Как так вышло
Absolut POS — система автоматизации для ресторанов, кафе и баров, которая старается быть максимально простой в использовании и внедрении. Однако слово «простой» в этом предложении не должно обманывать — такая система автоматизации по определению не может быть простой «под капотом». Заведения общественного питания предполагают много событий, которые нужно вовремя получать, аккуратно хранить и обрабатывать. Компоненты, которые этим занимаются, будут общаться асинхронно, нередко находясь на разных физических устройствах. Есть тысяча причин, почему все может пойти не так, а в B2B-сегменте цена этого «не так» высока.
Разумное решение — воспользоваться готовым событийно-ориентированным фреймворком. Мы остановились на AxonIQ. У него были следующие преимущества::
- Event Sourcing — идеально для нашего кейса.
- CQRS и DDD — хорошие архитектурные паттерны в целом.
- Готовое комплексное решение — идеально для стартапа.
Event Sourcing очень хорош там, где необходимо обеспечивать аудит и фиксацию всех действий, где происходит движение денег, товаров, услуг и бонусов. Примеры таких сфер — ритейл, банки или в нашем случае фудтех. Напомню, что Event Sourcing — это когда в базе данных хранится не только текущее состоянии системы, но и все события, которые его меняли. Имея историю этих событий, можно без проблем делать undo/redo. Весомый бонус на этапе разработки: если допущена ошибка в бизнес-логике приложения, данные не испортятся непоправимо, потому что можно просто взять историю событий и посчитать состояние заново по правильной логике.
CQRS часто используют совместно с Event Sourcing, поскольку эти подходы хорошо дополняют друг друга. Логика чтения и изменения при Event Sourcing настолько различна, что имеет смысл четко разделить эти два типа операций. DDD — удачный архитектурный принцип для большинства систем, чтобы абстракции были интуитивно понятными и близкими к предметной области.
Вообще AxonIQ поощряет микросервисную архитектуру, однако мы пошли путем «модульного монолита» — когда в одном репозитории лежит несколько сущностей с минимальными, но ненулевыми зависимостями между ними. Так было проще с точки зрения деплоя и менеджмента кодовой базы.
Как всё работало
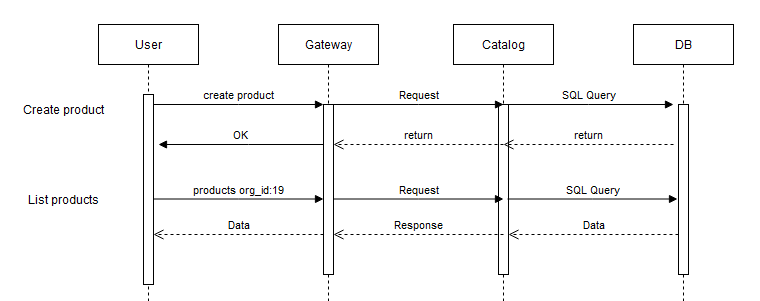
У нашей системы был единый вход и единый центр. Центр — это сервер AxonIQ, а вход — API Gateway.
API Gateway принимал все входящие запросы, неважно, проходили ли они через веб-интерфейс или POS-терминал. Запросы приходили в формате GraphQL, а API Gateway преобразовывал их в запросы и команды к конкретным сервисам. Эти запросы и команды шли в AxonIQ, который, в свою очередь, обрабатывал их и генерировал соответствующие события. Сервисы, подписанные на эти события, что-то с ними делали, генерировали свои запросы и команды для AxonIQ, который их обрабатывал и… В общем, вы поняли — обыкновенное асинхронное общение между сервисами через AxonIQ в качестве шины событий.
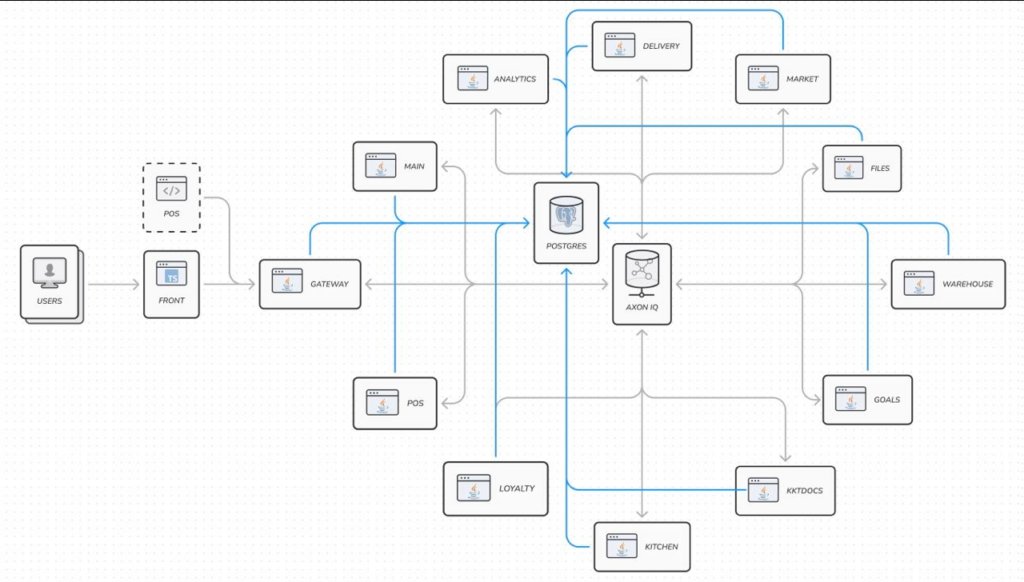
Разумеется, AxonIQ в этой схеме не просто присутствовал в качестве Man-in-the-Middle, а предоставлял персистентное хранилище событий, продуманные классы событий с возможностью наследования и полиморфизма и тому подобное. И мы этому радовались — до определенного момента.
Как всё пошло не так
Постепенно мы начали понимать, что при всех своих удобствах эта архитектура стреляет нам в ногу, и чем дальше, тем болезненнее.
Во-первых, AxonIQ — коммерческий фреймворк. Мы не смогли предугадать, насколько быстро упремся в необходимость масштабирования. И в момент, когда это произошло, выяснилось, что запрашиваемая цена для нашего стартапа достаточно болезненна и губительно влияет на текущий бюджет.
Во-вторых, AxonIQ — готовое комплексное решение. И это хорошо, когда всё идет по плану, но уже не так хорошо, если захотеть от него нестандартного. Например, мы с трудом мигрировали на другой хостинг. Дело в том, что в проекте две базы данных: PostgreSQL, где хранится текущий стейт, и MongoDB (на диаграмме отсутствует, она спрятана внутри сервера AxonIQ) — там происходит Event Sourcing. У нас возникли трудности с тем, чтобы при миграции состояния этих двух БД остались синхронизированными: AxonIQ сам решал, в какой момент писать в свою внутреннюю базу, а когда отправить событие сервисам, потенциально вызывая запись в Postgres. Пришлось обрубить все связи с внешним миром, дождаться, пока AxonIQ полностью отработает, и уже затем переносить систему на другой хостинг. Имей мы больше контроля над происходящим, обошлись бы меньшим даунтаймом.
В-третьих, достоинства AxonIQ имеют обратную сторону, а именно многословие.
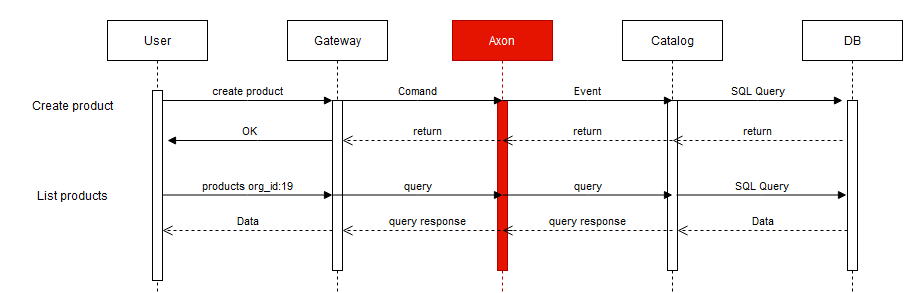
Даже самые простые взаимодействия, проходя через AxonIQ, обрастают большим количеством кода. Нужны классы для команд, запросов, событий, причем пишутся они не один раз — необходимо поддерживать их в актуальном состоянии. По моим прикидкам, использование AxonIQ увеличивает количество кода и время его написания примерно вдвое. Наверное, это приемлемый показатель для энтерпрайза, но для стартапа это крайне критично.
В-четвертых, AxonIQ подходит для проектов, написанных целиком на Java. Мы же в какой-то момент захотели сервисы на других языках. Зачем — об этом поговорим ниже.
Ну и наконец, мы стали страдать от своего «модульного монолита». Чем больше становился проект, тем неприятнее было время деплоя и время тестирования релиза. Опять же, в какой-то степени мы это предвидели: «модульность» — мера для уменьшения технического долга в случае перехода на микросервисы в будущем. Но мы недооценили скорость, с которой уперлись в ограничения своего подхода. Кроме того, хотя AxonIQ и позиционирует себя как дружественный к микросервисам, по факту он провоцировал нас писать более связанный код, где AxonIQ-специфичные классы становились общей зависимостью для разных модулей.
Как с этим бороться
Взвесив за и против, мы решили избавляться от AxonIQ и переходить на микросервисы. Но не сразу, а поэтапно.
На первом этапе мы решили поддерживать гибридную архитектуру. Создавая новые сервисы, подключать их напрямую к API Gateway, минуя AxonIQ. И, разумеется, делать их не модулями «монолита», а настоящими микросервисами. Таким образом мы обкатаем новую архитектуру, не поломав существующий функционал. Соответственно, на втором этапе старые сервисы будут постепенно отделяться от «монолита», становиться микро- и «отлучаться от груди» AxonIQ. В конце концов все модули «повзрослеют», и нянька в лице AxonIQ станет не нужна.
Я не упомянул об этом в предыдущем разделе, но одна из важных причин перехода на новую архитектуру — кадровая. Раньше нам нужно было искать хорошего Java-программиста, желательно имеющего опыт с AxonIQ, а потом еще достаточно долго онбордить его. «Модульный монолит», пусть и слабо, но связанный, требует, чтобы нового сотрудника знакомили не только с тем модулем, с которым ему предстоит работать, но и с другими, с которыми этот модуль связан. То есть в пределе — со всем продуктом целиком. Это существенно задерживало момент, когда новый специалист начинал работать в полную силу. Многословие AxonIQ быстрому знакомству также не способствовало.
В случае микросервисной архитектуры можно нанять хорошего «питонщика» без требования знать какую-то экзотику, затем выдать ему ТЗ — и ждать, пока он сделает готовый микросервис. Согласитесь, эта схема намного проще и дешевле. Разумеется, Python может заменить Java не везде, однако не все сервисы должны быть большими и высоконагруженными.
Чтобы сервисы могли общаться между собой без посредника, мы выбрали gRPC. Для сложной нагруженной системы это более удачный выбор, чем традиционный REST API, — возможность удаленного вызова процедур и компактная структура сообщений прекрасно подходят для бывшего «модульного монолита». Хорошее ли это архитектурное решение? Сейчас кажется, что да. Но уверенно об этом можно будет сказать со временем.
Как получилось
На текущий момент уже разработано несколько микросервисов, которые функционируют в рамках «переходной архитектуры». Например, быстро и легко появился на свет сервис импорта данных на Django. Пока что ощущения самые приятные:
- Быстрый онбординг. Пришёл, увидел, начал кодить.
- Нет нужды в многословии и куче аксоновских классов. Если верить моим оценкам, это уже ускорение разработки в два раза.
- Python вместо Java делает разработку дешевле и еще быстрее. Сервис импорта данных не очень-то большой и высоконагруженный.
- Сборка и тестирование одного микросервиса на порядок (в буквальном смысле) быстрее, чем для «модульного монолита». Соответственно, более быстрый релизный цикл и меньше вынужденного простоя.
Работы по распилу «монолита» тоже ведутся, но пока только подготовительные. Судя по всему, технических проблем быть не должно, однако, когда делаешь операцию на работающем сердце, стоит три раза перестраховаться, чтобы сердце продолжало работать.
Как мы к этому относимся
Разумеется, я не хочу сказать, что AxonIQ — плохой фреймворк, а «монолит» — заведомо неудачное решение. У всякого инструмента своя область применения, и эта область не всегда ясна сразу. Можно увидеть эргономичную рукоятку и решить, что это молоток, а потом спустя пару месяцев обнаружить, что закручиваешь гвозди шуруповертом.
Ошибка, которую мы совершили, — результат сложения двух отдельных ошибок, продуктовой и инженерной. Недостаточно четко сформулированные бизнес-требования подтолкнули инженерную команду к выбору неподходящего технического решения, а инженеры, не имея достаточных знаний о фреймворке, не смогли вовремя распознать «ловушку». Оглядываясь назад, я понимаю, что для стартапа риск и первой, и второй ошибки достаточно велик.
История с AxonIQ стоила нам многих человеко-часов, но также она дала нам ценный опыт. Надеюсь, кто-то из читателей сможет им воспользоваться, не получая его трудным путем.