Масштабируемость (Scalability)
Под масштабируемостью понимается способность инфраструктуры расти и адаптироваться под объемы данных и нагрузки, связанные с различными задачами. Простой пример: представьте, что платежный сервис анализирует миллионы транзакций в час, но во время сезона распродаж нагрузка вырастает в 50 раз. Если система не сможет оперативно задействовать дополнительные ресурсы, пользователи столкнутся с задержками или ошибками.
Есть два подхода к осуществлению этого принципа.
Горизонтальное масштабирование подразумевает применение кластерных решений (Hadoop, Spark, Kafka). Эти технологии используют группы серверов (кластеры) для распределенной обработки, хранения и передачи больших данных. Несмотря на то что каждое из этих решений ориентировано на различные задачи, общая идея заключается в том, чтобы разбить работу на части и выполнять их параллельно на множестве узлов.
Кроме того, для горизонтального масштабирования применяется cloud-native архитектурные решения вместе с облачной инфраструктурой (AWS, Azure, GCP, Kubernetes). Она позволяет автоматически добавлять ресурсы при пиковой активности или перераспределять их в фоновом режиме без остановки сервисов.
Горизонтальное масштабирование требует сложной балансировки и синхронизации между узлами. Это критически необходимо, чтобы избежать перегрузки одних и простоя других. И не менее важно, чтобы информация на всех узлах актуализировалась своевременно и оперативно.
Кроме того, критически важна синхронизация данных: если один узел обрабатывает транзакцию, изменения должны мгновенно отражаться на всех остальных, чтобы предотвратить конфликты и потерю информации. Для этого используются инструменты вроде Kubernetes (оркестрация контейнеров) или Cassandra (распределенные базы данных), которые автоматизируют координацию узлов. Однако даже с ними архитектура усложняется: приходится учитывать сетевые задержки, согласованность данных (CAP-теорема) и отказоустойчивость соединений.
Второй подход, вертикальное масштабирование, заключается в усилении мощности отдельных серверов (то есть производительность системы повышается за счет апгрейда «железа» на уровне одного сервера). Например:
- Использование процессоров с большим числом ядер или переход на архитектуру CPU (центрального процессора) с более высокими частотами ускоряет обработку сложных вычислений.
- Увеличение объема RAM (оперативной памяти) позволяет серверу работать с большими наборами данных без обращения к диску, что критично для баз данных или кеширования.
- Установка SSD вместо HDD, добавление дискового пространства или использование RAID-массивов повышает скорость чтения/записи и надежность хранения.
Стоит отметить, что вертикальное масштабирование эффективно только на ограниченном этапе роста. Идеальная же инфраструктура для Big Data комбинирует оба метода. Например, базовые узлы можно масштабировать вертикально для обработки сложных запросов в реальном времени, а горизонтально — расширять хранилища данных, подключая новые серверы при увеличении объема информации. Важно, чтобы система автоматически перераспределяла нагрузку, используя оркестраторы вроде Kubernetes или встроенные механизмы распределенных баз данных. Только так инфраструктура остается гибкой, экономичной и готовой к неожиданным вызовам.
Как оценить, сколько нужно серверов?
При проектировании архитектуры нужно оценить, как будет использоваться каждый компонент системы и какой ресурс сервера используется компонентом. После оценки можно воспользоваться формулой:
workers = (Rin × C) ÷ (U × N)
Где:
- workers — число серверов;
- Rin — трафик/нагрузка;
- C — количество ресурсов, нужное на обработку одной единицы трафика;
- U — утилизация ресурса (то есть какую часть ресурса мы хотим использовать при нормальной работе);
- N — количество таких ресурсных единиц в одном сервере.
Рассмотрим на примере Apache Kafka, который используется для обмена сообщениями внутри системы. Предположим, что Kafka должен обрабатывать 10 000 сообщений в секунду. В среднем Kafka нужно от 1 до 2 миллисекунд процессорного времени на обработку одного сообщения. Пусть у нас будут серверы с 8-ядерными процессорами. При этом мы хотим иметь небольшой запас мощности на случай внезапного роста нагрузки, поэтому рассчитываем, что при нормальной нагрузке мы не должны загружать процессор на более чем 70%. Получаем:
Rin = 10 000 сообщений/сек
C = 2 мс = 0,002 сек.
U = 70% = 0,7
N = 8 ядер
workers = (10 000 × 0,002) ÷ (0,7 × 8) = 3,57
Лучшие практики работы с Kafka рекомендуют использовать нечетное число серверов в кластере. Именно поэтому в данном случае лучше всего выбрать 5 серверов.
Пример распределения нагрузки на серверы внутри системы с вертикальными и горизонтальными лимитами:

Во время эксплуатации системы важно мониторить соответствующие показатели серверов и при достижении ими определенных порогов (как правило, утилизации ресурса 70%) проводить масштабирование.
Отказоустойчивость и высокая доступность (Fault Tolerance & High Availability)
По сути, это способность системы продолжать работу даже при выходе из строя ее отдельных компонентов, будь то серверы, диски или сетевые узлы. Допустим, крупный маркетплейс использует SaaS-платформу для управления цепочками поставок, в которой данные о заказах синхронизируются между двумя-тремя data-центрами в разных регионах, чтобы избежать простоев. Если один из центров выйдет из строя из-за перегрузки сети, атаки и так далее, система мгновенно переключит трафик на резервные узлы. Клиенты при этом продолжат размещать заказы, отслеживать доставку и получать обновления в реальном времени, не замечая сбоя.
Чтобы обеспечить данный принцип проектирования инфраструктуры для работы с Big Data, используются такие механизмы, как, например, репликация данных. Это включает в себя создание нескольких копий данных в различных дата-центрах или облачных регионах и/или использование распределительных файловых систем (HDFS, Ceph, S3).
Кроме того, необходимо обеспечить возможность автоматического восстановления данных. Этот механизм невозможно реализовать без таких процессов, как мониторинг состояния компонентов (с помощью систем мониторинга и логирования Zabbix, Prometheus, ELK Stack), автоматическое переключение на резервные компоненты (Failover), настройка регулярного бэкапа данных (Backup), проверка процедур восстановления (Restore).
В Big Data-инфраструктуре соблюдение принципа отказоустойчивости и высокой доступности критично: простои могут сорвать обработку данных для прогнозной аналитики, а потеря логов — исказить машинное обучение. Именно поэтому отказоустойчивость и высокая доступность — не опция, а обязательный слой архитектуры при работе с Big Data.
Ниже — опорные цифры (порядок величин), которые обычно закладывают в финансово‑техническую модель. Их достаточно, чтобы «на салфетке» понять, где ROI использования различных дата-центров (DC) становится положительным.
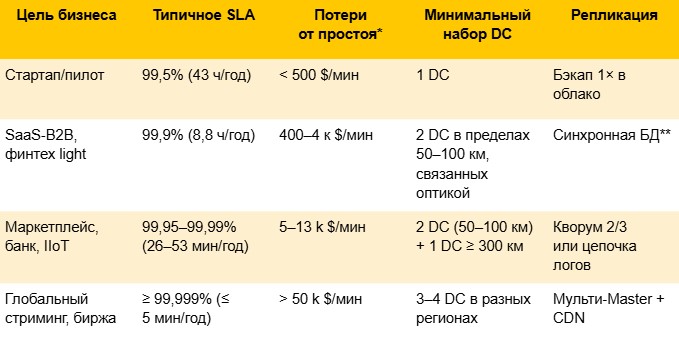
* Средняя стоимость простоя сейчас колеблется от 427 $/мин у малого и среднего бизнеса до 5–13 k $/мин у крупных компаний; каждый год растет на ~ 20%.
** Синхронная репликация практически применима при RTT ≤ 2–4 мс, что соответствует ≈ 100 км оптики; дальше переходят на асинхронную схему.
Производительность и оптимизация (Performance & Optimization)
Еще один ключевой принцип проектирования надежной инфраструктуры для работы с Big Data — это способность обрабатывать и анализировать данные с минимальными задержками, даже при экстремальных нагрузках. Например, компания, управляющая парком из тысяч грузовиков, ежедневно обрабатывает огромное количество данных: GPS-треки, состояние транспорта, погодные условия, заказы клиентов. Чтобы оптимизировать маршруты в реальном времени и снизить расход топлива, система должна за секунды анализировать все данные и перестраивать пути с учетом пробок, поломок или срочных заказов.
Для достижения высокой скорости используются:
- Разделение вычислений и хранения, то есть использование отдельной инфраструктуры для хранения данных (Object Storage, Data Lake) и для их обработки (Computer Clusters).
- In-Memory технологии (Spark, Redis, Apache Ignite, Memcached) для ускорения обработки данных в оперативной памяти.
- Оптимизация сетевой инфраструктуры — высокоскоростные сети (10Gbps+) и минимизация задержек и коллизий данных.
Нужно понимать, что оптимизация — это не разовая настройка, а постоянный процесс. Анализ «узких мест» через мониторинг, очистка «мусорных» запросов и балансировка нагрузки между узлами превращают инфраструктуру в слаженный механизм. В итоге бизнес получает не просто скорость, а возможность мгновенно реагировать на изменения: предсказывать спрос, выявлять аномалии в реальном времени или адаптировать ИИ-алгоритмы под новые данные без простоев.
Безопасность (Security)
Защита данных и инфраструктуры от несанкционированного доступа, повреждений или утечек не менее критична, чем остальные принципы работы с Big Data. Только представьте, какими могут быть для бизнеса последствия успешной кибератаки, если компания годами собирала и хранила данные клиентов, аналитику рынка и другую информацию: гигантские штрафы, судебные разбирательства и испорченная репутация.
Так как же реализовать безопасность инфраструктуры для работы с большими данными? Защита складывается из нескольких компонентов:
- Контроль доступа и идентификация осуществляются с помощью управления доступом на основе ролей (RBAC, Role-Based Access Control) и IAM-сервисов облачных платформ, которые через идентификацию, аутентификацию и авторизацию открывают пользователю доступ к цифровым инструментам или оборудованию.
- Шифрование данных как при хранении (Data-at-rest), так и при передаче (Data-in-transit). Могут быть использованы такие технологии, как TLS/SSL, AES-шифрование, KMS (Key Management Service).
- Аудит и мониторинг, требующий журналирования действий пользователей и систем, позволяет выявлять различные инциденты, а для своевременного реагирования на подозрительные события применяется система оповещения (SIEM).
К сожалению, как правило, вопрос обеспечения безопасности остается недооцененным, несмотря на очевидную важность. Особенно сегодня, когда количество хакерских атак растет, а риски, связанные с потерей данных, становятся всё более серьезными: согласно ЭАЦ InfoWatch, в 2024 году в мире было зарегистрировано 9175 утечек.
Чтобы понять, когда оправдано внедрять RBAC/IAM, собственные KMS‑ключи, аппаратные HSM, «толстую» SIEM‑платформу и так далее, полезно считать не только цену лицензий, но и:
- Риск = Вероятность × Средний ущерб инцидента.
- Нагрузку (объем данных, число операций шифрования, GB логов/сутки, число пользователей).
- Срок хранения и регуляторный класс (GDPR/PCI‑DSS/HIPAA — «красная зона»).
В отчете Cost of a Data Breach Report 2023 указано, что одна строчка персональных данных (ПДн) при утечке обходится компаниям примерно в 183 $.
Как быстро прикинуть бюджет
1. Классифицируйте данные (от A — открытые до D — строгая регуляция).
2. Замерьте суточный объем логов:
- Hadoop/Spark ≈ 1–3% от входного потока.
- Kubernetes audit ≈ 0,5 GB на 1000 pods.
3. Посчитайте операции KMS: Encrypt + Decrypt ≈ (Число файлов × Периодичность чтения).
Ущерб = Всего строк ПДн × 183 $
Затраты = (Объем логов × Стоимость хранения) + (Операции KMS × Стоимость операции) + (Цена IAM × Число администраторов)
Если Ущерб × Вероятность > 2 × Затраты, внедряем!

Что обязательно учесть при проектировании:
- Рост данных — бюджетируйте +20–30% емкости KMS‑операций и лога ежегодно.
- SLA на время простоя (RTO/RPO) — аппаратные HSM ускоряют восстановление ключей.
- Локации — GDPR запрещает хранить EU‑PII вне ЕС без дополнительных механизмов.
- DevOps‑процессы — динамические кластеры стремительно наращивают число API‑запросов к KMS и объем audit‑логов.
Надежная инфраструктура для Big Data базируется на балансе этих четырех основных принципов. Однако это не значит, что существует универсальное решение, которое обеспечит стабильность и эффективность любой системы, работающей с большими данными: выбор инструментов зависит от многих факторов, например от типа данных, SLA и бюджета. И всё же единое правило для всех компаний есть: при проектировании инфраструктуры важно закладывать запас на рост решения и усиление безопасности, ведь объем данных, как и количество угроз, в будущем будет только расти.