Цель и условия
Цель, поставленная заказчиком, — за два месяца слить данные из одного дата-центра, условно назовем его «кластер А», в «кластер В», хранившийся на другом ЦОД. Причем кластер А — это около 2 ТБ, а кластер В — 10 ТБ. В сумме это более 500 000 000 документов. Предстояло смешать данные с сохранением структуры и получить кластер С, который будет иметь в себе копию кластеров А и В.
Так как Mongo — это master-slave-репликация, то master должен быть один, а у заказчика были две независимые базы, у каждой из которых свой master и набор slave. Имея два кластера со своими master, я не мог, используя подключение slave, накачать данных, потому что должен быть один master и одна группа slave, которая имеет отношение только к одному master.
Кластер в каждом ЦОД работал в связке со своими программными сервисами, но структура кластеров была одинаковой, древовидной.
Условия для миграции данных были жесткие. Пропускная способность канала между дата-центрами не очень высокая — 300 Мбит/сек. Это всё, что нам мог дать провайдер. Даунтайм, на который заказчик мог остановить использование базы данных, — шесть часов.
Поиск решения
Моя предварительная оценка фул-бэкапа была безрадостной. Бэкап 2 ТБ будет делаться много часов, плюс потребуется время на сборку. И перекачка заняла бы пять дней. По финансовым причинам заказчик не мог согласиться на такое время для переноса данных. Вариант бэкапирования не подходил.
Еще я рассматривал вариант создания сплит-бэкапа, разделения на «горячие» и «холодные» данные — когда делаешь метку в данных или срез на конкретное число месяца, после метки база пополняется данными, а данные до метки бэкапятся.
Но тут я бы столкнулся с проблемами: данные до метки не являются консистентными по отношению к бэкапу, они могут обновляться после запуска бэкапа. И следовательно, в бэкапе данные не будут актуальными, консистентными. Изменяемые данные приходилось бы помечать, метки должны были отражать историю, когда они обновлялись. И дальше пришлось бы работать с ними отдельно в бэкапе, что тянуло за собой еще массу проблем. Поэтому от разделенного бэкапа я тоже отказался.
Остановился на варианте создания своего, «самопального» решения с перекладыванием данных.
Проанализировав потоки данных, условия их хранения и сохранности, я принял решение использовать продукты Apache: Kafka, Java-модуль и Kafka Connect. Так как Kafka написан на Java, пришлось подтягивать знания по языку, а еще по распределенным вычислительным системам, потому что Kafka использует ZooKeeper.
Реализация проекта
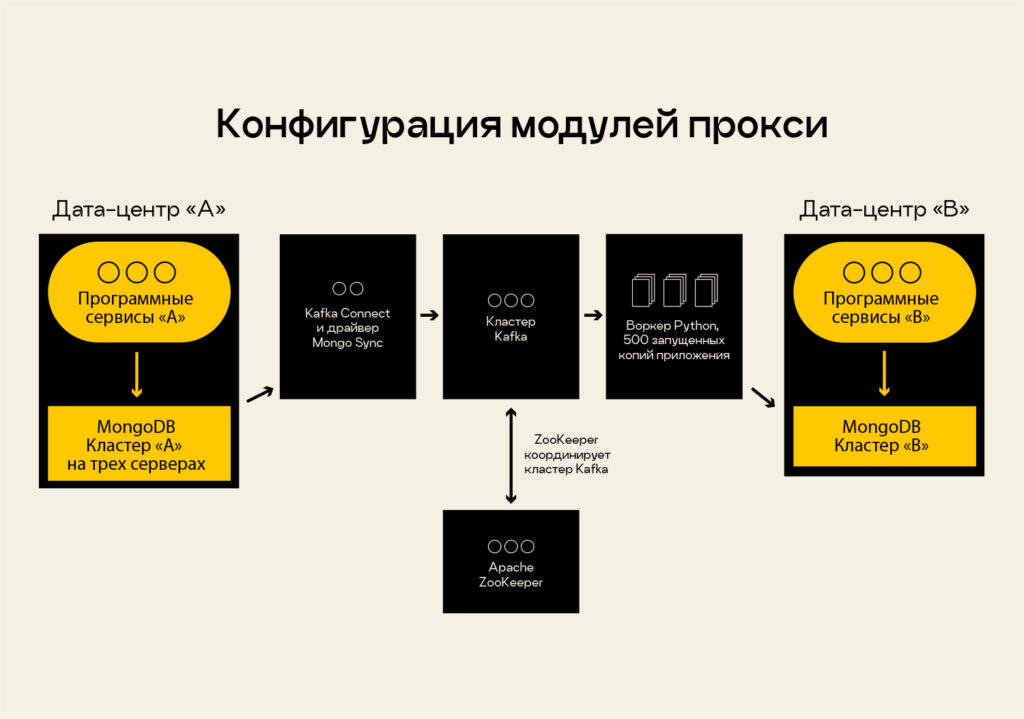
Проект предусматривал развертывание Kafka в трехузловой репликации, подключение ZooKeeper для трехузловой репликации и использование этой связки как трассы событий. Дальше надо было подцепить Kafka Connect, загрузить в него Mongo Source Driver и начать стримить данные с кластера А. Когда они туда прилетают, у меня есть триггер события, и я в режиме реального времени получаю триггер и весь snapshot данных. Он лежит в очереди в Kafka, откуда уже мы можем отправить его, куда нам нужно.
Используя Kafka Connect и драйвер Mongo, я подцепился к кластеру А и начал выкачивать данные и заливать их в топики Kafka. Топики соответствовали названиям баз и названиям коллекций документов, которые лежали в кластере А. Так я решил часть проблем, связанных с историческим набором событий, которые нужно было сохранять, и консистентностью данных, то есть я получил всю историю данных.
К тому же модуль Kafka Connect и драйвер Mongo оказывались идемпотентными. Это гарантировало, что файл не будет пересоздаваться, если данные в нем не меняются.
Итак, все данные сливались в топики Kafka, ZooKeeper координировал кластер Kafka. Так как понимания Java не хватало, я не стал писать модуль для MongoSync-коннектора, чтобы, используя только Kafka и Kafka Connect, слить данные. В тот момент я написал собственный воркер на Python. Ниже привожу часть кода воркера:
from handler import handler
app = faust.App(
SERVICE_NAME,
broker=KAFKA_URL,
broker _credentials=KAFKA_CREDENTIALS,
stream_buffer_maxsize = KAFKA_STREAM_BUFFER_MAXSIZE,
consumer_max_fetch_size = KAFKA_CONSUMER_MAX_FETCH_SIZE, //максимальный размер выборки
value_serializer=”raw’, // Данные сохраняются в сыром виде
topic_partitions=3,
logging_config=get_logger_dict_config(),
loghandlers=get_logger_handlers()
)
topic = app.topic(*LIST_TOPICS_WITH_PREFIX)
@app.agent(topic)
async def on_event(stream) -> None: // Обработчик вызывается для каждого нового потока
async for event in stream.events(): // Затем каждое сообщение в потоке обрабатывается в цикле
topic_name_src = event.message.topic // Получаем имя топика
partition_src = event.message.partition // Получаем партицию (раздел)
offset_src = event.message.offset // Определяем положение данных в потоке
logger.info(f”Recieved message from topic { topic_name_src }, partition { partition_src } offset { offset_src }”) // Выводим все полученные данные в лог
serialised_message = None
try: // Пробуем распарсить сообщение в переменную serialised_message
logger.info(f”{ event.message.value }”)
serialised_message = json.loads(event.message.value)
logger.info(f”Serialized message from topic { topic_name_src }”)
except:
logger.error(f”Serialised message error from topic { topic_name_src }”)
return None
topic_name = get_topic_name(topic_name_src)
change_metric(topic_name, “receive”) // Указываем новое состояние для сообщения
handler (topic_name, serialised_message) // Передаем полученные данные в хендлер
Этот воркер разгребал очередь сообщений внутри Kafka: читал данные с обратной стороны топиков и перекладывал данные в кластер В. При этом в кластере А были поля с немного отличающимися типами, поэтому внутри воркера я вызывал хендлер, чтобы кастовать типы данных. Его код привожу ниже:
import json
from database import get_connect
from mapper import mapper, marker // Подгружаем маппер, его код покажу дальше
from logger import get_logger
logger = get_logger(_name_)
db = get_connect(“target”)
def handler(topic, message):
db_name, collection_name = topic.split(“.”) // Выделяем из сообщения имя БД и имя коллекции
payload_str = message.get(“payload”, None)
payload = json.loads (payload_str)
operation type = payload.get(“operationType”, None) // Определяем тип операции с данными
if operation_type == “insert”:
full_document_src = payload.get(“fullDocument”, None) // Для операции вставки получаем полные данные и записываем в full_document_src
document = None
try:
document = mapper(full_document_src) // Передаем данные в маппер для обработки
logger.info(f”Mapped document with id { full_document src[‘_id’] } from operation insert”)
except:
logger.error(f”Mapped error document { full_document_src[‘_id’] } from operation insert”)
return None
document = marker(document, “operationType”, “inserted”) // Устанавливаем маркер для обработанного сообщения
db.insert (collection_name, document)
if operation_type == “replace”
full_document_src = payload.get(“fullDocument”, None) // Для операции замены получаем полные данные и сохраняем их в full_document_src
document = None
try:
document = mapper(full_document_src) // Передаем данные в маппер для обработки
logger.info(f”Mapped document with id { fult_document_src[‘_id’] } from operation insert”)
except:
logger.error(“Mapped error document { full_document_src[‘ id’] } from operation insert’)
return None
document_id = document [“_id”] // Выводим полные данные с конкретным идентификатором
document = marker (document, “operationType”, “replaced”) // Устанавливаем маркер для обработанного сообщения
Внутри хендлера я передавал данные в маппер для обработки, чтобы привести все данные к единому формату и сохранить их в новой базе. Код маппера:
map_types = {
"_id": {"$oid": lambda src: ObjectId(src), "$numberLong": lambda src: Int64(src)},
"BalanceInCoins": {"$numberLong": lambda src: Int64(src)}
"TransactionId": {"$numberLong": lambda src: Int64(src)},
"UserId": {"$numberLong": lambda src: Int64(src)},
"Value": {"$numberLong": lambda src: Int64(src)},
"Dt": {"$date": lambda src: datetime(*gmtime(src / 1000)[:6])},
"Start": {"$date": lambda src: datetime(*gmtime(sre / 1000)[:6])},
"End": {"$date": lambda src: datetime(*gmtime(src / 1000)[:6])},
"LastUpdate": {"$date": lambda src: datetime(*gmtime(src / 1000)[:6])},
"TimeGenerate": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"StartDt": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"SuccessDt": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"From": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"To": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"DtAdd": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"CustomRtpExpireDt": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"LastUpdateDt": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"GenerateDt": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
"LastVisitForJackpot": {"$date": lambda src: datetime(*gmtime(src / 1000) [:6])},
}
Еще раз расскажу, как работала эта схема: воркер передавал хендлеру каждое сообщение из Kafka, тот определял тип операции и вызывал маппер. Маппер приводил данные к единому виду. Затем обработанные данные возвращались наверх и отправлялись в кластер В.
Итоги
Я собрал кастомное решение с воркером, которое в режиме реального времени переливало 2 ТБ данных: выкачивало их из кластера А, из топиков в Kafka их вытаскивал воркер и перекачивал в кластер В.
У меня были метрики, которые давали информацию о том, что происходило с кластерами MongoDB и Kafka, сколько данных Kafka получала в единицу времени, как справлялся самописный воркер. Также я собирал логи и смотрел, какие ошибки валились, как работали серверы и интернет-соединение.
Все данные я перелил успешно, данные «устоялись», они были идентичны друг другу, скорость изменения событий составляла доли секунды. Это значит, что когда программные сервисы вносили изменения в кластер А, то это событие моментально улетало в Kafka, оттуда — в питоновский воркер, из воркера — в кластер В. Я передиплоил пользовательские сервисы, переключив их с кластера А на С, который получился в результате слияния двух «родительских» кластеров. Кластер А отключил.
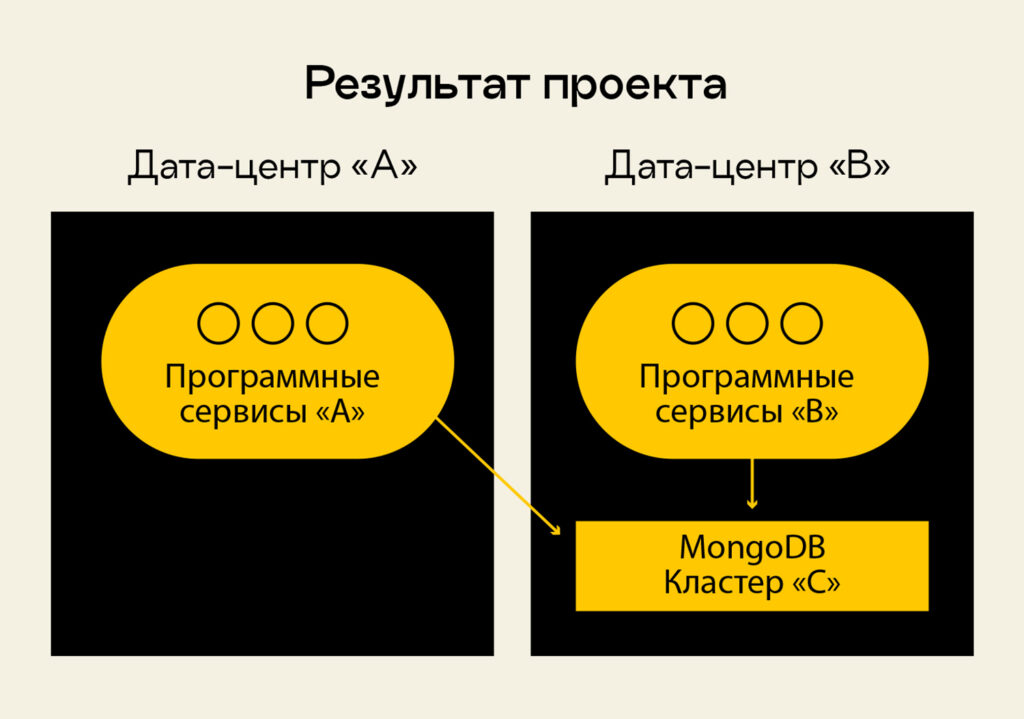
Итогом проекта, кроме успешного слияния двух больших кластеров данных MongoDB, стало создание почти коробочного решения для подобных задач. Оно позволяет инсталлировать Kafka ZooKeeper, настраивать Kafka Connect и воркер на Python таким образом, чтобы его можно было подключить к любому набору топиков, делать масштабируемые инсталляции и качать с Kafka большие объемы данных и переносить их из одного кластера в другой. Заказчик получил решение с downtime, равным одной минуте.
Если у кого-то из разработчиков возникнет проблема с переносом данных MongoDB, буду рад рассказать об этом решении в проекции на новую задачу.