integration / continuous delivery) кода для представлений BigQuery.
Итак, задача сводится к следующему: в момент мержа ветки в мастер должно происходить обновление кода всех созданных или измененных представлений в аналитическом хранилище.
На первый взгляд настройка CI/CD в Gitlab — это не очень простой процесс, но оно того стоит!
Токен GitLab
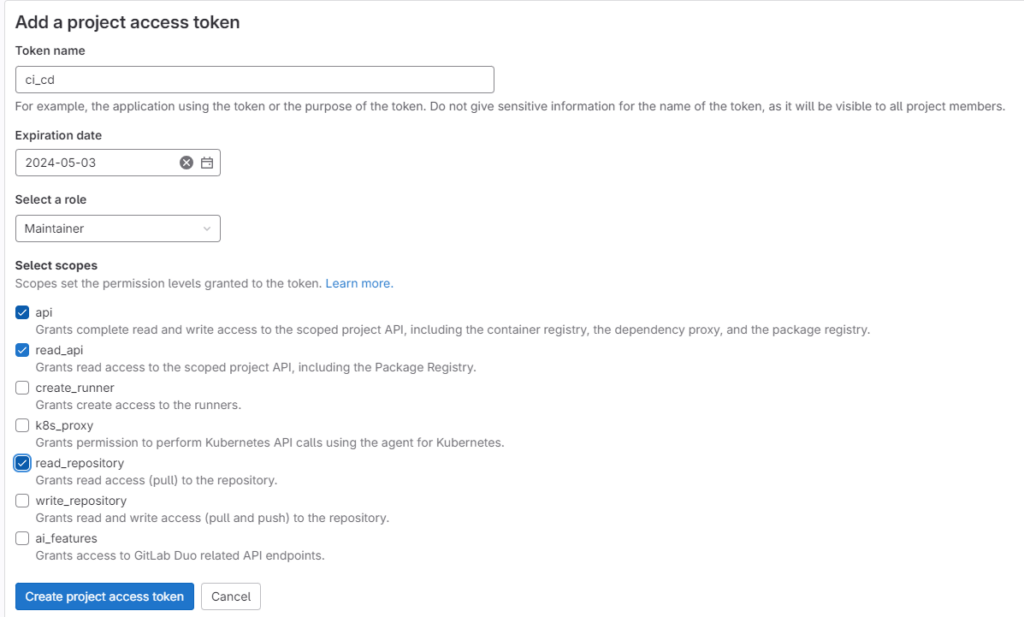
Прежде всего нужно сгенерировать токен для программного доступа к репозиторию. Заходим в Settings — Access Tokens и нажимаем Add new token. Придумываем имя токена, указываем роль, которой доступно чтение репозитория, выставляем скоупы — api, read_api, read_repository. Жмем Create project access token.
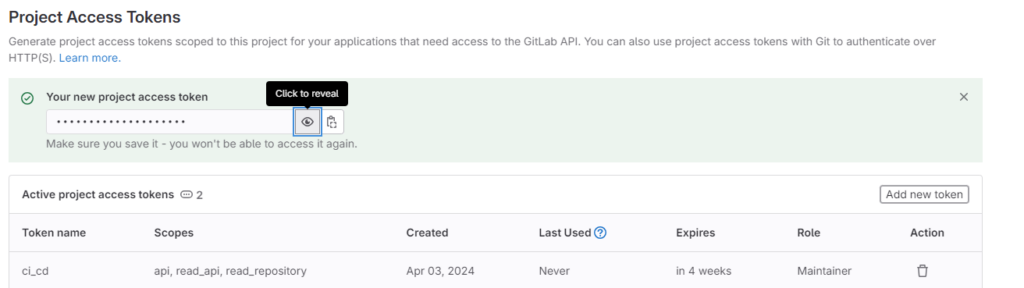
Готово, токен создан. Сохраните его у себя понадежнее.
Сервисный аккаунт Google
Для записи в BigQuery нам нужен сервисный аккаунт. Чтобы не прописывать его креды в коде скрипта, доступном всем, кто может читать репозиторий, сохраним реквизит private_key в переменной CI/CD. Заходим в Settings — CI/CD — Variables и жмем Add variables. Переключатель Mask variable позволяет сделать так, чтобы в логах задач CI/CD переменная выводилась только в зашифрованном виде.
YML-файл
Теперь нам потребуется YML-файл сценария для процесса CI/CD. Создадим в корне репозитория файл .gitlab-ci.yml и поясним GitLab, где его искать. Для этого переходим в Settings — CI/CD — General pipelines и вводим путь к файлу в поле CI/CD configuration file.
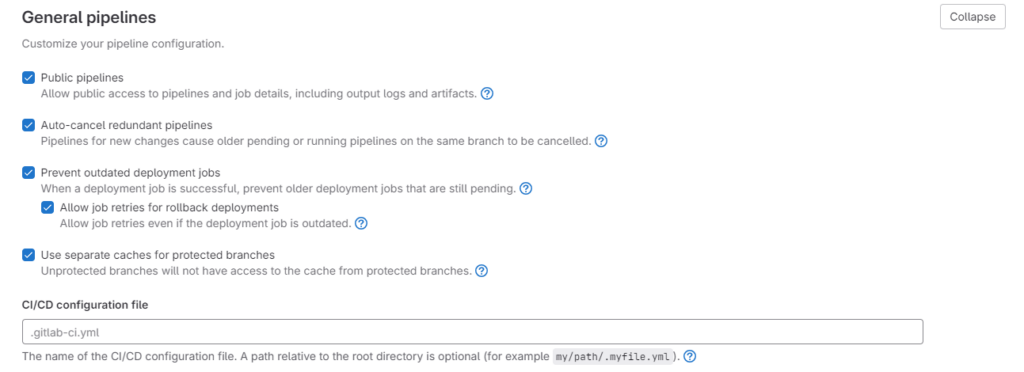
Мы создадим очень простой процесс, состоящий из одного этапа — записи представления в BigQuery. Но при необходимости вы можете создать сценарий какой угодно сложности! Например, там могут быть стадии валидации запроса или каких-либо других проверок.
Наш процесс будет запускаться в момент пуша версии репозитория в мастер-ветку. Код на языке YML выглядит следующим образом:
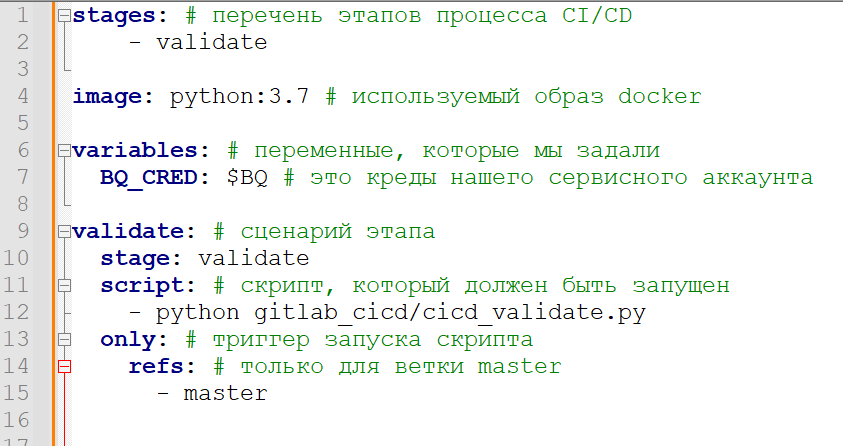
Файл можно взять здесь, а здесь размещено полное описание всех команд и возможностей YML для Gitlab.
Скрипт записи в BigQuery
Скрипт, осуществляющий интеграцию кода в прод, выполняет несколько простых проверок и записывает все измененные представления в BigQuery. Для этого должны выполняться следующие правила организации кода в репозитории:
- код представлений хранится в файлах с расширением SQL ;
- представления размещаются по пути:
projects/<Имя проекта в BQ>/<Имя датасета в BQ>/views/<Имя представления>.sql; - имя файла (без расширения) должно совпадать с именем представления;
- код представления должен начинаться со строки CREATE OR REPLACE VIEW.
Код скрипта с комментариями размещен здесь.
Ранер GitLab
Последний шаг — создание ранера, то есть приложения, которое и будет выполнять процесс CI/CD.
Для создания ранера переходим в Settings — CI/CD — Runners — и нажимаем New project runner.
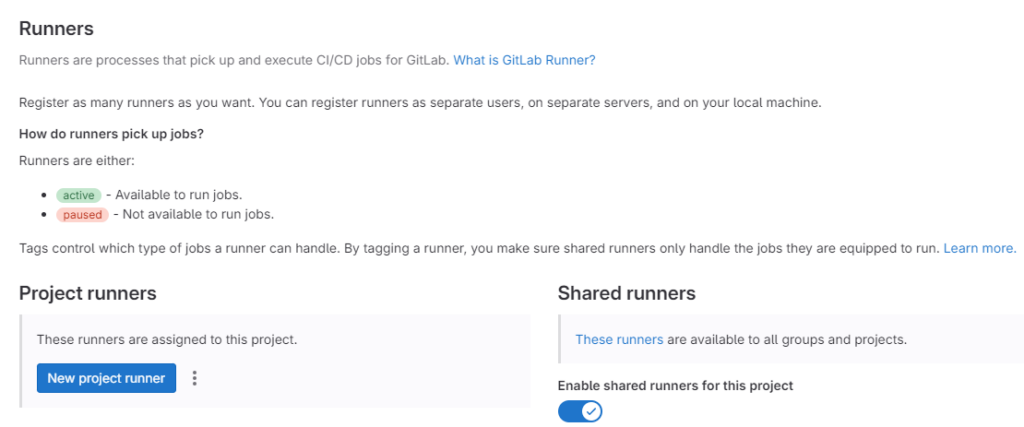
Ранер нужно скачать и установить на своей машине, затем зарегистрировать в GitLab. Описание сущности ранеров и процесса их настройки на русском языке можно посмотреть, например, здесь. Если коротко, то дело сводится к выполнению шагов:
- Настраиваем раннер: выбираем ОС или контейнер; для простоты ставим чекбокс Run untagged jobs, чтобы ранер обрабатывал все джобы; задаем имя ранера и описание.
- Инсталлируем раннер. Для ОС Windows инструкция выглядит примерно так:
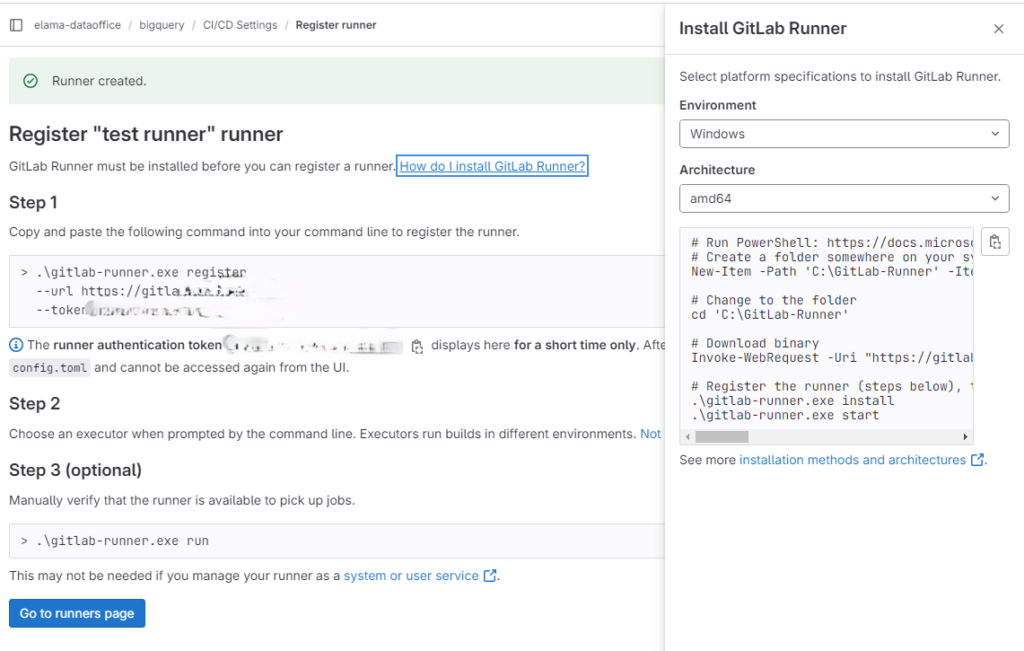
- Регистрируем раннер в Gitlab, требуемые действия показаны на скрине выше.
После того как ранер создан и зарегистрирован, убедитесь, что он запущен. На странице настроек CI/CD в секции Runners созданный нами ранер должен быть в статусе online.
Как должно быть в итоге
Если всё сделано правильно, то теперь в момент мержа ветки, то есть пуша в master, во вкладке Jobs в GitLab появится выполняемая задача (Job). Список выполненных задач выглядит так:
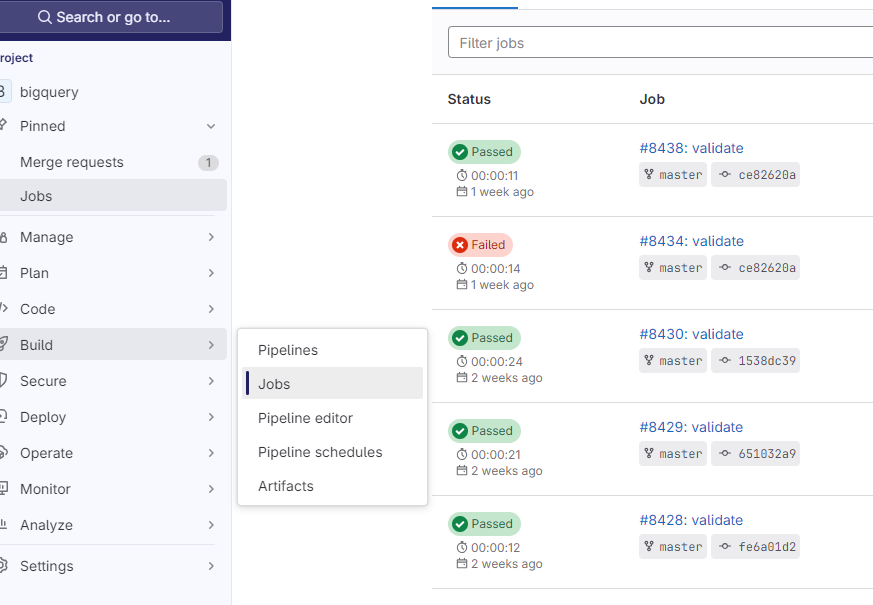
А лог конкретной задачи — примерно так:
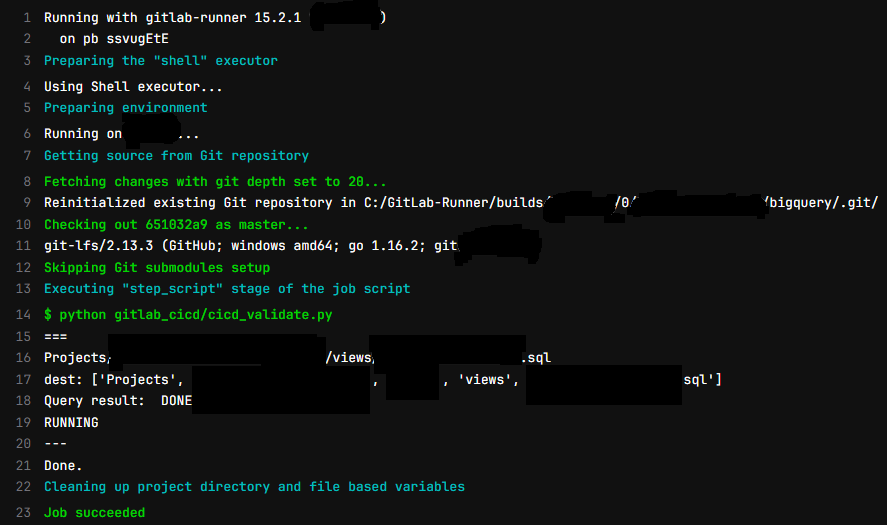
В этом примере успешно выполнен SQL-запрос создания представления в BQ, чего мы и добивались!