Что такое fine-tuning LLM?
Fine-tuning LLM представляет собой процесс адаптации уже обученной модели к конкретным задачам или области, например в медицине, юриспруденции, производстве. Суть этого метода заключается в том, чтобы дополнить модель информацией из нового или уникального набора данных.
Например, в специализированном медицинском учреждении хотят интегрировать большую языковую модель LlaMa 3.1 8B, чтобы помогать врачам с отчетами. В чистом виде, с большой вероятностью, LLM будет работать не до конца корректно из-за специфических медицинских терминов или профессионального сленга. Fine-tuning LlaMa 3.1 8B на основе данных медицинских отчетов и записей о пациентах повысит точность и улучшит понимание задачи: модель сможет определять медицинскую тематику, изучит нюансы профессионального контекста и структуру отчетов, что в конечном счете поможет врачам в генерации более точных и адаптированных документов.
Когда целесообразно применять fine-tuning?
Многие компании стремятся использовать fine-tuning на собственных данных, надеясь обогатить модель уникальной информацией для достижения бизнес-целей, но это не всегда дает ожидаемые результаты. Даже в OpenAI подчеркивают, что использование fine-tuning для обучения модели новым данным не является оптимальным решением: «Хотя fine-tuning может показаться более естественным вариантом — в конце концов GPT получил все свои знания именно через обучение на данных, — мы обычно не рекомендуем его как способ обучения знаниям. Fine-tuning лучше подходит для обучения специализированным задачам или стилям, а не для фактического запоминания».
Таким образом, применять fine-tuning имеет смысл в тех случаях, когда необходимо, чтобы модель имитировала определенный стиль ответов или решала узкий круг задач. Не всегда адаптация модели к новым данным приводит к улучшению ее работы. Иногда это может создать больше проблем, чем пользы. К примеру, после fine-tuning у модели может чаще проявляться эффект галлюцинаций, когда она начинает генерировать неправдоподобные или не соответствующие действительности ответы. Кроме того, fine-tuning может стать причиной неточной адаптации модели к изменениям в стиле или тоне перевода текста, что ограничивает их гибкость в различных контекстах.
Методики fine-tuning моделей LLM
Fine-tuning — это фактически мини-обучение собственной языковой модели. Он включает несколько основных этапов:
- работа с данными (подготовка, сбор, очищение, разметка в формате «вход — выход»);
- выбор языковой модели;
- настройка окружения (инфраструктуры, фреймворков);
- конфигурация параметров, таких как learning rate, batch size, epochs;
- обучение модели;
- валидация и оценка ее перформанса (Loss, Accuracy, F1-score).
Методики fine-tuning больших языковых моделей можно разделить на несколько ключевых категорий:
1. Полный fine-tuning.
В этом подходе обновляются все параметры модели, что позволяет ей адаптироваться к новой задаче. Это наиболее традиционный метод, но он требует значительных вычислительных ресурсов.
2. Тонкая настройка с «замораживанием» слоев.
Здесь «замораживаются» нижние слои модели, отвечающие за общие языковые представления, в то время как верхние слои, более специфичные для задачи, обучаются. Это позволяет сохранить общие знания модели и адаптировать ее к конкретной задаче.
3. Adapter fine-tuning.
Вместо обновления всей модели добавляются небольшие модули (адаптеры), которые обучаются на новых данных. Основные веса модели остаются неизменными, что значительно снижает вычислительные затраты.
4. LoRA (Low-Rank Adaptation).
В этом методе обновляются только низкоранговые матрицы, добавленные к существующим слоям модели. Это позволяет эффективно адаптировать модель, не затрагивая всех ее параметров.
5. Fine-tuning с использованием RLHF (обратная связь от человека).
Этот подход включает обучение модели с использованием обратной связи от человека, что может значительно повысить качество ее работы
Эти подходы можно классифицировать по сложности реализации, гибкости и необходимым вычислительным ресурсам.
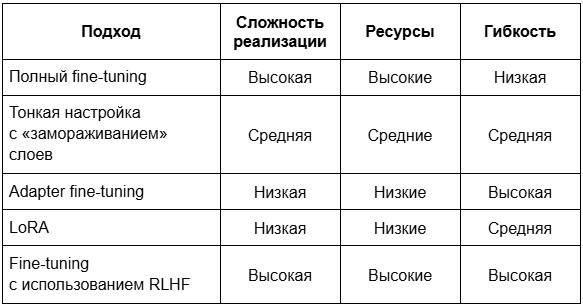
Для экономии ресурсов и многозадачности хорошо подходят Adapter Fine-Tuning и LoRA. В то время как для сложных систем, требующих высокой точности, применяются полный fine-tuning и RLHF.
Рекомендации по выполнению fine-tuning
Малым и средним компаниям не стоит использовать fine-tuning по следующим причинам:
1. Высокие вычислительные затраты.
Fine-tuning требует значительных ресурсов, особенно для моделей с миллиардами параметров. Это подразумевает использование мощных GPU и большого объема оперативной памяти. К примеру, для модели со 175 миллиардами параметров (например, GPT-3) в 16-битной точности потребуется около 350 ГБ VRAM (объем видеопамяти). Следует учитывать, что для работы с такими моделями обычно используются высокопроизводительные графические процессоры с большим объемом VRAM, такие как, например, NVIDIA A100 или H100, которые предлагают до 80 ГБ VRAM. Однако для моделей с сотнями миллиардов параметров этого может быть недостаточно, что требует применения методов распределенного обучения и оптимизации памяти. Помимо VRAM, процесс fine-tuning требует значительного объема оперативной памяти для хранения состояний оптимизатора, градиентов и активаций. К примеру, для модели с 7 миллиардами параметров (например, LlaMA-7B) может потребоваться до 56 ГБ RAM для эффективной настройки.
2. Большие и качественные объемы данных.
Для качественного fine-tuning необходим большой и тщательно размеченный набор данных, специфичный для решения конкретных задач. Речь идет о нескольких десятках тысяч пар «вопрос — ответ». Это позволит модели генерировать точные и информативные ответы. Часто компании пренебрегают качеством и объемом разметки, что приводит к проблемам с моделью.
3. Переобучение и утрата универсальности.
Fine-tuning может привести к переобучению на специфическом наборе данных, что снижает способность модели к генерализации и ухудшает ее производительность на других задачах. Она становится более специализированной, хуже решает задачи, для которых изначально была хорошо обучена.
4. Трудности обновления модели.
Если изменяются данные или требования к задаче, то модель может потребовать повторного fine-tuning, что снова связано с высокими затратами.
Эти аспекты следует учитывать при принятии решения о fine-tuning моделей LLM.
Влияние дообучения LLM на качество ответов: риски и рекомендации
В недавней статье «Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?», рассматривался важный вопрос:«Как введение новой фактической информации на этапе дообучения может повлиять на качество ответов больших языковых моделей (LLM)?»
Исследование показывает, что добавление новой информации может увеличить риск возникновения галлюцинаций — ситуаций, когда модель генерирует неверные или вымышленные факты. Это поднимает важный вопрос о том, как компании могут эффективно обогащать свои модели, не увеличивая при этом вероятности ошибок?
Если компания все же решает обогатить модель дополнительной информацией, критически важно уделить внимание качеству и полноте входных данных. Неполные или некачественные данные могут привести к еще большему количеству галлюцинаций, что негативно скажется на репутации и надежности модели.
Когда вашему бизнесу требуется fine-tuning модели?
В большинстве случаев (около 90%) бизнесу не требуется fine-tuning модели. Зачастую достаточно использовать методы, такие как Prompt Engineering и Retrieval-Augmented Generation (RAG), которые позволяют подключать внешние базы знаний без необходимости дообучения модели. Эти подходы позволяют эффективно адаптировать ответы модели к специфическим запросам, сохраняя при этом высокое качество.
Тем не менее есть ситуации, когда fine-tuning может быть оправдан. Например, если компании необходимо адаптировать модель под конкретный стиль общения или язык, то стоит рассмотреть возможность более глубокого изучения процесса fine-tuning. В таких случаях важно тщательно подбирать данные для обучения, чтобы минимизировать риски и повысить качество ответов.
Поэтому fine-tuning может быть полезным инструментом в определенных ситуациях. Однако большинство компаний могут обойтись и без него, используя более простые и безопасные методы адаптации моделей.