DevSecOps — автоматизация ИБ
DevOps — это парадигма, в которой живет вся разработка: максимум автоматизации при сборке, настройке и развертывании программного обеспечения. Традиционно проверки ИБ проходили в самом конце релизного цикла. И чаще они выполнялись вручную, что никак не вписывается в существующие процессы. По мере развития защищаемого ПО, процессов и роста кибератак стало очевидным, что ИБ становится узким горлышком, которое не способно переварить весь объем изменений, выдаваемых разработкой, за адекватное время. Необходимо серьезнее подходить к вопросам безопасности, автоматизировать рутину, выполнять проверки гораздо раньше. В связи с этим появилась и стала развиваться методология DevSecOps, которая помогает использовать ИБ-практики в парадигме DevOps — то есть на всех этапах жизненного цикла ПО.
Важной задачей DevSecOps является увеличение покрытия проверками безопасности разрабатываемых приложений и кодовой базы. При таком сценарии, когда код максимально покрыт, программные продукты надежно защищены от существующих киберугроз.

Зачем внедрять AI в цикл безопасной разработки?
Согласно исследованию Positive Technologies, процент целевых атак во втором квартале 2023 года вырос на 78%. Действия хакеров затрагивали предприятия малого и крупного бизнеса: злоумышленники получали конфиденциальную информацию и нарушали рабочие процессы в организациях. Чтобы противостоять этому, компании всё больше внимания уделяют качеству применяемых инструментов для обеспечения безопасности.
В процессе покрытия разворачивается множество инструментов, в контур безопасной разработки подключается всё больше систем и команд. Сканеры сообщают о тысячах срабатываний, которые нужно вовремя разобрать (провести ревью) и устранить. Человеческими ресурсами решить эту проблему достаточно сложно. Практика показывает, что у ИБ-инженеров или разработчиков, ставших Security Champions, хватает времени, чтобы разобрать лишь уязвимости высокой критичности. Но этого недостаточно, чтобы покрыть результаты, которые выдает система.
Если уязвимости устраняются с недостаточной скоростью, то начинает расти технический долг. Рассмотрим тренд за период с января по сентябрь 2023 года:
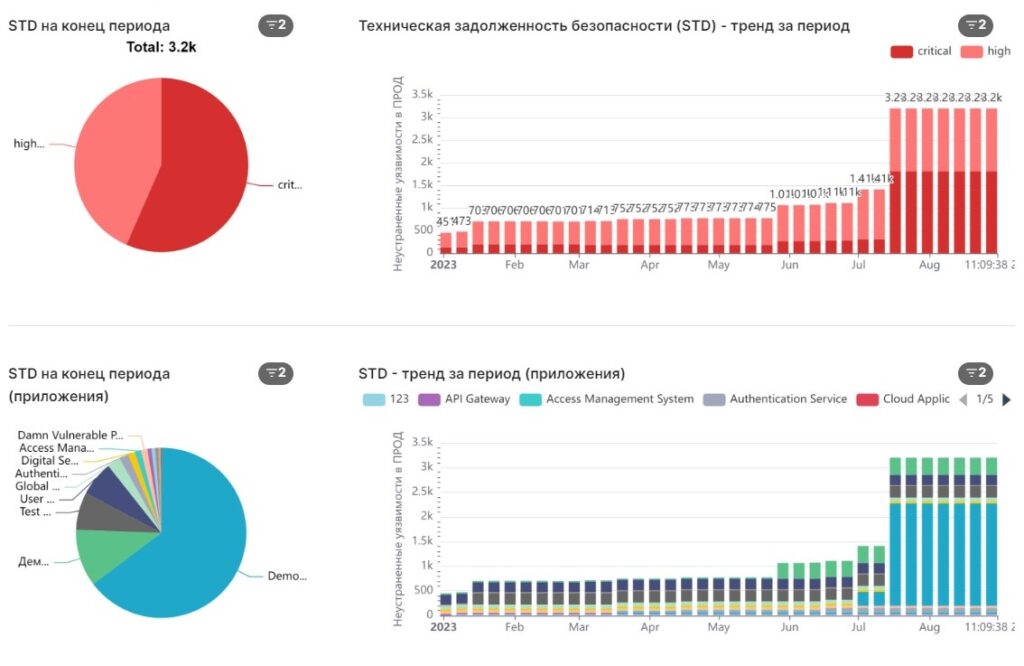
Security Technical Debt (STD) измеряет количество найденных и вовремя не устраненных уязвимостей, которые могут быть использованы мошенниками в промышленной среде. На диаграммах видим, что этот показатель по критическим уязвимостям (critical, high) увеличивается. Это влечет за собой рост целевых атак: хакеры будут рады использовать любую известную уязвимость, на которую у системы нет патча.
Обобщив полученный опыт, мы выделили точки неоптимальности процесса, которые можно автоматизировать или устранить, тем самым облегчив специалистам работу с рутинными задачами:
- Большое количество ложных срабатываний.
- Нет единой базы срабатываний.
- Долгая обратная связь от ИБ-инженеров: на разбор уходит несколько дней, в то время как пайплайны разработчиков занимают около пяти минут.
- Рабочих рук хватает только на критические уязвимости.
- Нет четких указаний по устранению уязвимостей.
Далее подробно расскажу, как мы анализировали данные и построили процесс по обработке результатов с помощью нашей платформы AppSec.Hub.
Анализ данных по уязвимостям
Для решения «болей» ИБ-инженеров мы провели анализ результатов SAST (Static Application Security Testing) и SCA (Software Composition Analysis).
Первый вывод был вполне ожидаемый: ложных срабатываний (FP) среди уязвимостей SAST было подавляющее число по сравнению с результатами SCA. Поэтому дальше мы сфокусировались больше на статике — и получили следующую картину:
- False Positive (FP) оказалось в среднем в 2 раза больше, чем True Positive (TP). И этот показатель зависит от языка. Например, для Java соотношение FP/TP выглядит как 5 к 1. А для Kotlin ситуация обратная: FP/TP = 1/10.
- Сгруппировав уязвимости категории / CWE (Common Weakness Enumeration), увидели, что:
Среди ложных срабатываний (FP) больше относится к:
CWE-226: Sensitive Information in Resource Not Removed Before Reuse
CWE-798: Use of Hard-coded Password
Среди подтвержденных (TP):
CWE-209: Generation of Error Message Containing Sensitive Information
CWE-499: Serializable Class Containing Sensitive Data
- Уязвимости одной категории / CWE при одинаковом статусе имеют схожие конструкции кода.
- Корреляция уязвимостей по статусу показала устойчивость к группировке по параметрам: CWE, категория, исходный код, критичность.
Мы собрали для себя закономерности при изучении структуры кода и начали строить вокруг этого модель машинного обучения.
Модель машинного обучения
Очень быстро мы поняли, что обычная классификация по параметрам не дает хоть какого-то значимого результата, поэтому стали работать над исходным кодом, на который среагировал сканер. Мы применили лингвистический анализ: разбили строки кода на лексемы, откинули имена переменных. Только после этого начали использовать классификаторы: поиск соседей KNN (K-Nearest Neighbor), дерево принятия решений DT (Decision Tree). И объединили их с помощью стекинга (Stacking, ансамблирование алгоритмов).
Конечно, без метрик и их сравнения тут никуда. Собранные данные по уязвимостям (размеченный датасет) измерили с помощью PSI (Population Stability Index) для того, чтобы понимать, как может меняться датасет по мере добавления новых данных. Это нужно, чтобы можно было корректно сравнивать результаты разных моделей.
Сами модели сравниваем по формуле: Recall = TP / TP + FN (False Negative). Если новое значение Recall больше предыдущего, то модель стала лучше.
Тестирование модели
Итак, модель готова, надо проверить ее в деле. Для этого собрали несколько open source проектов, которые использовались для демо наших продуктов. Провели сканирование и ручной разбор уязвимостей. А после этого уже сравнили результаты модели с выводами ИБ-инженеров.
В общей картине получили, что модель не идеальна, это да, но, посмотрев на результаты в нескольких разрезах, мы увидели, что для топ-25 самых опасных CWE (по версии 2023 года) результаты очень хорошие: 92% верных совпадений, 96% верно при accuracy > 0,85. Для некоторых CWE были только 100% попадания:
- CWE-89: Improper Neutralization of Special Elements used in an SQL Command (‘SQL Injection’)
- CWE-778: Insufficient Logging
- CWE-256: Plaintext Storage of a Password
Отсюда делаем промежуточный вывод, что результат модели совпадает с мнением AppSec-инженера по наиболее опасным уязвимостям. А это означает, что использование готовой модели позволит экономить ресурсы ИБ-инженеров и сокращает время обратной связи по уязвимостям.
Анализ исправленных уязвимостей
Помимо ревью мы решили разобраться, как разработчики исправляют проблемы безопасности и как можно сократить время их устранения. Стоит уточнить, что если уязвимостей много, то это не означает множество дефектов: зачастую достаточно исправить только одну строчку кода и «убить двух и более зайцев» сразу.
SAST (Static Application Security Testing):
- Множество однотипных срабатываний по одной и той же категории в одном и том же файле.
- Вектора потоков данных (путь AST дерева) однотипных уязвимостей часто пересекаются в одном файле и в одной строчке кода.
- Очень часто уязвимости исправляются по одной, и это больше похоже на устранение последствий, а не причины.
- Строчки кода могут прыгать вверх/вниз от скана к скану. Например, когда где-то добавилась функциональность, номер строки может меняться, а сама строчка кода, в котором была уязвимость, еще сохраняет константу.
SCA (Software Composition Analysis):
- Повышение версии чаще решает проблему. Правда, иногда после поднятия может «упасть» сборка. Поэтому наиболее эффективный подход — апнуть версию до приемлемой, тем самым устранив наиболее критичные уязвимости.
- Версия не всегда содержит все исправления. Когда разработчики изучают историю изменений компонента, они как раз ищут ту золотую середину, где можно поднять версию максимально безопасно, без изменений в интерфейсе и логике работы.
Корреляция уязвимостей
Так как в реальной жизни часто используется несколько инструментов в рамках одной практики, то мы у себя повторили эту ситуацию. И вот какие результаты группировки мы получили.

На выходе из сканеров было около 5,5 тысячи SAST-уязвимостей. За счет корреляции мы получили из них около 440 групп и еще примерно 585 уникальных уязвимостей, которые не объединяются по текущему алгоритму. В результате мы увидели, что топ-10 групп закрывают собой 60–70% уязвимостей.

Аналогичная картина повторилась и для SCA — тут уже был другой принцип группировки, но вывод остался прежним: топ-10 групп объединяют большую часть уязвимостей.
Отсюда делаем еще один вывод: не только с помощью авторевью, но и посредством корреляции возможно сократить и упростить работу как AppSec-инженера, так и разработчика, сделав так, чтобы вместо десятков тысяч дефектов к ним приходили десятки или единицы.
Обработка результатов в AppSec.Hub
Платформа AppSec.Hup запускает проверки, собирает и обрабатывает информацию об уязвимостях и формирует метрики для оценки эффективности. На основе выводов, что мы сделали выше, мы построили процесс по обработке результатов:
- Унифицировали формат. Существует много ИБ-сканеров, и каждый из них имеет свое представление деталей уязвимостей и их жизненного цикла. В рамках практики мы привели всё к единому виду.
- Авторевью (AVC) и группировка. Мы сделали так, чтобы все срабатывания загружались в базу AppSec.Hub и обрабатывались через модули авторевью и корреляции.
- Дефект-трекер. Группа уязвимостей — это дефект, который автоматически выгружается в дефект-трекер. Разработчик больше не работает с отчетами — только с дефектами.
Модуль AppSec.Hub освобождает ИБ-инженеров от рутинных процессов ручного разбора уязвимостей от старта скана до выдачи обратной связи — всё это делает система. А разработчик уже получает тикеты с уязвимостями, которые надо исправить. Соответственно, обратная связь от ИБ ускоряется, а значит, и фикс быстрее дойдет до конечного пользователя.
Эффективность решения в цифрах
Дабы подтвердить, что всё сделанное было не зря, мы посчитали эффективность каждого этапа и всего процесса для критических уязвимостей.

В общей сложности более 70% уязвимостей можно обработать в автоматическом режиме. Если посмотреть по практикам, то для критичных SAST эффективность составляет более 80%, а для SCA — чуть меньше 70%. Переведя проценты в трудозатраты, получаем около 8000 человеко-часов в год на команду из пяти ИБ-инженеров. А это уже сравнимо с наймом еще четырех инженеров.
Что дает обнаружение и устранение уязвимостей?
Прежде чем применять автоматизацию, нужно понять, есть ли в этом необходимость. И вот несколько графиков, которые отображают текущее состояние дел и ожидания от быстрого обнаружения и исправления уязвимостей:
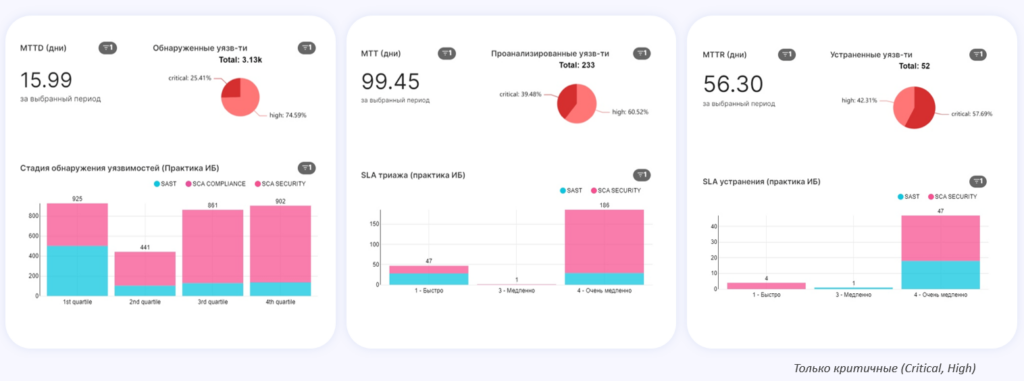
Основное, на что смотрит бизнес, это Time to Market (TTM) — время от начала разработки идеи до ее конечной реализации. TTM отвечает за то, как быстро изменения долетают до конечного пользователя. Конечно, надо понимать, что ТТМ выходит за рамки DevSecOps, поэтому мы выделили метрики, которые напрямую влияют на TTM:
- Скорость обнаружения уязвимостей
- Скорость обработки результатов (триажа)
- Скорость исправления/устранения уязвимостей
Более подробно эти метрики я разбирал ранее в статье «Shift Left: красивый отчет или реальность?».
Важно, что много значений метрик попадает в четвертую квартиль — детектирование не всегда проходит оперативно, а триаж и исправление выполняются долго. Это и создает предпосылки для роста технического долга. Здесь же и есть та часть процесса, к которой будет применяться автоматизация, чтобы помочь ИБ-инженерам и разработчикам быстрее делать разбор и исправление уязвимостей.
Заключение
Сегодня мы рассмотрели на примерах, какую роль в улучшении процессов играют автоматизация и машинное обучение. И увидели, как с помощью модуля AppSec.Hub можно решать сразу несколько задач:
- Экономить ресурсы ИБ-экспертов и разработчиков
- Сокращать время устранения уязвимостей
- Уменьшать стоимость выпуска безопасного приложения
- Достигать целевых показателей Time to Market
Высокий уровень киберугроз буквально ввел тренд на безопасную разработку. Чем быстрее команда находит и фиксит уязвимости, тем лучше для бизнеса. Ну а скорость развить без потери качества как раз может помочь автоматизация.