
Что будет, если не отслеживать метрики и не хранить логи
На первый взгляд может показаться, что сбор метрик и логирование не слишком нужны. Если разработчик делает pet-проект, ему интереснее реализовать идею, а не анализировать метрики. Если приложение работает откровенно плохо, автор узнает об этом во время тестирования, на ревью в магазине приложений или — в худшем случае — из комментариев и отзывов пользователей.
Но по таким источникам не удастся определить причины ошибок: они слишком ненадежные и малоинформативные. Чтобы узнать, насколько стабильно работает приложение, нужно следить за его производительностью, отслеживать сбои и на всякий случай хранить логи. Сбор технических данных добавляется в проект достаточно просто и быстро, поэтому не стоит ими пренебрегать.
С продуктовыми метриками и аналитикой дело обстоит иначе. Собирать и анализировать данные сложнее, но без этого не удастся понять, зашло приложение пользователям или нет. Не получится оценить конверсию, определить портрет пользователя, узнать, какие функции используют чаще всего. То есть будет совершенно неясно, в нужном ли направлении развивается проект.
В конечном итоге улучшать и продвигать приложение, в котором никто не отслеживает метрики и логи, значительно сложнее.
Какие метрики нужно отслеживать
Продуктовые метрики могут сильно различаться в разных проектах. Их набор определяет project-менеджер или аналитик, он решает, какие события и данные важны для анализа работы приложения.
Для большинства продуктов имеют значение несколько базовых метрик, которые можно собирать с устройства пользователя:
- модель;
- версия операционной системы;
- язык интерфейса;
- часовой пояс;
- геолокация (в ограниченных пользователем пределах);
- время сессии от запуска приложения до выхода из него.
Аналитик также может попросить разработчиков собирать кастомные события, например нажатия на кнопки. Допустим, в метрики можно отправлять данные о том, какие опции выбраны в меню приложения.
На проектах, где я работал, чаще всего для сбора подобной аналитики из мобильных приложений использовали SDK Amplitude, Google Analytics for Firebase, Яндекс Метрику. Об этих решениях от крупных компаний знает большинство разработчиков, но есть и другие, менее популярные.
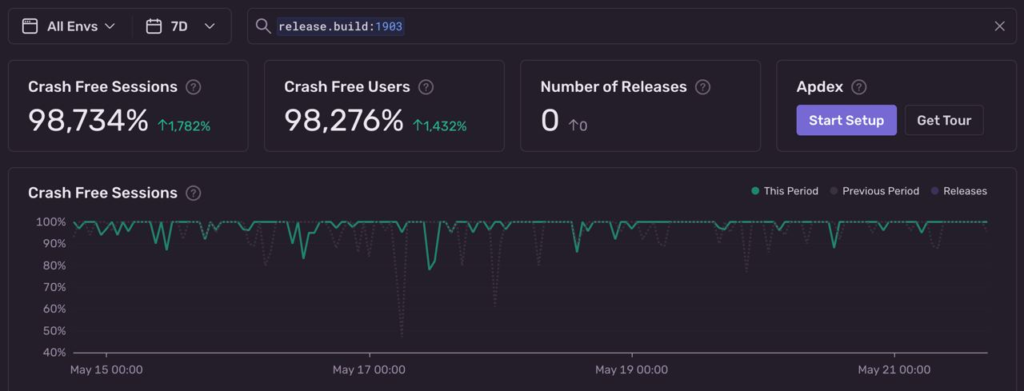
Для разработчиков важны другие метрики, связанные со стабильностью приложения. Это количество сессий без сбоев (crash-free session) и количество пользователей без сбоев (crash-free users).
Crash-free session — число запусков приложения без падений. Например, пользователь запустил приложение 100 раз, из них 1 раз приложение не загрузилось. Тогда crash-free session для этого человека будет 99%.
Crash-free users — число людей, которые не столкнулись с падением приложения. Если у приложения только один пользователь и ни одного падения, то crash-free users будет равен 100%.
Значение этих показателей должно быть максимально высоким. При разработке стоит ориентироваться на результат 99%. Такой показатель — достижимая цель для приложений, которые не обрабатывают данные на устройстве. То есть нужно только сверстать интерфейс без багов и наладить сетевое взаимодействие.
Подобных клиент-серверных приложений большинство: данные обрабатываются на бэкенде, а устройство загружает результат работы и показывает его пользователю. В таком приложении могут случаться ошибки сетевого подключения или отрисовки интерфейса, но любые метрики crash-free должны быть достаточно высокими.
С другой стороны, есть приложения, которые выполняют какую-либо работу на самом устройстве. Это могут быть инструменты для работы с картами и навигацией, ресурсоемкие фото- и видеоредакторы, а также приложения, которые работают в фоновом режиме. Для них поддерживать высокий crash-free сложнее.
Например, видео можно записывать в десятках разных форматов, для каждого из них нужен свой кодек. Причем на разных устройствах может быть разный набор поддерживаемых форматов и кодеков, а их качество и документированность иногда невысокие. Вполне возможна ситуация, когда пользователь устанавливает редактор видео на noname-устройство с кодеками сомнительного качества. В этом случае разработчик не гарантирует корректную работу приложения, и метрики crash-free могут упасть.
Отслеживать стабильность мобильного приложения можно через Firebase Crashlytics, Sentry или UXCam.
Какие события и метрики попадают в логи
Теоретически в логи можно складывать всё что угодно. Например, записывать комментарий об успешном выполнении каждой строки кода. Но на практике так, конечно, никто не делает.
Чаще всего в логи собираются те данные, которые в случае падения помогут восстановить картину произошедшего. Простейший вариант логов предлагает практически любой сервис сбора статистики и аналитики. Если приложение упадет или зависнет, сервис сформирует отчет stack trace — последовательность вызванных методов в коде, которая привела к сбою.
Что конкретно произошло — ошибка при работе с сетью или файловой системой, нажатие на кнопку — неважно. В любом случае ошибка находится в конкретном методе, а в stack trace хранится информация о том, в каком порядке исполнялся код приложения.
Во многих ситуациях уже этой последовательности достаточно, чтобы разобраться в причинах сбоя. Но иногда stack trace не хватает: к примеру, в приложениях, работающих в многопоточном режиме, в списке будут данные всех потоков. Хотя в логах указано, в каком методе произошла ошибка, может быть неочевидно, какие данные и как именно туда попали.
Чтобы разобраться в причинах ошибки или падения приложения, нужны понятные логи. Записывать нужно запуски и остановки приложения, сетевые запросы, авторизации, запросы к базе данных и другие важные события.
Кто отвечает за анализ метрик и логов
Кто анализирует все собранные данные о приложении, зависит от взаимодействия и ролей в команде.
Продуктовые метрики и аналитика, например нажатия на кнопки, чаще всего интересуют project-менеджеров или продуктовых аналитиков. В крупных компаниях это чаще всего отдельная роль или даже отдельная команда. Project-менеджер придумывает, какие метрики нужно собирать в приложении, а после аналитик проверяет и анализирует их, делает выводы. Затем они вместе вырабатывают решение, которое улучшит показатели.
Сервисы сбора аналитики позволяют ограничить доступ к метрикам, и в большой компании посмотреть их сможет только аналитик.
В небольшом стартапе зачастую нет отдельной роли аналитика, поэтому данные доступны с большой вероятностью всей команде.
Статистику падений и зависаний приложения обычно могут посмотреть все: разработчики, аналитики, продуктовые менеджеры, тестировщики. Если метрики стабильности падают, то в приложении что-то явно не в порядке, и вся команда заинтересована в том, чтобы узнать об этом как можно раньше.
Нестабильное обновление можно отловить на разных этапах, большую часть проблем удается выявить во время тестирования. Но иногда ошибки проявляются, когда приложение уже раскатили на пользователей. В это время нужно внимательно отслеживать метрики и логи в продакшене.
Особенно это важно в первые часы и дни после релиза, когда обновление доступно небольшой части пользователей. В это время можно успеть выловить ошибки или, наоборот, убедиться, что новая версия приложения работает не хуже предыдущей. В этот период за метриками следят часто всей командой.
Заключение
Анализ метрик и логов помогает ясно видеть, как развивается приложение. Без этих данных разработка похожа на поездку в дождь на автомобиле с неисправными дворниками: вы ничего не видите и не понимаете, что происходит. Это значит, что все попытки управлять ситуацией равносильны гаданию. Если повезет, доедете благополучно. Возможно, придется остановиться, не добравшись до цели. А в худшем случае можете попасть в аварию.
Технические и продуктовые метрики важны для любого, даже маленького проекта, поэтому я советую начинать собирать и анализировать их на самых ранних этапах разработки.






