У меня был большой опыт работы на проектах, связанных с критической инфраструктурой, где падение было недопустимо. Это не сайты с шортсами, которые могут позволить себе «полежать», а госпроекты, которые должны стабильно работать даже под постоянной стрессовой нагрузкой. Если случалось что-то экстраординарное, то мы должны были об этом узнать раньше всех.
Такие требования и сформировали мое мировоззрение в области мониторинга. Я обеспечивал инфраструктуру и в качестве разработчика, и в качестве руководителя службы второй линии поддержки. К тому же я окончил Московский авиационный институт. Там учат авиации, где тоже нет права на ошибку. В общем, как видите, я парень, замороченный на теме мониторинга.
Из чего складывается мониторинг?
Мониторинг — не явный процесс. Мы вспоминаем о нем, когда что-то идет не так. Если происходит сбой, мы сразу спрашиваем: «А где был мониторинг? Почему не среагировали?»
Скажем, есть админы, которые делают бэкапы, а есть те, кто «забивает» на этот процесс. Пока гром не грянет, вроде бы эти админы ничем друг о друга не отличаются. Но как только происходит ЧП, мы понимаем, кого нужно было увольнять. С мониторингом так же: пока система не подвела, пока какой-нибудь интернет-магазин не потерял десятки миллионов рублей, о мониторинге как будто бы можно не думать. И это огромное заблуждение.
Другая популярная ошибка — когда при создании проекта пишут ТЗ с основными этапами: разработать и протестировать проект, а потом запустить. Вот между «протестировать» и «запустить» должна быть постановка проекта на мониторинг. Более того, у вас должно быть конкретно прописано, что вы будете мониторить. И без решения этой задачи нельзя приступать к следующему бизнес-процессу.
Для оценки мониторинга используют такую метрику, как аптайм — это вероятность с конкретной процентовкой того, сколько времени сервис будет доступен. Допустим, сервис-провайдер гарантирует, что сервер будет доступен с аптаймом 99,99. Это значит, провайдер подписывается под тем, что сбой допустим в общей сложности на один час в год. К этой метрике можно свести всё понятие мониторинга.
Что обязательно надо мониторить и как настроить алерты?
URL, веб-адрес проекта
Самый базовый уровень мониторинга — проверка на доступность по URL вашего проекта. Если у вас нет системы, которая автоматически запрашивает по адресу главную страницу сайта, API мобильного приложения, у вас, по сути, нет мониторинга.
Запустите простейшую бинарную проверку: есть ответ 200 или нет. Внедрить это можно за день. Сделайте этот первый шаг, и у вас уже появится зачаток мониторинга.
Контроль места на диске
Бывают такие случаи, что проект запущен, всё вроде отлично, а потом — бах! — логи сожрали всё место. Классика жанра.
Один раз мы мониторили сервис для проведения промоакций. Мы прогнозировали, что на сервисе будет определенное количество загрузок, активаций, столько-то загруженных фотографий пользователей. Но мы просчитались. Когда число загрузок перевалило за миллион, мы поняли, что места на диске не хватит. Но мы подстелили соломку: поставили алерт на ситуацию, когда на диске окажется меньше 20% свободного места. Получив алерт, мы добавили новый диск, и никто не заметил каких-либо проблем.
Если бы мы не настроили алерт, то после переполнения диска система встала бы на 2–3 часа — пострадал бы бизнес.
Проверка сервера на ресурсы
Контроль памяти, ЦП — то, что является показателем нагрузки. Скажем, у вас на сервере есть сайт, где проходит голосование на звание «Лучший комик года». Туда могут зайти два человека или 500 посетителей, и проблем не возникнет. Но если зайдут пять тысяч, то всё дружно может упасть. А этот мониторинг обеспечивает контроль показаний самого сервера.
SSL-сертификаты
Срок действия этих сертификатов может подойти к концу, и пользователь просто увидит «Ваше соединение не защищено». Мало кто из пользователей будет искать скрытую кнопку «Все равно открыть сайт», большинство просто закроет страницу и уйдет. Годность SSL-сертификатов надо регулярно проверять.
Ошибки внутри браузера (на стороне JavaScript)
Мы много обсуждаем бэкенд, когда ставим задачи по мониторингу, но часто забываем про фронтенд, а ведь именно на этой стороне происходит много бизнес-логики.
Веб уже давно стал сложнее, чем HTML-страница с JS-скриптом на 100 строк, ведь нужно выполнять валидацию форм, анимацию интерфейсов, отправлять данные на сервер. Буквально на каждой кнопке сложного интерфейса что-то может пойти не так. Самое примечательное, что до сервера, где сосредоточены основные силы мониторинга, информация об ошибке попросту может не дойти. Очевидно, нужно контролировать и мониторить выполнение JavaScript в браузере.
Мы мониторим события JavaScript с помощью сервиса Sentry. Достойной замены пока не нашли.
Мониторинг бизнес-точек
Это мониторинг, который обеспечивает проверку выполнения бизнес-функции вашего проекта.
Бывает так, что сам сайт или приложение как будто бы окей, но, если мы попытаемся совершить какое-то действие, например заказать пиццу в приложении для доставки, то у нас ничего не получится. Под нагрузкой сервис не справляется. Поэтому нам нужен мониторинг конкретных бизнес-метрик.
Другой пример — у вас формируются отчеты по выгрузке товаров с маркетплейса. Тогда вы настраиваете систему таким образом, чтобы получать алерт, если у вас нет папки сформированных отчетов с файлами за сегодня. Отчет может не сформироваться по множественным причинам — например, потому что лежит FTP-сервер или база данных. В результате вы будете уверены, что сервис работает, делает это под нагрузкой и реально выполняет свою функцию.
Чтобы мониторить бизнес-функционал, мы создаем специальный handler в коде. Если он ловит ошибки при выполнении программы, мы получаем информацию об этом в Телеграм. Это более глубокий мониторинг на уровне выполнения программы.
При настройке алертов анализируйте бизнес-процессы конкретного клиента. Скажем, есть нормальное значение для сервиса проведения конкурса — 300 загрузок в час. Но вдруг этот показатель падает до 10. На первый взгляд это неуловимое событие. Вроде система работает, но что-то идет не так. Если поставить алерт на подобную аномалию, то можно будет отловить какой-то баг: отвалился микросервис или недоступен другой элемент.
Главный лайфхак по настройке алертов к определенному сервису — задать вопрос: «А что для нас страшная ситуация?»
Допустим, вы ответили, что страшная ситуация — это когда пользователь загружает чеки, а в базу они не записываются. Тогда создайте именно такую метрику для мониторинга. Или, как в примере выше, алерт, если при норме в 300 загрузок этот параметр падает ниже 10.
Так как большинство наших проектов написаны на стеке Java, мы используем дружественный языку стек технологий Elastic Logstash Kibana (ELK).
Особенности мониторинга в эпоху санкций
Сейчас некоторые системы и сервисы заблокированы на территории РФ. Случаются и совсем экстраординарные случаи. Однажды провайдер на уровне инфраструктуры перестроил топологию своей сети, и в этот момент наш сервис просто стал недоступен.
Вам нужно уметь отслеживать проблемы доступности сервиса для разных регионов. И для этого вы должны всегда иметь точку мониторинга вне вашей инфраструктуры.
Для решения этой проблемы на одном из наших проектов, к примеру, мы развернули отдельную виртуальную машину в Италии. А если бы у нас был только централизованный мониторинг — внутри системы, — о падении серверов с проектом мы просто не узнали бы.
Как мы мониторим закрытые системы
Корпоративная IT-инфраструктура — это, как правило, закрытый для доступа извне парк виртуальных и физических серверов. Подключиться к ней можно только через корпоративный VPN-шлюз.
Учитывайте этот момент и, составляя контракт на поддержку проекта для корпоративного заказчика, отдельно обсуждайте алгоритм мониторинга.
Существует несколько вариантов. Первый — вы можете развернуть подсистему мониторинга непосредственно в контуре заказчика. Другой вариант — можно выступить в качестве второй линии поддержки. В этом случае, конечно, проактивный мониторинг вы не сможете обеспечить, но будете работать по тикетам.
Мы в своей практике сочетаем оба подхода. Небольшие системы мониторим самостоятельно. На крупных проектах настраиваем подсистемы мониторинга и передаем непосредственную функцию управления процессом in-house команде, а сами выступаем второй и третьей линией технической поддержки.
Наша эволюция: почему нам не нужен слон в посудной лавке
Выбирая инструменты мониторинга, мы прошли несколько этапов.
Конечно, первая ступень — ручной мониторинг. Программист утром заходит на ваш ресурс. Звучит банально, но с такого мониторинга начинают все.
Но когда у вас уже не один простенький сайт, а десять проектов, то для их контроля нужно что-то большее. Мы попробовали такую мощную платформу, как Zabbix. Это сильный инструмент, он применим в сложных ситуациях: геораспределенные инфраструктуры, федеральные сети провайдеров.
Настройка Zabbix занимает немало времени. И постепенно мы поняли, что для нас он как слон в посудной лавке. Не всегда для решения проблем мониторинга нужен такой мастодонт.
Тогда мы прошли по пути упрощения и обратили внимание на зарубежный сервис UptimeRobot.
Проект позволял нам мониторить по URL, отправлял алерты в мессенджеры, пуши на телефон, в приложение и на почту. Но потом мы поняли, что вырастаем из этого инструмента.
Затем мы обратились к серверному open-source решению Uptime Kuma. Такое решение подходит тем, у кого не микросервисная архитектура, а монолит. Это может быть небольшой портал или мобильное приложение. И все это помещается максимум на 2–3 серверах.
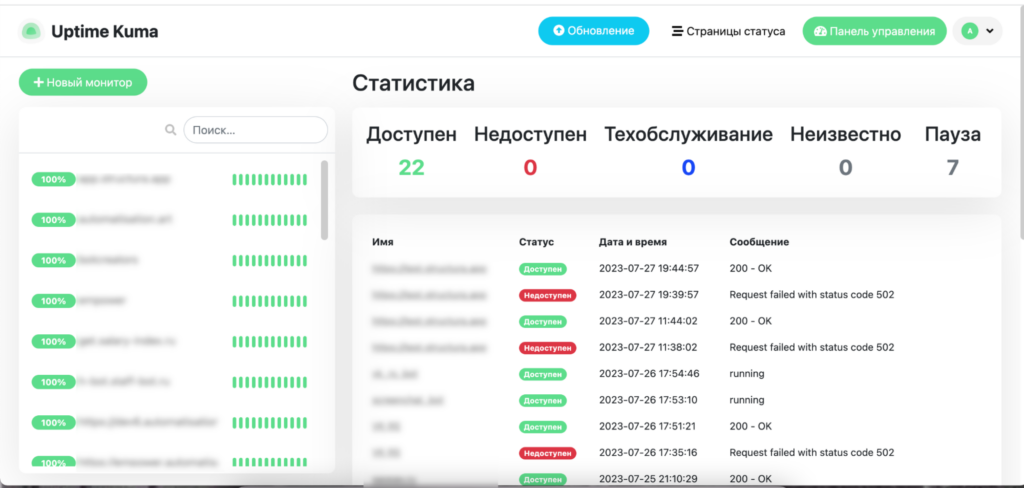
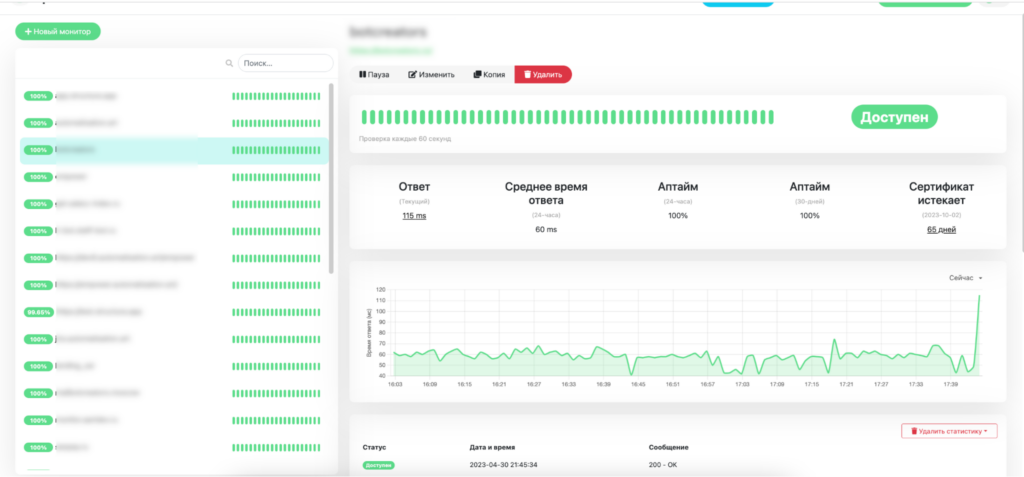
Дополнительно мы написали телеграм-бот, который раз в час проверяет, не заканчивается ли место на диске, и отправляет алерты, если мы вышли за пределы.
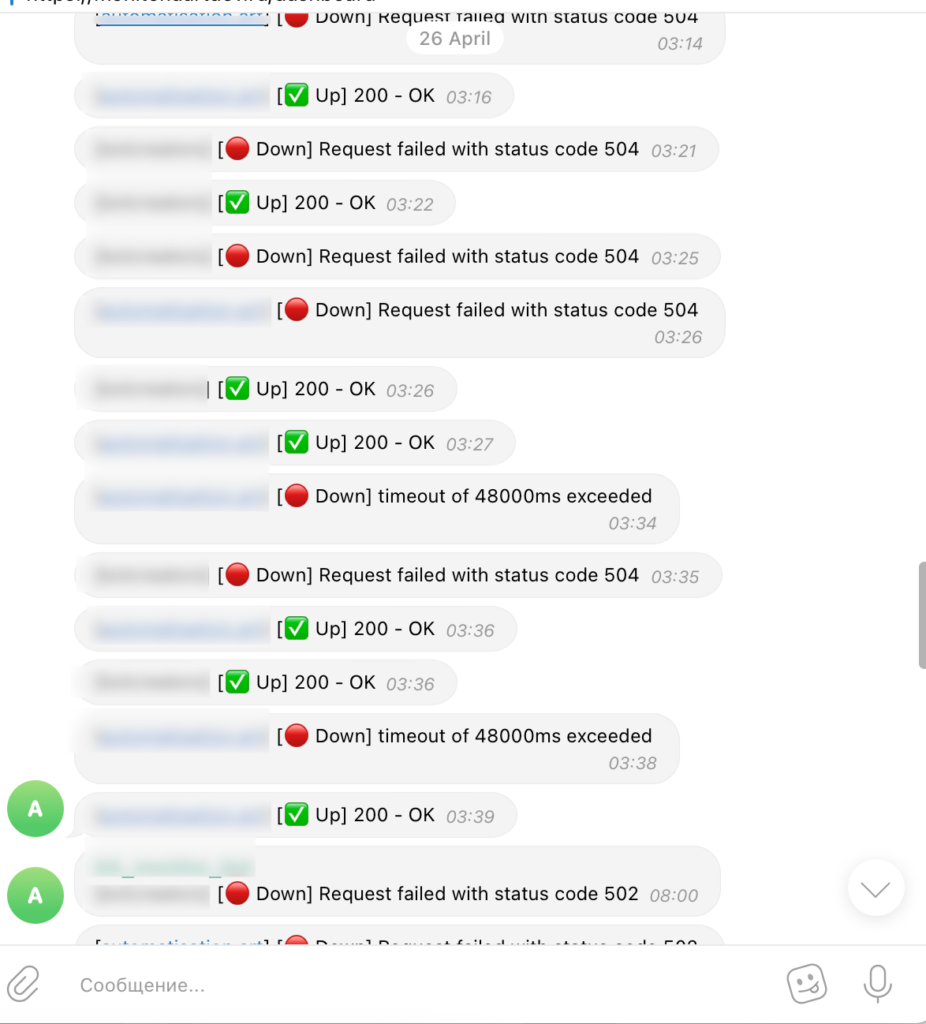
Для логирования событий на фронтенде мы используем инструмент Sentry. Для быстрого поиска по логам — Kibana. Для регулярных задач по мониторингу используем Bitrix. На каждый проект после релиза автоматически создается регулярная задача: каждую неделю зайти в Kibana или Sentry и посмотреть, какие были ошибки, проанализировать их.
Заключение
Процесс мониторинга не уступает по важности процессу разработки и тестирования, хотя про него часто забывают.
Если вы задумались о внедрении процесса мониторинга для вашего IT-проекта, используйте этот чек-лист для быстрого старта:
✅ Есть мониторинг доступности внешних точек системы (статус 200).
✅ Есть контроль места на диске.
✅ Настроен алерт в Телеграм или на почту для ситуации, если диск заполнен на 80%.
✅ Есть мониторинг загрузки оперативной памяти и ресурсов процессора.
✅ Срок действия SSL-сертификатов проверяется автоматически.
✅ Есть мониторинг ошибки на стороне фронтенда и бэкенда.
✅ Есть регулярная задача по изучению логов и ошибок.
✅ Есть резервная система мониторинга, расположенная вне целевой инфраструктуры.
✅ Есть бизнес-алерты на случай, если ПО не выполняет бизнес-задачи.
Всем аптайма 99,(9)!