Применяем библиотеку Ollama
Идея состоит в том, чтобы поручить LLM отнести сайт к одной тематике и подтематике в представленном справочнике тематик. То есть выполняем следующее:
- Составляем справочник тематик и подтематик.
- Парсим текстовый контент интересующего списка сайтов.
- Контент и справочник в составе промпта отправляем в LLM и запрашиваем отнести этот сайт к наиболее подходящей тематике и подтематике.
Решение первых двух подзадач я рассмотрел в прошлой статье, а здесь сосредоточимся на третьем шаге.
Мы выбрали Ollama — это открытый фреймворк для запуска больших языковых моделей на локальном компьютере или виртуальной машине. То есть можно развернуть ИИ, работающий полностью офлайн, без отправки данных на внешние серверы и без абонентской платы. Короче говоря, это бесплатно, приватно и весьма просто в использовании.
Установка Ollama
При работе в Windows Ollama устанавливается и запускается как отдельная служба. Выполните следующие шаги:
- Перейдите на https://ollama.com/download/windows и скачайте OllamaSetup.exe.
- Запустите установщик и следуйте инструкциям.
- После установки Ollama автоматически запустится как служба Windows.
Для проверки установки запустите в командной строке:
ollama --version
Если команда не найдена, добавьте Ollama в PATH. Обычно Ollama устанавливается в C:UsersВашеИмяAppDataLocalProgramsOllama. Добавьте этот путь в переменную окружения PATH.
Но это только служба, «оболочка», сервер. Теперь нам потребуется сама модель. Загрузить ее можно из командной строки командой ollama pull <модель>. Например:
# Для легковесной модели (рекомендую для начала)
ollama pull gemma2:2b
# Или для более мощной модели
ollama pull llama3.2:3b
# Для русского языка
ollama pull llama3.1:8b
Список же всех доступных моделей можно увидеть на сайте Ollama.
Если сервер Ollama не запустился сам, примените команду
ollama serve
Сервер будет доступен по адресу http://localhost:11434.
Ollama имеет простенький графический интерфейс, позволяющий в режиме чата запускать промпты, выбрав модель. При этом, если модель еще не скачана на компьютер, она начнет скачиваться после отправки первого промпта к ней.
После скачивания выбранная LLM будет отвечать так же, как уже привычная онлайн-версия ИИ-ассистента.
Для обращения к Ollama из Python-скрипта установим также соответствующую библиотеку:
pip install ollama
Вот теперь можно переходить к программированию.
Код определения тематики сайта
Код базового скрипта выбора тематики сайта с помощью LLM можно посмотреть здесь. Он содержит следующие блоки:
- Подключение к ClickHouse, на базе которого у нас построено аналитическое хранилище, и получение справочника тематик и подтематик.
- Функция
fetch_content()собирает контент с сайта и разбивает его на структурные сегменты. - Класс
KeywordCategorizer, который: а) инициализирует LLM через Ollama; б) отправляет в нее промпт; в) получает ответ и извлекает из него тематику и подтематику. - Формирование промпта, включающего в себя структурированный контент сайта, справочник тематик, четкую задачу для LLM, требование придерживаться строгого формата вывода, дополнительную угрозу — для повышения качества результата.
- Вывод результатов.
Модель справляется весьма успешно, если справочник тематик достаточно полон. По сравнению с определением тематики по ключевым словам достоинства способа:
- Не требуется список ключевых слов и их весов.
- Короче и проще код.
- Возможность гибко и быстро наращивать задачу, например попросить нейросеть придумывать новую тематику, если не подошла ни одна имеющаяся, или дополнить промпт требованием указать уверенность.
Недостатки так же очевидны, как и достоинства:
- Скорость определения значительно ниже: если по ключевым словам тематика определялась за 2–3 секунды на сайт, то LLM работает 30–60 секунд. Если скорость критична, можно попробовать применить другие модели, параллельную обработку сайтов, но мне не удалось уменьшить длительность исполнения до значений, сопоставимых с первым способом.
- Этот подход представляет собой черный ящик: мы не можем прозрачно управлять качеством ответа (например, подкрутив список или веса ключей).
- Модели занимают прилично места на диске (гигабайты).
Выбор способа определения тематики зависит от контекста ситуации. Надеюсь, обе статьи помогут вам выработать оптимальное решение.
Проверка работы скрипта
Чтобы затестить работоспособность нашего алгоритма, предложим ему определить тематику нескольких случайных сайтов, которые я достал из поисковой выдачи:
[‘https://avtoservispiter.ru/’, ‘https://mc21.ru/’, ‘https://spb.restoran.ru/’, ‘https://toptop.ru’].
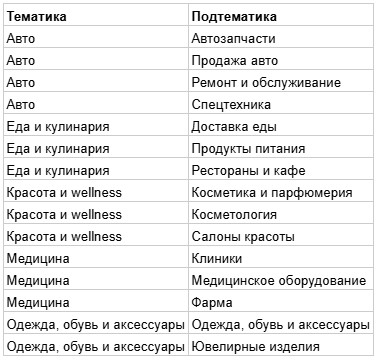
Положим, наш справочник тематик, помимо прочего, включает следующие позиции:
Запуск скрипта с такими входными данными выдает результат:

Мы видим, что тематику и подтематику трех первых сайтов модель определила точно. С четвертым — неоднозначно. Скорее подтематику следовало определить как «Одежда, обувь и аксессуары», так как это основная категория товаров на данном сайте. Но украшения в ассортименте также присутствуют. Для отслеживания таких (весьма нередких) случаев, когда сайт можно отнести к нескольким категориям, имеет смысл запросить у нейросети оценку уверенности определения. Результаты с низкой уверенностью стоит отправлять на дополнительную валидацию человеку-асессору (или даже другой нейромодели).
Резюме
В продолжение темы определения тематики сайтов мы рассмотрели применение к этой задаче Ollama — фреймворка управления LLM-моделями. Способ работает дольше, но не требует списка ключевиков.
Разумеется, Ollama можно применять программно и в других ситуациях. Возможно, этот кейс вдохновит вас на использование ИИ для решения сложных или трудоемких задач, связанных с анализом больших текстов.